0. 목차
- 컴퓨터가 작동하는 방법
- 인공지능은 어떻게 학습하는가?
- 인공지능의 미래
- 아실로마 AI 원칙
- 인공 지능의 4가지 레벨

1. 컴퓨터가 작동하는 방법
컴퓨터 안에는 '프로그램(Program)'이 많이 들어있다. 인간이 키보드나 마우스를 통해 컴퓨터에 입력을 하면, 컴퓨터는 프로그램으로 계산을 해서 답을 출력한다. 프로그램은 컴퓨터 언어로 만들어져 있다. 따라서 컴퓨터 언어로 나타낼 수 없는 것을 컴퓨터에 시킬 수는 없다. 하지만 프로그램된 것이라면 매우 빠른 속도로 정보를 처리할 수 있다.
인간이라면 한 번에 풀 수 있는 문제도 컴퓨터는 정해진 프로그램에 따라 계산해야 풀 수 있다. 아래의 그림은 '서로 다른 3개의 숫자 가운데 가장 큰 것을 고르라'는 문제를 프로그램을 통해 컴퓨터가 어떻게 푸는지 예시를 나타낸 것이다.
1-1. 컴퓨터는 '개념'을 이해하기 어렵다.
컴퓨터는 정보를 그대로 외우는 것은 잘한다. 하지만 무언가를 '이해'하고 그것에 대해 '판단(Judgment)'하는 것은 어려워한다. 컴퓨터는 풍부한 정보를 기억하고 프로그램에 따라 계산하는 능력은 매우 강력하다. 하지만 이것만으로는 인공 지능이 매우 똑똑하다고 말할 수 없다. 예컨대, 컴퓨터가 두 문장의 내용이 비슷한가를 판단하는 과정은 간단하지 않다. 왜냐하면 두 문장에서 나오는 낱말이 전혀 다르기 때문이다. 낱말과 낱말을 단순 비교하면, 컴퓨터는 두 문장이 '일치하지 않는다'라고 판단할 것이다.
그러면, 컴퓨터는 두 문장이 비슷한지를 어떻게 판단할까? 컴퓨터는 먼저 문장을 낱말별로 나눈다. 그 후 낱말이 다른 낱말과 어떤 관계에 있는지를 사전 등의 수많은 문장 데이터를 참조해 판단한다. 이러한 말끼리의 관계에 의해 컴퓨터는 '의미'를 계산해 나간다. 이러한 과정을 통해 컴퓨터는 두 문장이 아주 비슷하다고 판단할 수 있다.
컴퓨터에게 더 어려운 일은 '개념(Concept)'을 이해하는 것이다. 컴퓨터 안에는 강아지와 고양이에 대한 정보가 많이 축적되어 있지만, 그림과 완벽히 일치하는 데이터는 들어 있지 않다. 그래서 컴퓨터는 '강아지'를 '머핀'으로 인식할 수 있다. 강아지란 개념은 '강', '아', '지'라는 글자의 나열이 아니라 여러 가지 이미지를 포함한 개념이다.
2. 인공 지능은 어떻게 학습하는가?
최근 '인공 지능(AI: Aritificial intelligence)'은 놀랄 만큼 빠른 속도로 발전하고 있다. 특히 2016년 3월에는 바둑에 특화된 인공 지능인 구글의 '알파고(AlphaGo)'가 이세돌을 이겨 사람들에게 충격을 주었다. 참고로 바둑의 경우의 수는 우주에 존재하는 모든 원자의 수보다 많기 때문에, 직관을 필요로 하는 바둑 분야에서는 인공지능이 인간을 이길 수 없다고 주장하는 전문가들이 많았었다. 그러면 어떻게 이런 일이 가능한 걸까? 이를 이해하기 위해 인공 지능이 어떻게 학습하는지 알아보자.
2-1. 인공 지능이 인식하는 방법
예컨대 우리의 눈앞에 강아지가 있다고 하자. 우리의 뇌에서는 강아지에게 '귀여운 눈, 코, 입이 있다', '털이 있다' 등의 '특징'을 무의식적으로 추출하고 이것들을 통합함으로써 '강아지'라고 인식한다. 우리의 뇌 속에 강아지의 '개념'을 가지고 있기 때문이다.
그러면 컴퓨터는 어떨까? '영상 인식'을 예로 그 흐름을 살펴보자. 컴퓨터는 먼저 강아지의 영상을 매우 작은 '화소(Pixel)'로 나누고, 그 화소를 '위치 정보'와 '색깔 정보'를 가진 수치로 다룬다. 강아지의 영상도 컴퓨터 안에서는 단지 숫자의 나열일 뿐이다. 인공 지능은 어떤 특별한 시스템에 의해 이 숫자의 나열에 대해 풍부한 계산을 해서 강아지의 특징을 추출한다. 과거에는 강아지의 특징을 인간이 직접 입력해 줘야 했다. 하지만 '딥러닝'을 통해 그것을 컴퓨터 스스로가 할 수 있게 되었다. 즉, 컴퓨터가 '개념(Concept)'을 스스로의 힘으로 얻을 수 있게 된 것이다.

2-2. 뇌의 정보 처리 방법
사실 '딥러닝'은 인간의 뇌 구조를 모방해 만든 것이다. '딥러닝'을 이해하기 위해 우리가 강아지를 인식할 때 뇌에서 무슨 일이 일어나고 있는지 살펴보자.
먼저 눈에 들어온 빛 정보는 눈 안쪽에 있는 '망막'에 투영된다. 이 정보는 뇌 뒤쪽에 있는 '1차 시각 영역'의 시각 세포에 전해진다. '1차 시각 영역'에 있는 신경 세포는 매우 좁은 범위에 있는 시각 신경에서만 정보를 받아들이기 때문에, 세로 막대나 가로 막대 등의 단순한 형태밖에 '판단'할 수 없다. 이어 정보가 '2차 시각 영역'에 이르면, 윤곽을 구성하는 선분끼리 매끄럽게 이어 커브가 있는 곡선 등으로 통합되어 간다. 이런 식으로 '1차 시각 영역'의 단순한 정보는 순차적으로 '2차 시각 영역', '3차 시각 영역', '4차 시각 영역', 'TE 영역'으로 보내짐에 따라 통합되면서 서서히 복잡한 형태를 판단할 수 있게 된다. 그리고 최종적으로, 강아지 같은 모양에 반응하는 세포가 활성화된다. 그 결과, 우리는 강아지를 인식할 수 있게 된다.

2-3. 시냅스(Synapse)
시각 정보는 전기 신호가 신경 세포에 흐름으로써 전단된다. 신경 세포는 직접 연결되어 있는 것은 아니고 '시냅스(Synapse)'라는 구조에서 화학물질을 주고받음으로써 다음 신경 세포로 정보가 전달된다. 시냅스는 단순히 신경 세포끼리 정보를 전달하는 역할만 하는 것은 아니다. 시냅스는 정보의 '중요도 평가'라는 역할도 맡고 있다. '시냅스의 크기(결합 강도)'가 변화함으로써 정보를 어느 정도로 다음 신경 세포로 전달할지를 결정한다. 같은 것을 되풀이해 학습하면 같은 시냅스에 몇 번이나 신호가 보내짐으로써 시냅스가 커진다. 이런 과정을 거치면서 신호를 효율적으로 받아들이게 된다. 한편 거의 들어오지 않는 시냅스는 서서히 작아지다가 사라진다. 이런 메커니즘에 의해 '학습'에 의해 뇌에서는 '시냅스의 크기(결합 강도)'가 커지거나 작아진다.
예컨대 어린이가 강아지를 봤을 때, 어른에게 '이것은 강아지예요?'라고 여러 번 묻는다고 하자. 그러면 어른은 '맞다', '아니다'라고 알려줄 것이다. 그 결과, 강아지를 봤을 때 반응하는 회로가 뇌에서 만들어진다. 어린이가 '강아지'라는 '개념'을 얻게 된 것이다.
2-4. 기계 학습(Machine Learning)
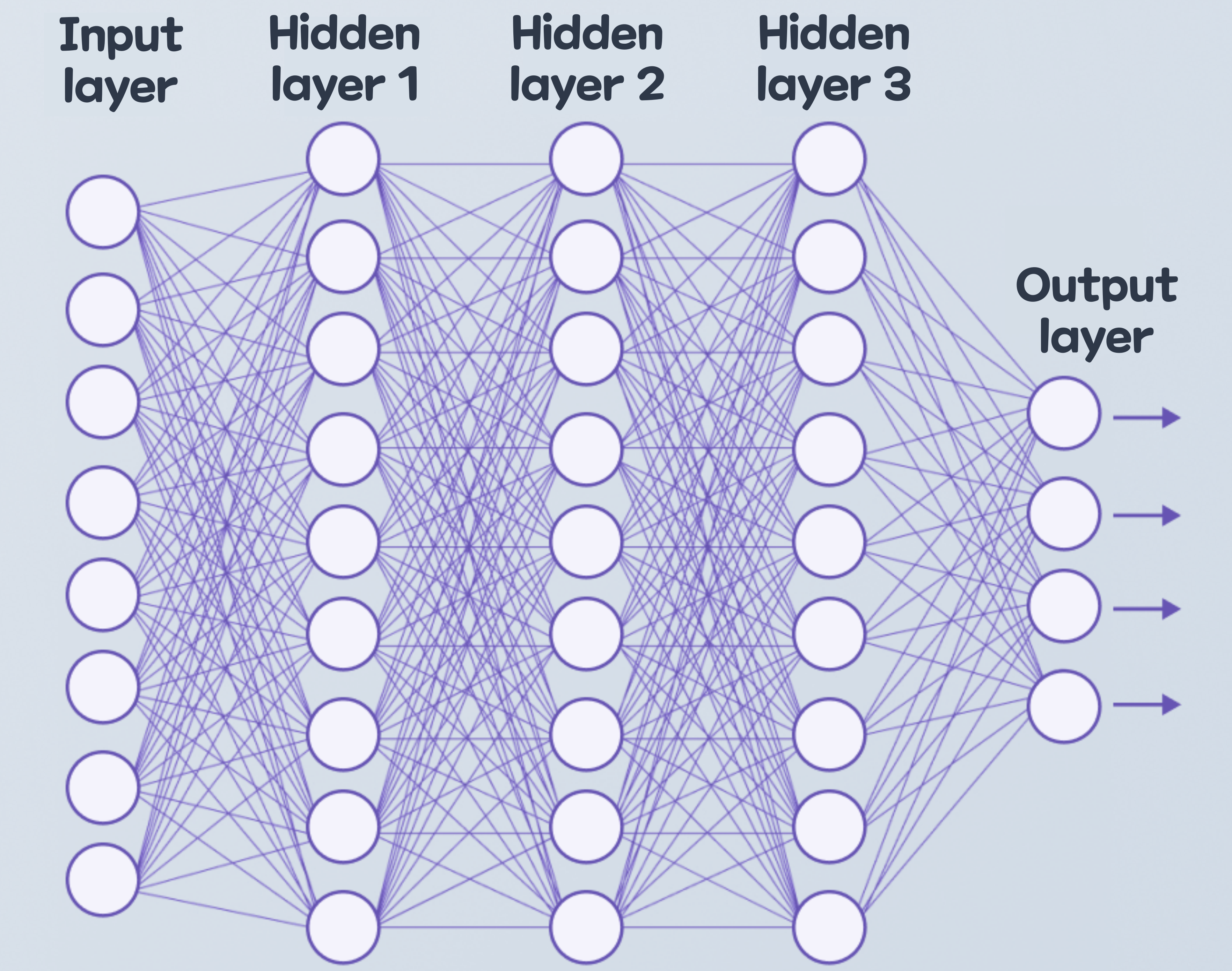
'기계 학습(Machine Learning)'은 인공 지능에 시행착오를 반복시켜 올바른 결과가 '중요도 평가'를 의미하는 '노드와 노드의 연결(node to node connection)'을 서서히 변화시키는 것을 말한다. 즉, '기계 학습'이란 인공 지능이 시행착오를 되풀이하면서 회로를 서서히 바꾸어, 최적의 회로를 찾아나가는 학습 방법이다. '딥러닝(Deep Learning)'은 '기계 학습'의 일종으로, 뇌를 모방한 시스템이다.
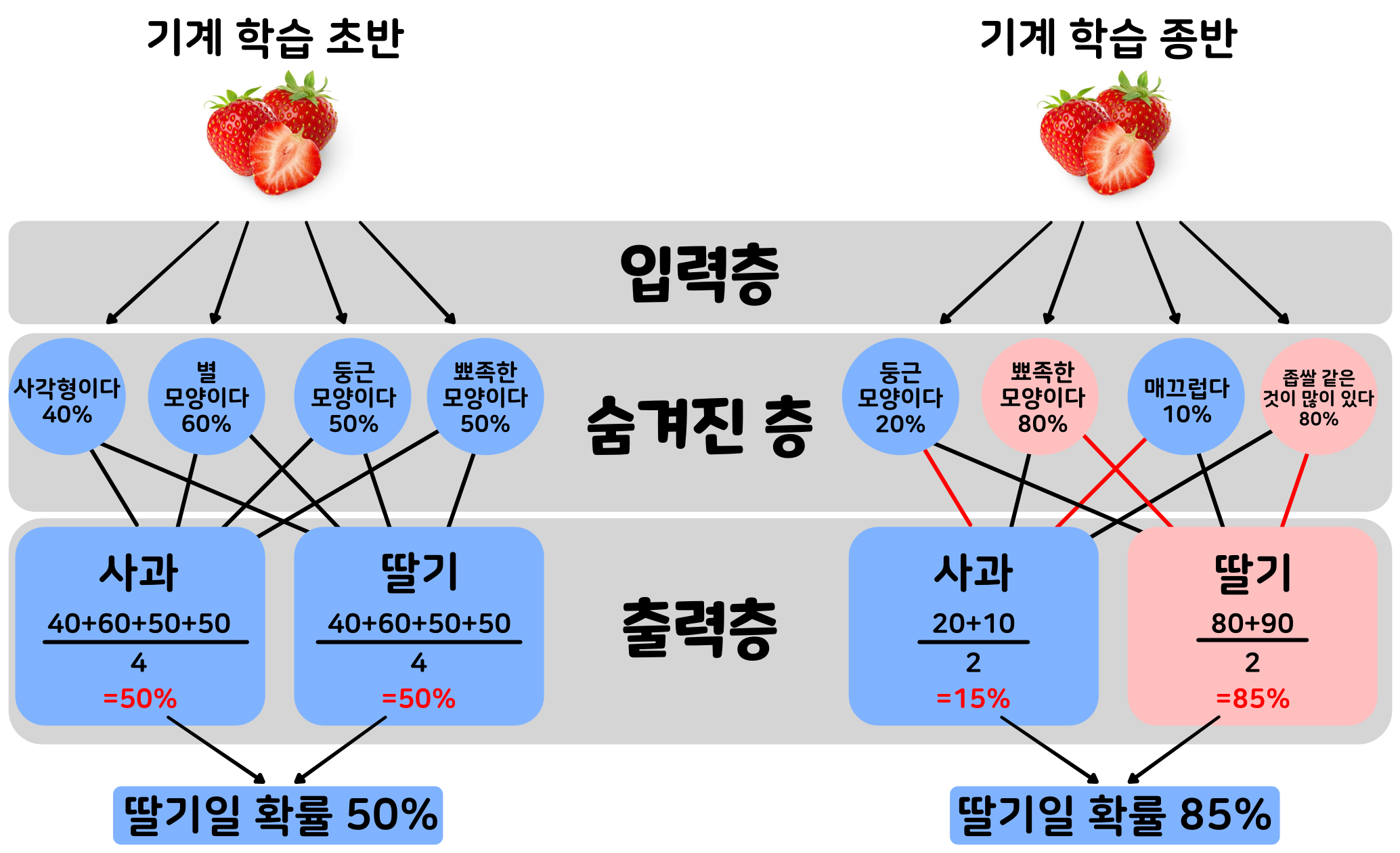
예컨대, 인공 지능이 딸기와 사과를 분류하는 학습을 한다고 하자. 학습 전의 인공 지능은 모든 중요도 평가가 임의의 값으로 되어 있으며, 영상의 어디에 주목할지도 알려져 있지 않다. 즉, 딸기와 사과의 특징이 무엇인지 모른다. 인공 지능이 만약 딸기 영상을 입력했는데 사과라고 판단한다면, 이것은 '중요도 평가'와 '특징의 추출 방법'이 잘못되었음을 의미한다. 그래서 인공 지능은 출력층 쪽에서 입력층 쪽으로 숨겨진 층의 중요도 평가를 바꾸고, 올바른 답을 이끌어내도록 스스로 조정한다. 학습을 수없이 되풀이하여 연습하다 보면, 기계 학습의 초기에는 딸기 영상을 올바로 인식하지 못하던 인공 지능이 서서히 올바른 답을 이끌어내게 된다.
'딥러닝'은 수년 동안 실용적으로 쓸 수 있을 만큼 정확도가 나오지 않는다는 문제를 가지고 있었다. 그 이유는 층이 깊어짐에 따라, 답 맞히기의 영향이 숨겨진 층에 제대로 전해지지 않아, 중요도 평가를 최적화할 수 없었기 때문이다. 하지만 최근 답 맞히기 방법을 개량하거나 본격적인 기계 학습을 하기 전에 인공 지능을 '사전 훈련'시킴으로써 아주 효율적으로 학습시킬 수 있게 되었다. 또 인공 지능이 하는 계산에 특화된 '중앙 처리 장치(Central Processing Unit)'의 개발이 이루어지는 등도 인공 지능의 성능이 극적으로 향상되고 있는 큰 요인이다.
3. 인공 지능의 미래
3-1. 인공 지능이 가지게 될 능력
그러면 앞으로 인공 지능은 어떤 능력을 가지게 될까? 대략적인 예측은 다음과 같다. 현재 영상에 찍혀 있는 것을 구분하는 능력은 이미 인간에게 뒤지지 않는 정확도에 이르렀다. 다음에 인공 지능이 갖게 될 능력은 '복수의 감각 데이터'를 사용해 특징을 파악하는 일이 될 것이다. 시각 정보뿐만 아니라 온도나 소리 등 복수의 감각 정보를 사용해 개념을 만들게 되는 것이다. 그다음에는 '동작에 관한 개념'을 갖게 될 것이다. 이렇게 돼서 로봇이 실제 세계에서 여러 경험을 쌓아가다 보면, 행동을 통한 추상적인 개념을 갖게 될 것이다. 이후에는 말을 이해하게 될 것이다. 말을 이해하게 되면, 인공 지능은 인터넷의 정보 등을 통해 '지식과 상식'을 가질 수 있게 된다.
- 영상을 보고 정확하게 구분하고 판단한다.
- 복수의 감각 데이터를 사용해 특징을 파악한다.
- 동작에 관한 개념을 갖게 된다.
- 행동을 통한 추상적인 개념을 갖게 된다.
- 말을 이해하게 된다.
- 지식과 상식을 갖게 된다.
인공 지능이 이렇게 새로운 능력을 가지게 될 때마다 인공 지능이 활약하게 될 영역도 넓어질 것으로 생각된다. 특히 '동작에 관한 개념'은 로봇이 인간 사회에서 살아가기 위해 꼭 필요한 능력이다.
3-2. '뇌'를 모방한다.
요즘 인공 지능 개발은 눈부신 속도로 이루어지고 있지만, 현재의 인공 지능에는 한계가 있다. 그것은 특정 분야에서 높은 능력을 발휘해도, 그 이외의 분야에서는 응용이 되지 않는다는 점이다. 현재는 특정 문제에 따라 인간이 모듈을 조합시켜서 인공 지능을 설계하고 있는데, 이런 구조는 특정한 문제밖에 풀 수 없는 설계이다.
그래서 인간의 뇌 전체 구조를 모방한 차세대 인공 지능을 만들려는 연구들이 진행되고 있다. 뇌 전체 구조를 모방하면, 하나의 분야에 특화된 것이 아니라 여러 분야의 일을 배울 수 있는 '범용 인공 지능(AGI: Artificial General Intelligence)'이 가능해질 것으로 생각된다. 뇌처럼 필요에 따라 복수의 모듈을 자동적으로 조합시킬 수 있게 되면, 자신의 설계 프로그램을 바꿈으로써 여러 문제를 유연하게 해결할 수 있을 것이다. 현재의 개발 상항으로 미루어 볼 때, 인간과 같은 정도의 능력을 가진 '범용 인공 지능'은 2030년 무렵에 완성될 것 같다.
3-4. 노동의 강도가 약해진다.
인공 지능이 스스로 가설을 세우고 스스로 실험을 하고 결과를 확인하는 작업을 쌓아 나가다 보면, 스스로 진화하여 '지능 폭발(Intelligence Explosion)'을 일으킬지도 모른다. 인공 지능이 기하급수적인 속도로 진화하면, 결국 인간의 지능을 추월할 것이다. 미래학자 '레이 커즈와일(Ray kurzweil)'이 정의한 '기술적 특이점(Technological Singularity)'의 정의는 '비생물학적 지능의 총합이 생물학적 지능의 총합을 넘어서는 시점'이다. '레이 커즈와일'은 2029년에 모든 분야에서 인공 지능이 인간의 지능을 넘어서고, 2045년에는 '기술적 특이점'이 온다고 예측한다.
인공 지능이 더욱 진화하면, 지금보다 훨씬 더 다양한 분야에서 인간의 노동을 돕는 인공 지능이 등장할 것이다. 운전, 가사, 간호, 회계, 창작, 신약 개발 등 수많은 분야에서 인간의 노동 부담을 덜어줄 것으로 생각된다. 또 인공 지능은 오랫동안 해결할 수 없었던 과학의 어려운 문제의 해결에도 답을 줄 수 있을 것으로 기대된다. 예를 들어, 물리학에서 오랫동안 해결되지 않았던, '모든 것의 이론(ToE: Theory Of Everything)'을 이끌어내는데 성공하게 될지도 모른다.
인공 지능이 인간의 일을 돕다 보면, 인간의 일을 점점 대체해나가고 빼앗을 것이다. 어쩌면 인공 지능에게 빼앗기지 않는 일은 하나도 없을지도 모른다는 의견까지 나오고 있다. 지금까지의 기술은 인간의 노동력만을 대체해온 것이었지만, 인공 지능의 발전은 인간의 생각 자체도 대체하는 것이기 때문에, 기존의 기술 발전과는 아주 다른 것이다.
4. 아실로마 AI 원칙
인공 지능은 인류 문명을 이끌어가는데 커다란 도움이 되지만, 여러 위험성도 안고 있다. 하지만 인공 지능의 개발을 멈추는 것은 불가능하다.
그래서 인공 지능을 인류 전체의 행복과 결합시키기 위해 2017년 1월, 미국 캘리포니아주의 아실로마에서는 인공 지능 연구자가 모여 회의 'Beneficial AI 2017'가 열렸다. 그리고 인공 지능을 개발할 때 지켜야 할 '아실로마 AI 원칙(Asilomar AI Principles)'을 발표했다. 이 23개의 원칙은 법적 강제성은 없지만, 그 취지에 찬성에 전 세계 3000명 이상의 인공 지능 연구자와 과학자들이 서명했다. 인공 지능의 위협에 대해 경고를 했던 '스티븐 호킹(Stephen William Hawking)' 박사와 '일론 머스크(Elon Musk)'도 서명했다고 한다. 아실로마 AI 원칙은 23개항으로 이루어져 있으며 , 크게 '연구 이슈(Research Issues)', '윤리와 가치(Ethics and Values)', '장기적 이슈(Longer-term Issues)'로 분류된다. 그 내용은 다음과 같다.
| 분류 | 아실로마 AI 원칙 |
| 연구이슈(Research Issues) | 연구 목표(Research Goal) |
| 연구비 지원(Research Funding) | |
| 과학-정책 관계(Science-Policy Link) | |
| 연구 문화(Research Culture) | |
| 경쟁 회피(Race Avoidance) | |
| 윤리와 가치(Ethics and Values) | 안전(Safety) |
| 오류 투명성(Failure Transparency) | |
| 사법의 투명성(Judicial Transparency) | |
| 책임성(Responsibility) | |
| 가치의 준수(Value Alignment) | |
| 인간의 가치(Human Values) | |
| 개인 정보 보호(Personal Privacy) | |
| 자유와 개인 정보(Liberty and Privacy) | |
| 이익 공유(Shared Benefit) | |
| 공동 번영(Shared Prosperity) | |
| 인간 통제(Human Control) | |
| 비파괴(Non-subversion) | |
| AI 무기 경쟁(AI Arms Race) | |
| 장기적 이슈(Longer-term Issues) | 능력에 대한 경계(Capability Caution) |
| 중요성(Importance) | |
| 위험 요소(Risks) | |
| 재귀적 자기 개선(Recursive Self-Improvement) | |
| 공익(Common Good) |
- 연구 목표(Research Goal): 인공 지능(AI) 연구의 목표는 지향하는 바가 없는 지능이 아니라 유익한 지능을 창출하는 것이다.
- 연구비 지원(Research Funding): AI에 대한 투자에는 다음과 같이 컴퓨터 과학, 경제, 법, 윤리 및 사회 연구 등의 어려운 질문을 포함한, 유익한 사용을 보장하는 연구에도 투자해야 한다.
- 과학-정책 관계(Science-Policy Link): AI 연구자와 정책 입안자 사이에는 건설적이고 건전한 교류가 있어야 한다.
- 연구 문화(Research Culture): AI의 연구자와 개발자 간에 협력, 신뢰, 투명성의 문화가 조성되어야 한다.
- 경쟁 회피(Race Avoidance): 안전 기준이 경시되지 않도록, 인공 지능 시스템을 개발하는 팀끼리는 적극적으로 협력해야 한다.
- 안전(Safety): AI 시스템은 작동 수명 전반에 걸쳐 안전하고 안정적이어야 하며, 운용 가능하고 현실적인 범위에서 검증되어야 한다.
- 오류 투명성(Failure Transparency): AI 시스템이 어떤 피해를 입히는 경우, 그 이유를 확인할 수 있어야 한다.
- 사법의 투명성(Judicial Transparency): 사법 결정에 있어 자동화된 시스템이 개입할 경우, 인간이 감사를 할 수 있도록 충분한 설명을 제공해야 한다.
- 책임성(Responsibility): 고급 AI 시스템의 설계자와 제조자는 그것의 사용, 오용 및 행위의 도덕적 함의에 있어서, 그것을 형성할 책임과 기회가 있는 이해 관계자(stake holder)입니다.
- 가치의 준수(Value Alignment): 고도로 자율적인 인공 지능 시스템은, 그 목표와 행동이 인간의 가치와 반드시 조화를 이루도록 설계되어야 한다.
- 인간의 가치(Human Values): AI 시스템은 인간의 존엄성, 권리, 자유 및 문화 다양성의 이상과 양립할 수 있도록 설계되고 운영되어야 한다.
- 개인 정보 보호(Personal Privacy): AI 시스템이 개인정보 데이터를 분석하고 활용할 수 있는 경우, 사람들은 자신이 생성한 데이터에 접근해 관리 및 제어할 권리를 가져야 한다.
- 자유와 개인 정보(Liberty and Privacy): 개인 정보에 대한 AI의 운용이, 개인이 원래 가지는 또는 가져야 할 자유를 부당하게 침해해서는 안 된다.
- 이익 공유(Shared Benefit): AI 기술은 가능한 많은 사람들에게 혜택을 주고 또한 역량을 강화해야 합니다.
- 공동 번영(Shared Prosperity): AI에 의해 만들어진 경제적 번영은 모든 인류에게 이익이 되도록 널리 공유되어야 한다.
- 인간 통제(Human Control): 인간은 인간이 선택한 목적를 달성하기 위해, 의사 결정을 AI 시스템에 위임할 것인지 여부와 방법에 대해 선택할 수 있어야 한다.
- 비파괴(Non-subversion): 고도로 발전된 AI 시스템이 가져다주는 제어의 힘은 기존의 건전한 사회의 기반이 되는 사회적, 시민적 프로세스를 존중하는 형태에서 개선에 이바지해야 하며, 기존의 프로세스를 뒤집는 것이어서는 안된다.
- AI 무기 경쟁(AI Arms Race): 자율형 치사 병기의 군비 확장 경쟁은 피해야 한다.
- 능력에 대한 경계(Capability Caution): 합의가 없으므로, 미래 AI의 능력 상한선에 대한 강한 가정은 피해야 한다.
- 중요성(Importance): 고급 AI는 지구 생명체의 역사에서 중대한 변화를 나타낼 수 있기 때문에, 그에 상응하는 관심 및 자원을 통해 계획되고 관리되어야 한다.
- 위험 요소(Risks): AI 시스템에 의해 인류를 괴멸 또는 절멸시킬 수 있는 위험에 대해서는 각각의 영향 정도에 따른 위험 완화의 노력을 계획적으로 해야 한다.
- 재귀적 자기 개선(Recursive Self-Improvement): 스스로 자기 개선 또는 자기 복제를 할 수 있는 AI 시스템은 진보나 증식이 급진할 수 있기 때문에 안전 관리를 엄격하게 해야 한다.
- 공익(Common Good): '초지능(superintelligence)'은 광범위하게 공유되는 윤리적 이상을 위해, 그리고 특정 조직이 아니라 전 인류의 이익을 위해 개발되어야 한다.

5. 인공 지능의 4가지 레벨
일본 도쿄대학의 '마쓰오 유타카(まつお ゆたか, 1975~)' 특임부 교수는 인공 지능을 4단계 레벨로 분류하였다. 현재 '레벨 4'의 인공 지능이 급속히 발전하고 있으며, 사회에 큰 영향을 미치고 있다.
- 레벨 1: 단순한 제어 프로그램을 '인공 지능'이라 부른 것이다. 인공 지능이라는 이름이 붙어 있지만 실제로는 '제어 공학'이나 '시스템 공학'으로 이미 오랜 역사를 가진 분야의 연구 결과물이다.
- 레벨 2: 고전적인 인공 지능이다. 기본적으로 단순한 제어 프로그램의 조합으로 이루어져 있지만, 움직임의 패턴이 매우 다양하다. ex) 챗봇
- 레벨 3: 데이터를 바탕으로 규칙이나 지식을 스스로 학습하는 '기계 학습'을 활용하는 인공 지능. 빅데이터를 바탕으로 고도의 판단을 한다. ex) IBM이 개발한 질문 응답 시스템 '왓슨'
- 레벨 4: '딥러닝(Deep Learning)'을 적용한 인공 지능. 컴퓨터가 스스로 데이터의 특징을 찾아냄으로써, 인간에 필적하는 판단을 할 수 있다. ex) 영상 인식