-
컴퓨터 구조(Computer Architecture)과학(Science)/컴퓨터 (Computer) 2024. 11. 5. 07:00
0. 목차
- 컴퓨터의 기본 구성
- 하드웨어(Hardware)
- 소프트웨어(Software)
- 컴퓨터 구조(Computer Architecture)
- 컴퓨터의 분류
- 프로그램 처리 과정

1. 컴퓨터의 기본 구성
'컴퓨터 시스템(Computer System)'은 기본적으로 '하드웨어(Hardware)'와 '소프트웨어(Software)'로 구성된다. 컴퓨터가 본래의 기능을 수행하기 위해서는 전기적으로 변환된 정보들을 입력하여 처리하고 저장해야 한다. '하드웨어'는 컴퓨터에서 각종 정보를 입력하여 처리하고 저장하는 동작이 실제 일어나게 해 주는 물리적인 실체이다. '소프트웨어'는 정보 처리의 종류를 지정하고 정보의 이동 방향을 결정하는 동작이 일어나는 시간을 지정해 주는 '명령(Command)'들의 집합, 즉 '프로그램(Program)'이다.
컴퓨터의 성능은 주로 하드웨어에 의해 결정되며, 소프트웨어는 하드웨어가 제공하는 기능들을 이용하여 최종 결과를 얻을 수 있도록 도와줄 뿐이다. 따라서 컴퓨터의 처리 능력은 근본적으로 하드웨어에 달려있으며, 다만 소프트웨어의 질에 따라 하드웨어의 사용 효율이 일부 향상되거나 사용 환경이 좀 더 편리해질 수는 있다.
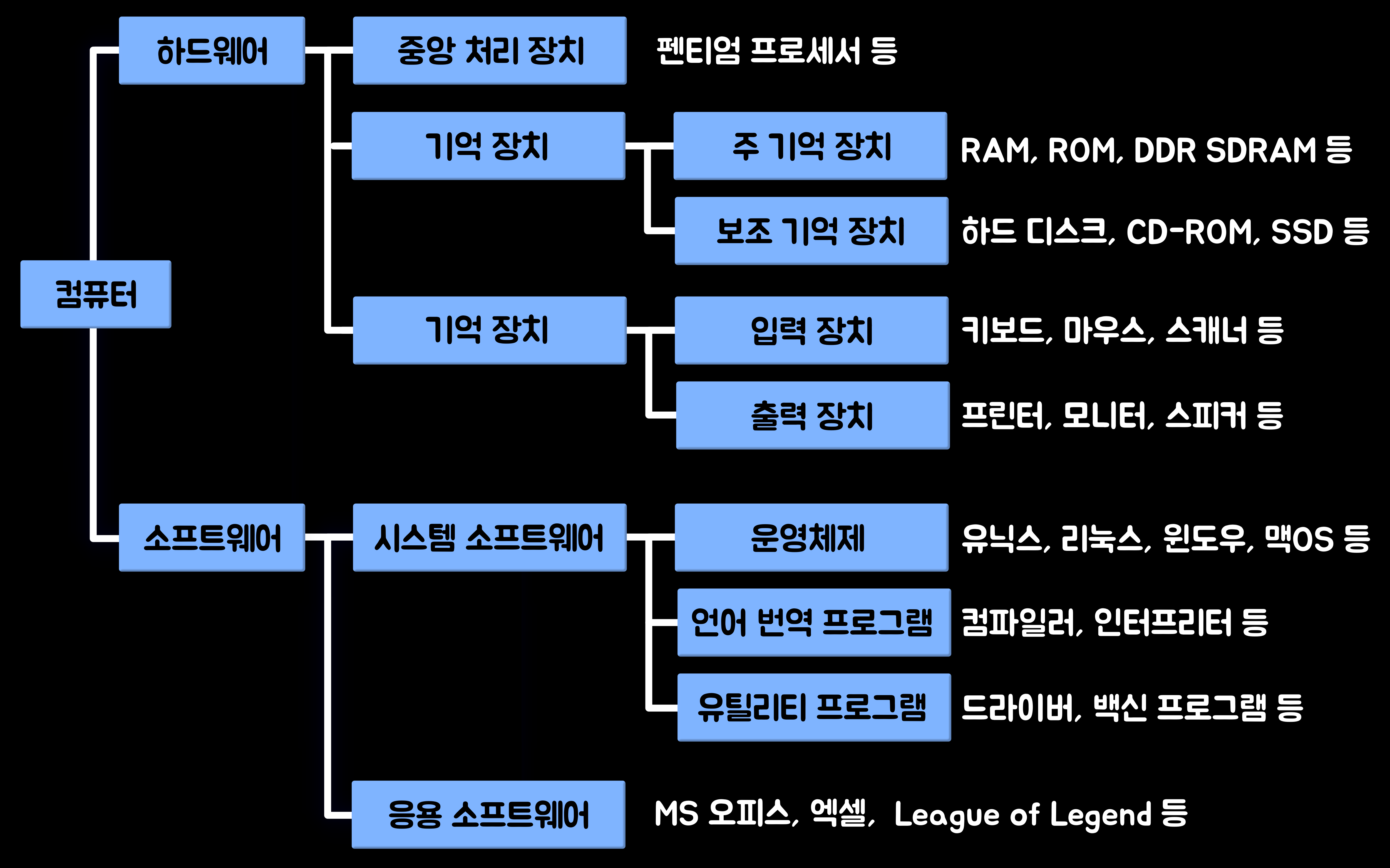
컴퓨터의 기본 구성 2. 하드웨어(Hardware)
컴퓨터 하드웨어는 아래의 그림과 같이 '중앙 처리 장치(CPU: Central Processing Unit)', '주기억 장치(Main Memory)', '보조 기억 장치(Auxiliary Storage Unit)', '입력 장치(Input Device)', '출력 장치(Output Device)', '시스템 버스(System bus)'로 구성된다. 컴퓨터는 사용자가 작성한 프로그램들을 정해진 순서대로 실행하는데, 이러한 기능을 수행하기 위해 각 구성 요소들은 그림과 같이 '시스템 버스'를 통해 상호 연결되어 있다.
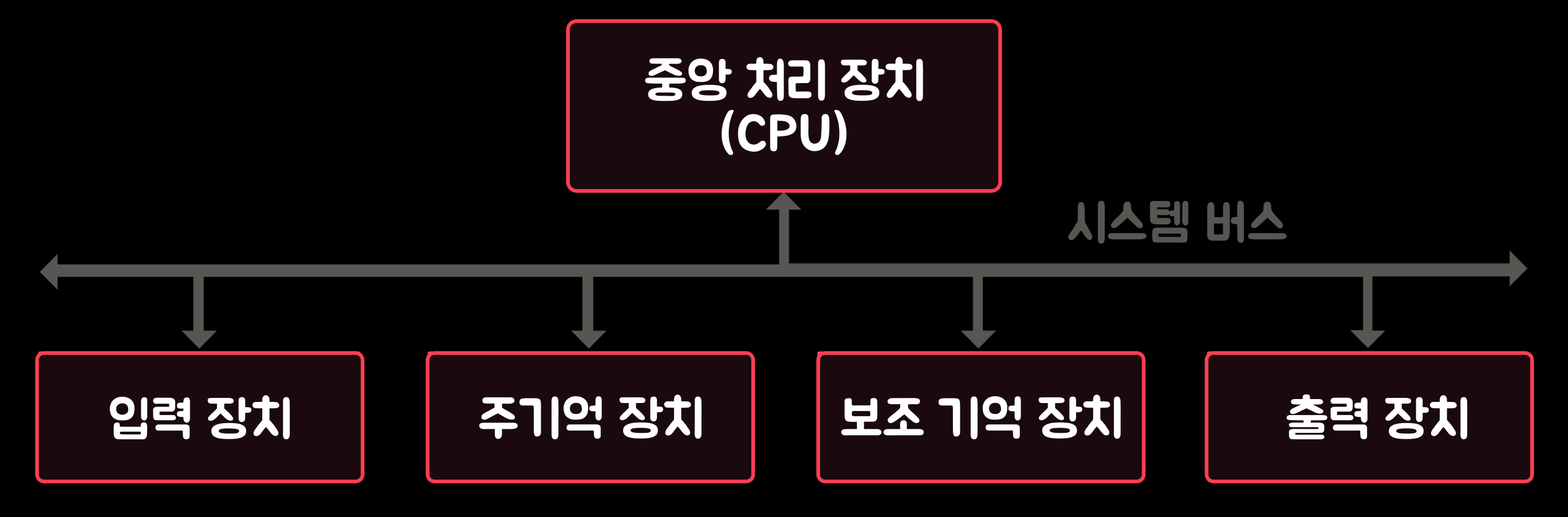
컴퓨터의 하드웨어 구성 2-1. 중앙 처리 장치(CPU)
'중앙 처리 장치(CPU: Central Processing Unit)'는 인간의 두뇌에 해당하는 부분으로, 사실상 컴퓨의 특성을 결정하며, 컴퓨터의 핵심 기능인 프로그램 실행과 데이터 처리를 담당한다. 중앙 처리 장치'를 '프로세서(Processor)' 또는 '마이크로프로세서(Microprocessor)'라고도 부르는데, 일반적으로 '마이크로프로세서'는 CPU를 '집적회로(IC: Integrated Circuit)' 칩 1개에 집적한 반도체 소자를 의미하기 때문이다.
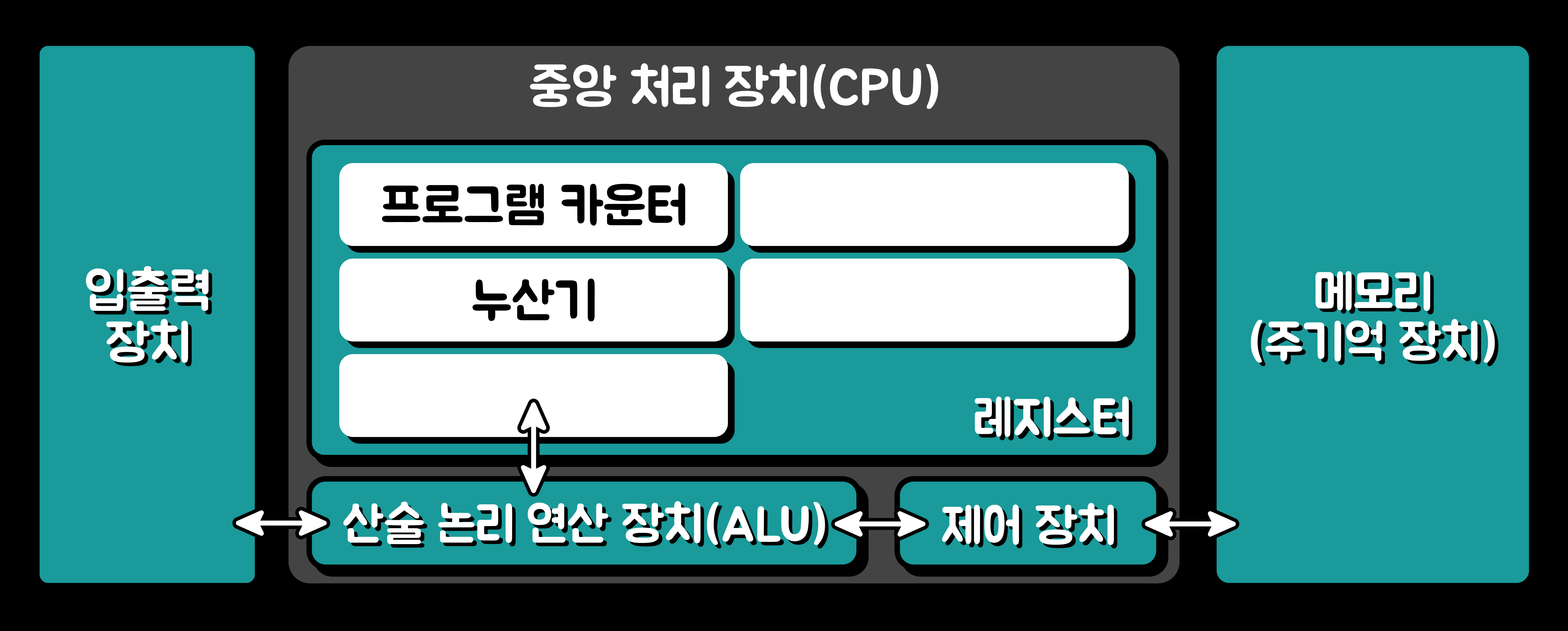
'중앙 처리 장치(CPU)'는 아래의 그림과 같이 '산술 논리 연산 장치(ALU: Arithmetic and Logic Unit)', '제어 장치(CU: Control Unit)', '레지스터(Register)'와 '내부 버스'로 구성된다. 각 구요소 간의 데이터 및 제어 신호의 이동은 CPU 내부 버스를 통해 이루어진다.
- 산술 논리 연산 장치(ALU: Arithmetic and Logic Unit): '산술 논리 연산 잔치(ALU)'는 '산술 연산(덧셈, 뺄셈)', '논리 연산(AND, OR, NOT)', '보수 연산(Complementary Operation)', '시프트 연산(Shift Operation)'을 수행한다.
- 제어장치(CU: Control Unit): '제어 장치(CU)'는 프로그램의 명령어를 해독하여 명령어 실행에 필요한 제어 신호를 발생시키고, 컴퓨터의 모든 장치를 제어한다.
- 레지스터(Register): '레지스터'는 '중앙 처리 장치(CPU)' 내부에 있는 데이터를 일시적으로 보관하는 임시 기억 장치로, 프로그램 실행 중에 사용되며 고속으로 '액세스(access)'할 수 있다.
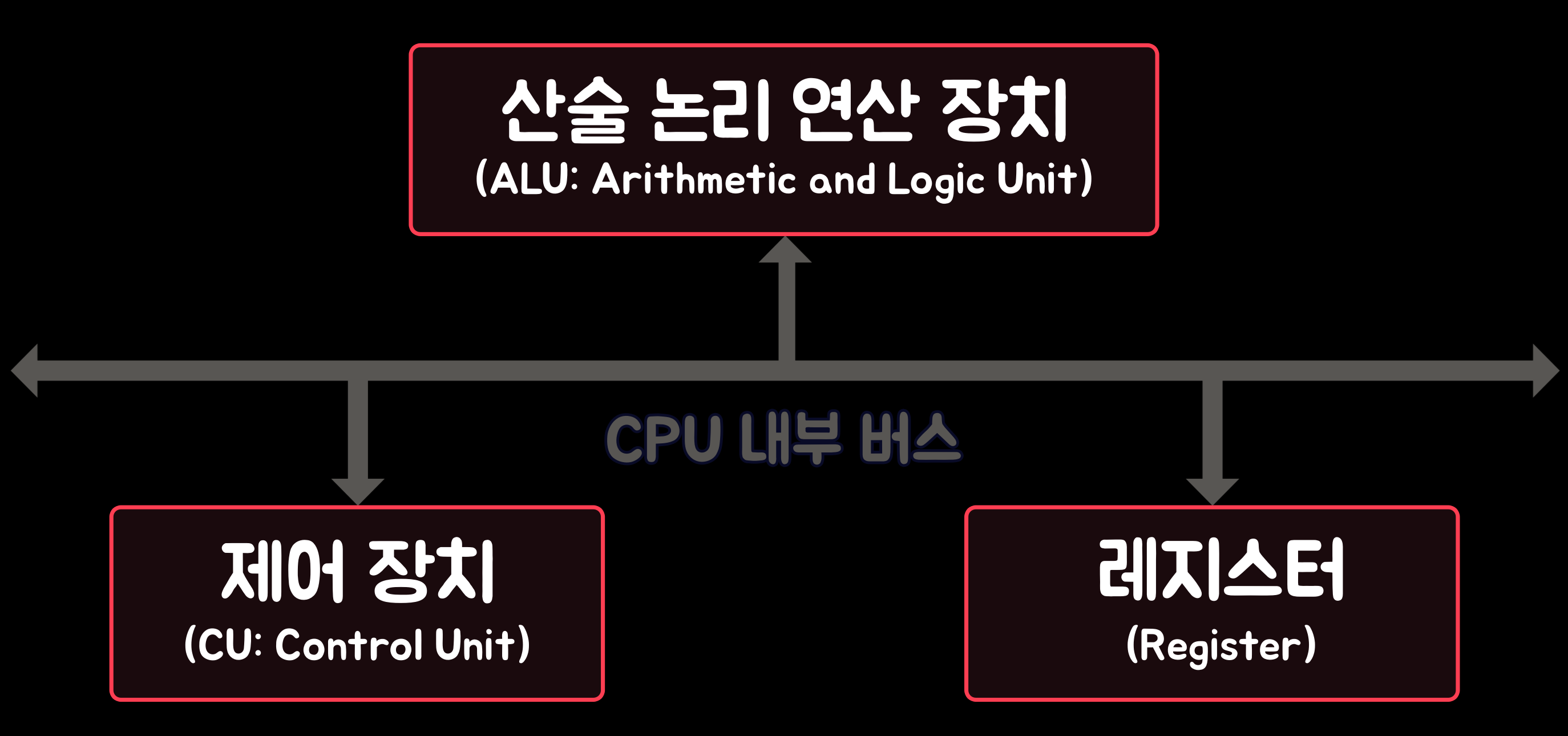
'중앙 처리 장치(CPU)'의 내부 구조 2-2. 기억 장치
'중앙 처리 장치(CPU: Central Processing Unit)'가 처리할 프로그램과 데이터는 기억 장치에 저장되는데, 기억 장치의 '특성', '용도', '속도'에 따라 '주기억 장치(Main Memory)'와 '보조 기억 장치(Auxiliary Storage Unit)'로 나뉜다.
- 주기억 장치(Main Memory): '주기억 장치'는 중앙 처리 장치 가까이에 위치하며, 반도체 칩으로 구성되어 고속으로 액세스가 가능하지만 고가다. 또한 프로그램 실행 중에 일시적으로만 사용되는 '휘발성 메모리'다. '휘발성 메모리'는 전원이 꺼지면 데이터가 지워지는 메모리이다.
- 보조 기억 장치(Auxiliary Storage Unit): '보조 기억 장치'는 '하드 디스크', 'SSD', 'CD-ROM' 같은 '비휘발성 메모리'이다. '비휘발성 메모리'는 전원이 꺼져도 데이터가 지워지지 않는 메모리로, 저장 밀도가 높고 저가지만 속도가 느리다. '중앙 처리 장치'에 당장 필요하지 않은 많은 양의 데이터나 프로그램을 저장하는 장치이다.
2-3. 입출력 장치(Input/Output Device)
'키보드(Keyboard)', '마우스(Mouse)' 같은 '입력 장치(Input Device)'는 데이터를 전자적인 2진 형태로 변환하여 컴퓨터 내부로 전달한다. '모니터(Monitor)', '프린터(Printer)', '스피커(Speaker)' 같은 '출력 장치(Output Device)'는 중앙 처리 장치가 처리한 전자적인 형태의 데이터를 사람이 이해할 수 있는 데이터로 변환하여 출력한다. '입력 장치'와 '출력 장치'를 합하여 '입출력 장치(Input/Output Device, I/O Device)'라고도 한다.
입출력 장치(I/O Device) 장치 입력 장치(Input Device) 키보드(Keyboard) 마우스(Mouse) 트랙패드(Trackpad) 스캐너(Scanner) 마이크로폰(Microphone) MIDI Keyboard Controller 출력 장치(Output Device) 모니터(Monitor) 프린터(Printer) 스피커(Speaker) - 키보드(Keyboard): '키(Key)'가 일정한 규격에 따라 배열되어 있는 입력 장치.
- 마우스(Mouse): 책상 위 따위에서 움직이면, 그에 따라 화면에 나타난 '커서(Cursor)'가 움직이며, 위에 있는 버튼을 눌려 명령어를 선택하거나 프로그램을 실행하는 컴퓨터 입력 장치.
- 트랙패드(Trackpad): 사용자의 손가락 움직임을 감지하여 디지털 신호로 변환하는 입력 장치. 밑에 하나의 버튼이 있어서 손가락으로 톡톡 치면 클릭한 것과 같은 반응을 하기 때문에, 마우스를 사용하여 클릭하는 것과 같다.
- 스캐너(Scanner): 책이나 사진 등에 있는 이미지나 문자 자료를 컴퓨터가 처리할 수 있는 형태로 정보를 변환하여 입력할 수 있는 입력 장치.
- 마이크로폰(Microphone): 줄여서 '마이크(Mic)'라고도 부르며, 음향을 전기 신호로 변환하는 장치로 센서 및 '변환기(Transducer)'의 일종이다.
- MIDI Keyboard Controller: 주 사용 목적은 USB 케이블로 '미디(MIDI: Musical Instrument Digital Interface)' 신호를 주고 받으며 '랙(Rack)' 형의 하드웨어 신디사이저나 컴퓨터 내의 가상악기를 편히 사용하는 것이다. 속칭 '마스터 키보드'라고 불린다.
- 모니터(Monitor): 영상을 표시하는 디스플레이 출력 장치.
- 프린터(Printer): 컴퓨터의 출력 결과를 종이에 인쇄하는 출력 장치.
- 스피커(Speaker): 전기 신호를 소리로 바꿔주는 출력 장치.
2-4. 전원 공급 장치
이외에도 각 하드웨어 구성 요소에 전기를 공급하기 위한 '전원 공급 장치(Electric Power Supply)'가 있다. '전원 공급 장치'는 구동에 필요한 전력을 컴퓨터 등 전자 기기 또는 '전기 부하(Electrical Load)'에 공급해 주는 전기 장치로 입력 전력으로부터 필요한 출력 전력을 생성하는 전력 회로이다.
2-5. 시스템 버스(System bus)
'시스템 버스(System bus)'는 '중앙 처리 장치(CPU: Central Processing Unit)', '기억 장치(Memory Unit)', '입출력 장치(Input/Output Device)' 사이에 정보를 교환하는 통로로, '주소 버스(Address bus)', '데이터 버스(Data bus)', '제어 버스(Control bus)'가 있다. 아래의 그림은 '중앙 처리 장치(CPU)'가 '주소 버스(Address bus)', '데이터 버스(Data bus)', '제어 버스(Contorl bus)'의 신호선을 통해 '기억 장치'와 '입출력 장치'가 연결된 모습이다.
- 주소 버스(Address bus): '주소 버스'는 '기억 장치'나 '입출력 장치'를 지정하는 주소 정보를 전송하는 신호 선들의 집합이다. '주소선(Address Line)'의 수는 '중앙 처리 장치(CPU)'와 접속할 수 있는 최대 기억 장치 용량을 결정한다. 예컨대 주소선이 16개라면 최대 216개의 기억 장소를 지정할 수 있다. 주소는 '중앙 처리 장치(CPU)'에서 발생되어 '기억 장치'와 '입출력 장치'로 보내지는 정보이기 때문에 '주소 버스'는 단방향성이다.
- 데이터 버스(Data bus): '데이터 버스'는 '기억 장치'나 '입출력 장치' 사이에 데이터를 전송하기 위한 신호선들의 집합이다. 데이터선의 수는 '중앙 처리 장치'가 한 번에 전송할 수 있는 데이터 비트의 수를 결정한다. 예컨대 '데이터 버스'가 32비트인 컴퓨터에서는 '중앙 처리 장치'가 '기억 장치'로부터 한 번에 32비트씩 읽거나 쓸 수 있다. '데이터 버스'는 읽기와 쓰기 동작을 모두 지원해야 하므로 양방향 전송이 가능해야 한다.
- 제어 버스(Control bus): '제어 버스'는 '중앙 처리 장치(CPU)'가 시스템 내의 각종 요소의 동작을 제어하는 데 필요한 신호선들의 집합이다. '제어 신호선'들의 개수는 컴퓨터에 따라 또는 시스템 구성에 따라 다르다. 이 중에서 중요한 것은 '기억 장치 읽기와 쓰기 신호', '입출력 장치 읽기와 쓰기 신호' 등이다. '제어 버스(Control bus)'도 단방향성이다.
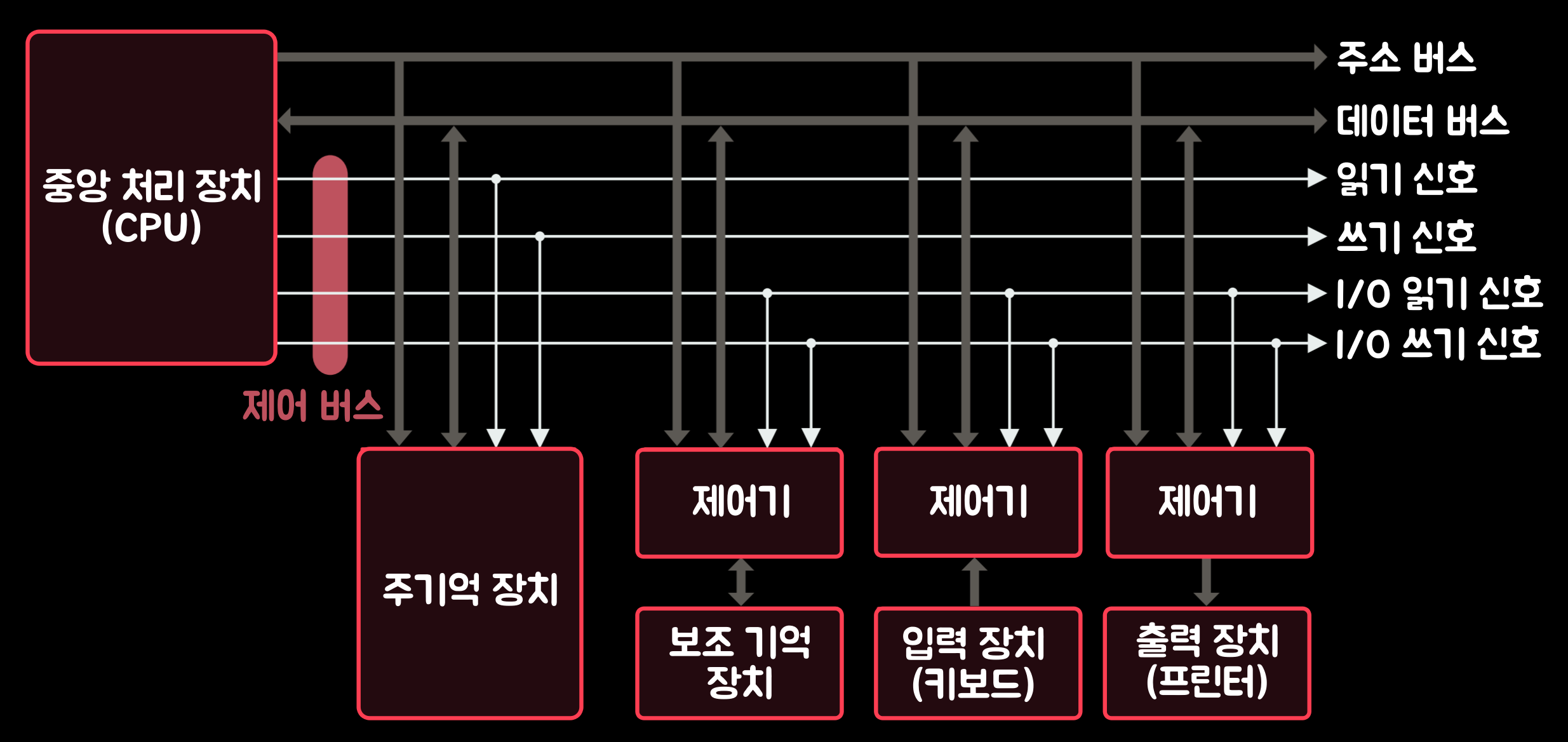
'중앙 처리 장치', '기억 장치', '입출력 장치'의 연결 2-6. 컴퓨터 시스템의 구성
- 'CPU'가 데이터를 읽는 경우: '중앙 처리 장치(CPU)'가 '주기억 장치(Main Memory)'로부터 데이터를 읽는 경우, '중앙 처리 장치(CPU)'는 데이터가 저장되어 있는 기억 장소의 주소를 '주소 버스(Address bus)'를 통해 보내면서 읽기 신호를 '활성화(Active)'한다. 그러면 일정한 시간이 경과한 후 '기억 장치'로부터 읽혀진 데이터가 '데이터 버스(Data bus)'에 실리며 '중앙 처리 장치'는 그 데이터를 읽으면 된다.
- 'CPU'가 데이터를 쓰는 경우: '중앙 처리 장치(CPU)'로 데이터를 쓰는 경우, '중앙 처리 장치(CPU)'는 데이터를 저장할 기억 장소의 '주소'와 '저장할 데이터'를 각각 '주소 버스(Address bus)'와 '데이터 버스(Data bus)'를 통해 보내고, 동시에 '쓰기 신호'를 활성화하면 된다. 따라서 '중앙 처리 장치'와 '주기억 장치' 사이에는 이러한 정보들의 통로인 '주소 버스(Address bus)', '데이터 버스(Data bus)' 및 '제어 버스(Control bus)'의 '읽기·쓰기 신호선'들이 연결되어야 한다.
반면 '하드 디스크(Hard Disk)'나 'CD-ROM' 같은 '보조 기억 장치(Auxiliary Storage Unit)'는 기계적인 장치가 포함되기 때문에 속도가 느리다. 그래서 '보조 기억 장치'는 '중앙 처리 장치'와 직접 연결되지 않는다. 또한 '입출력 장치'도 이와 같은 이유로 '중앙 처리 장치'와 직접 연결되지 않는다. 그래서 '보조 기억 장치'와 '입출력 장치'는 별도의 '인터페이스 회로'나 '제어기(Controller)'를 통해 '중앙 처리 장치(CPU)'와 연결되어야 한다. '중앙 처리 장치'와 '입출력 장치' 사이에는 정보들의 통로인 '주소 버스', '데이터 버스', '제어 버스'의 'I/O 읽기·쓰기 신호선'들이 연결된다.
반응형3. 소프트웨어(Software)
'소프트웨어(Software)'는 컴퓨터를 구성하고 있는 하드웨어를 잘 동작시킬 수 있도록 제어하고, 지시하는 모든 종류의 프로그램을 의미한다. '프로그램(Program)'은 컴퓨터를 사용해 어떤 일을 처리하기 위해 순차적으로 구성된 명령들의 집합이다. '소프트웨어'는 '시스템 소프트웨어(System Software)'와 '응용 소프트웨어(Application Software)'로 나눌 수 있다.
3-1. 시스템 소프트웨어(System Software)
'시스템 소프트웨어(System Software)'는 하드웨어를 관리하고 '응용 소프트웨어'를 실행하는 데 필요한 프로그램이다. '운영체제(OS)', '언어 번역 프로그램(Language Translating Program)', '유틸리티 프로그램' 등이 이에 속한다. '유틸리티 프로그램'은 각종 주변 장치들을 구동하는 데 필요한 '드라이버 프로그램', '백신 프로그램', 'TCP/IP(Transmission Control Protocol/Internet Protocol)' 같이 컴퓨터를 네트워크로 연결하는 데 필요한 각종 프로그램 등을 말한다.
- 운영체제(OS: Operating System): '운영체제'는 컴퓨터 하드웨어 자원인 '중앙 처리 장치', '기억 장치', '입출력 장치', '네트워크 장치' 등을 제어하고 관리하는 역할을 한다. 운영체제 종류로는 '유닉스(UNIX)', '리눅스(LINUX)', '윈도우(Windows)', '맥 OS(MAC OS)', 'iOS', '안드로이드(Android)' 등이 있다.
- 언어 번역 프로그램: '언어 번역 프로그램'은 인간 중심의 고급 언어로 작성한 '소스 프로그램(Source Program)'을 컴퓨터가 이해할 수 있는 '기계어(Machine Language)'로 변환하는 프로그램으로 '컴파일러(Compiler)'와 '인터프리터(Interpreter)'가 있다. '컴파일러(Compiler)'는 전체 소스 프로그램을 한 번에 기계로 직접 번역하여 실행하기 때문에 실행 속도가 빠르다. 'C', 'C++', 'C#', 'Java' 언어가 '컴파일러'를 채용하고 있다. 반면 '인터프리터(Interpreter)'는 소스 프로그램을 한 줄씩 기계어로 번역하여 실행하기 때문에 실행 속도가 '컴파일러'보다 느리다. '파이썬(Python)' '자바스크립트', 'HTML', 'SQL'같은 스크립트 언어가 '인터프리터'를 채용하고 있다.
- 장치 드라이버(Device Driver): '장치 드라이버'는 컴퓨터에 온라인으로 연결된 주변 장치를 제어하는 운영체제 모듈을 말한다.
- 링커(Linker): '링커'는 여러 개로 분할해 작성된 프로그램에 의해 생성된 '목적 프로그램(Object Program)' 또는 '라이브러리 루틴(Library Routine)'을 결합하여 실행 가능한 하나의 프로그램으로 연결하는 프로그램이다. '연결 편집기(Linkage Editor)'라고도 한다.
- 로더(Loader): '로더'는 하드 디스크 같은 저장 장치에 보관된 프로그램을 읽어 '주기억 장치(Main Memory)'에 적재한 후, 실행 가능한 상태로 만드는 프로그램이다. 이를 위해 '로더'는 '할당(Allocation)', '연결(Linking)', '재배치(Relocation)', '적재(Loading)'의 기능을 수행한다.
3-2. 응용 소프트웨어(Application Software)
'응용 소프트웨어(Application Software)'는 컴퓨터 시스템을 사용자들이 특정한 용도에 활용하기 위해 만든 프로그램으로, '애플리케이션(Application)', '앱(App)', '어플'이라고도 한다. 이는 컴퓨터를 통해 최종 사용자가 원하는 작업을 수행하도록 해주며, 사용자가 직접 사용하는 최상위 계층의 소프트웨어이다. '응용 소프트웨어'는 아래의 표와 같이 '사무', '멀티미디어', '게임', '통신 및 네트워크' 등 종류가 다양하다.
용도 예 사무용 한글, MS-office 제품군 그래픽용 포토샵(Photoshop), 페인트샵, 일러스트레이터 멀티미디어용 WinAMP, GOM Player, PowerDVD 게임용 스타크래프트(Starcraft), 워크래프트(Warcraft), GTA5, League of Legend 통신 및 네트워크용 인터넷 익스플로러, 크롬(Chrome), 모질라, 사파리, MSN 메신저, 카카오톡 4. 컴퓨터 구조(Computer Architecture)
4-1. 폰 노이만 구조(Von-Neumann Architecture)
가장 초기의 전자 컴퓨터에서 '프로그래밍(Programming)'은 '와이어(Wire)'를 '플러그(Plug)'에 연결하는 것이었다. 당시에는 현재와 같은 '소프트웨어 프로그래밍(Software Programming)'이 아니라 '하드웨어 프로그래밍(Hardware Programming)'이었다. 그래서 '프로그래밍'은 매우 지루하고, 에러도 많고, 매우 비능률적인 작업이었다.
'에니악(ENIAC)'이 완성되기 전에 '존 윌리엄 모클리(John William Mauchly 1907~1980)'와 '존 아담 프레스퍼 에커트(John Adam Presper Eckert, 1919~1995)'는 계산 기계의 동작을 변경하는 더 쉬운 방법을 생각했다. 그들은 '수은 지연 라인(Mercury Delay Line)' 형태의 메모리 장치가 프로그램을 저장할 수 있을 것으로 생각했다. 이렇게 하면 새로운 문제가 있을 때마다 시스템을 다시 배선하는 지루한 작업을 하지 않아도 된다고 생각한 것이다. '모클리'와 '에커트'는 자신의 아이디어를 문서화하여 '에드박(EDVAC)'의 기반으로 제안했다. 그러나 불행하게도 '모클리'와 '에커트'는 2차 세계대전 중 가장 비밀스런 '에니악 프로젝트'에 참여했기 때문에, 즉시 그들의 아이디어를 발표할 수 없었다. 이후 1945년에 헝가리의 수학자 '폰 노이만(John von Neumann)'은 '에드박(EDVAC)'에 대한 '모클리'와 '에커트'의 아이디어를 읽은 후, '폰 노이만 구조'를 발표했다. 현재까지 프로그램을 '메모리'에 '저장하여 처리하는 모든 컴퓨터를 '폰 노이만 구조'를 따르는 것으로 알려져 왔다. 그러나 이러한 개념을 처음으로 생각한 사람은 '모클리'와 '에커트'였다.
'폰 노이만 구조(Von-Neumann Architecture)'는 '메모리'에 프로그램과 데이터를 넣고 차례로 인출하여 처리하는 방식이다. '폰노이만 구조'는 '중앙 처리 장치(CPU)', '메모리(Memory)', '입출력 장치'로 구성되고 다음과 같은 과정으로 프로그램을 처리한다.
- 프로그램 카운터를 이용해 '메모리'에서 실행할 명령어를 인출한다.(Fetch)
- 제어장치는 이 명령어를 해독한다.
- 명령을 실행하는 데 필요한 데이터를 '메모리'에서 인출하여 '레지스터'에 저장한다.
- '산술 논리 연산 장치(ALU)'는 명령을 실행하고(Execute), '레지스터'나 '메모리'에 결과를 저장한다.(Store)
폰 노이만 구조(Von-Neumann Architecture) 4-2. 비 폰 노이만 구조(non Von-Neumann Architecture)
하지만 '폰 노이만 구조(Von-Neumann Architecture)'의 프로그램 저장 방식에도 '폰 노이만 병목 현상(Von-Neumann Bottleneck)'이라는 단점이 있다. '폰 노이만 구조'의 컴퓨터는 '중앙 처리 장치(CPU)'에서 명령어나 데이터를 '메모리'에서 가져와 처리한 후, 결과 데이터를 메모리에 다시 보내 저장한다. 또한 저장된 데이터가 필요할 땐 다시 '메모리'나 '시스템 버스(System bus)'에 병목 현상이 생겨 속도가 느려질 수밖에 없다. 이것을 '데이터 경로의 병목 현상' 또는 '기억 장소의 지연 현상'이라고도 한다. 또한 '중앙 처리 장치(CPU)'의 연산 속도가 아무리 빨라져도 한 가지씩 일을 순차적으로 처리하므로 지능 축적이 불가능하다.
'비 폰 노이만 구조(non Von-Neumann Architecture)'의 컴퓨터는 '폰 노이만 구조(Von-Neumann Architecture)'가 아닌 컴퓨터를 통틀어 이르는 말이다. '비 폰 노이만 구조'는 데이터 처리의 고속화·고도화를 위하여 프로그램 일부를 하드웨어화하거나 '병렬 처리 기능', '추론 기구'를 채택한 컴퓨터를 가리킨다. 연구되고 있는 분야로는 '신경망(뇌의 모델에서 나온 개념을 컴퓨팅 패러다임으로 사용)', '유전 알고리즘(생물학 및 DNA 진화의 아이디어 활용', '양자컴퓨터(Quantum Computer)', '병렬 컴퓨터(Parallel Computer)'를 비롯한 여러 분야들이 '비 폰 노이만' 범주에 속한다. 이 중에서 '병렬 컴퓨팅'이 현재 가장 많이 사용된다.
4-3. 하버드 구조(Harvard Architecture)
'컴퓨터 시스템(Computer System)'은 메모리 구성에 따라 '폰 노이만 구조(Von-Neumann Architecture)'와 '하버드 구조(Harvard Architecture)'로 분류한다. '폰 노이만 구조'는 명령어 메모리 영역'과 '데이터 메모리 영역'의 물리적 구분이 없어서, '중앙 처리 장치(CPU)'는 하나의 '시스템 버스(System Bus)'를 통해 메모리로부터 명령어나 데이터를 읽거나 쓴다. 그래서 '폰 노이만 구조'에서는 구조적으로 '시스템 버스'에 병목이 발생한다.
'하버드 구조(Harvard Architecture)'는 이러한 '폰 노이만 구조(Von-Neumann Architecture)'의 단점을 보안한다. 명령어 메모리'와 '데이터 메모리' 영역을 물리적으로 분리시키고, 각각을 다른 시스템 버스로 '중앙 처리 장치'에 연결함으로써 '명령'과 '데이터를 메모리로부터 읽는 것'을 동시에 처리할 수 있다. 그러나 '하버드 구조'는 그만큼 비싸고, 공간도 많이 차지하며, 설계가 복잡하다. 또한 폰 노이만 구조'를 기반하여 만들어진 것이기 때문에, '병목 현상'만 일부 해결할 뿐, 메모리를 순차적으로 실행하는 근본적 구조가 변하는 것은 아니다.
최근에는 CPU 설계에서 '폰 노이만 구조'와 '하버드 구조' 양자의 구조를 도입하고 있다. '캐시 메모리(Cache Memory)'는 보통 '명령용'과 '데이터용'으로 분리되어 있다. '하버드 구조'는 '중앙 처리 장치(CPU)'와 '캐시(Cache)'의 관계에 활용되고 있다. '캐시(Cache)'에 오류가 일어나면 '주기억 장치(Main Memory Unit)'로부터 데이터를 가져오고, '명령 캐시(Instruction Cache)'나 '데이터 캐시(Data Cache)'에 저장한다. 따라서 '폰 노이만 구조'는 '중앙 처리 장치' 외부에 적용된다.
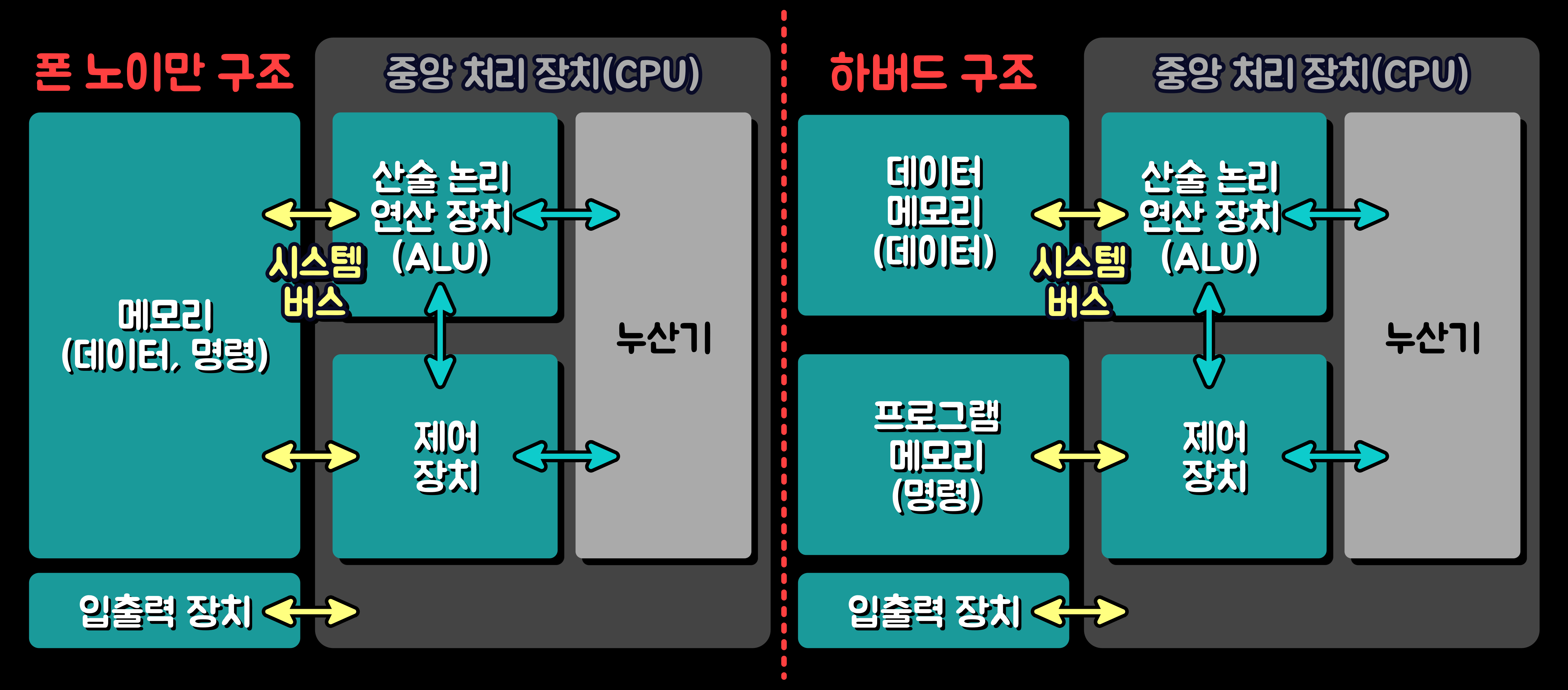
'폰 노이만 구조'와 '하버드 구조' 5. 컴퓨터의 분류
컴퓨터는 다양한 측면에서 분류할 수 있지만, 일반적으로 아래 그림과 같이 '데이터 형태에 따른 분류', '사용 목적에 따른 분류', '성능과 규모에 따른 분류'의 세 가지 측면으로 분류해 볼 수 있다.
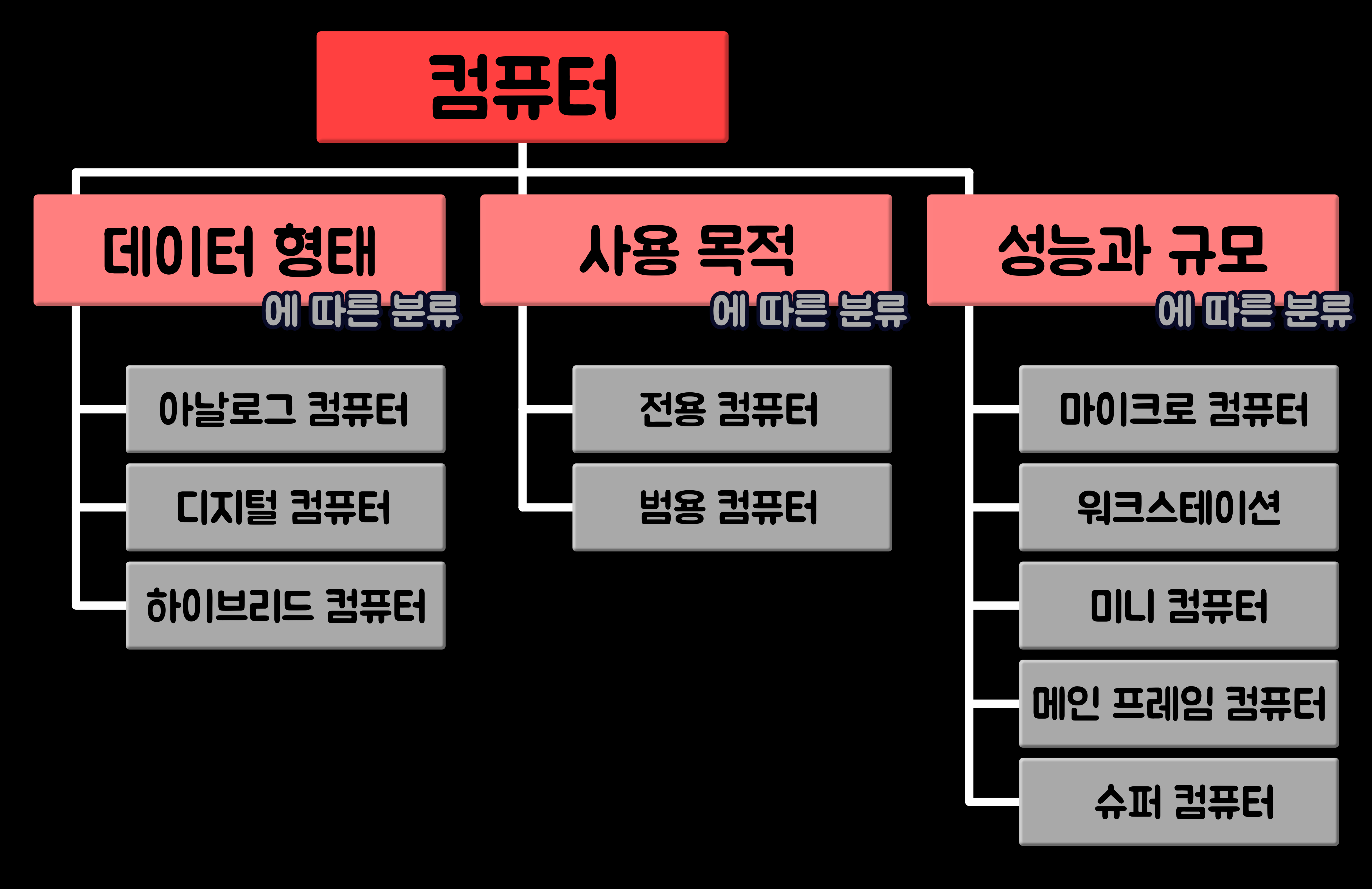
컴퓨터의 분류 5-1. '데이터 형태'에 따른 분류
컴퓨터는 '데이터 형태'에 따라 '아날로그 컴퓨터(Analog Computer)'와 '디지털 컴퓨터(Digital Computer)'로 나눌 수 있다.
- 아날로그 컴퓨터(Analog Computer): '아날로그 컴퓨터'는 연속적인 별야을 사용하여 계산을 수행한다. 필요한 입력 데이터는 계측 기기로부터 직접 입력할 수 있으며, 신속한 입력과 그 상태에 대한 즉각적인 반응을 얻을수 있다. 따라서 이 유형의 컴퓨터는 '프로세스 제어(Process Control)'에 적합하다. '아날로그 컴퓨터'에서는 '전압', '전류', '온도', '압력' 등의 데이터를 처리한다.
- 디지털 컴퓨터(Digital Computer): '디지털 컴퓨터(Digital Computer)'는 숫자나 문자를 코드화하여 필요한 정밀도까지의 결과를 얻을 수 있다. 디지털 컴퓨터는 숫자나 문자를 코드화하여 사용하며, 데이터를 분석하고 종합하여 처리한 결과를 숫자나 문자 등으로 정확히 구분할 수 있게 해준다.
- 하이브리드 컴퓨터(Hybrid Computer): '하이브리드 컴퓨터(Hybrid Computer)'는 '아날로그 컴퓨터(Analog Computer)'와 '디지털 컴퓨터(Digital Computer)'의 장점들을 조합하여 특수 목적으로 만든 것으로, 모든 유형의 데이터를 처리할 수 있다. '하이브리드 컴퓨터'에서 처리한 결과는 필요에 따라 'A/D 변환기(ADC: Analog-Digital Converter)'나 'D/A 변환기(DAC: Digital-Analog Converter)'에 의해서 데이터를 아날로그 형태나 디지털 형태로 얻을 수 있다.
5-2. '사용 목적'에 따른 분류
컴퓨터는 사용 목적에 따라 '전용 컴퓨터(Special Purpose Computer)'와 '범용 컴퓨터(General Purpose Computer)'로 나눌 수 있다.
- 전용 컴퓨터(Special Purpose Computer): '전용 컴퓨터'는 특수한 목적으로 사용하기 위한 컴퓨터로, 주로 '군사용', '기상 예보용', '천문학', '원자핵 물리' 분야 등의 특정 업무에 사용된다. '전용 컴퓨터'는 주로 고정 프로그램과 일정한 데이터만을 취급할 수 있도록 구성되어 있다.
- 범용 컴퓨터(General Purpose Computer): '범용 컴퓨터'는 여러 업무에 광범위하게 사용할 수 있는 일반 목적용 컴퓨터다. 즉 '과학 계산', '통계 데이터 처리', '생산 관리', '사무 관리' 등 광범위한 분야에 사용할 수 있다. '범용 컴퓨터'는 여러 분야의 다양한 업무를 취급하기 때문에 '여러 형태의 데이터를 취급할 수 있는 유연성', '기억 용량의 증대', '처리 속도의 신속화', '입출력 장치의 다양화' 등 언제든지 필요한 시기에 확장 또는 조정할 수 있는 기능이 필요하다.
5-3. '성능과 규모'에 따른 분류
컴퓨터의 '처리 성능'과 '규모'에 따른 구분은 정량보다는 정성적 측면에서 분류한 것이다. 초기에는 컴퓨터의 크기로 분류하는 경향이 있었지만, 점차 컴퓨터가 발달됨에 따라 그러한 기준의 보편성을 잃게되었다. 따라서 근래에는 분류의 기준을 '기억 용량', '처리 능력', '가격' 측면에 두고 있다. 규모와 성능 측면에서 높은 순으로 살펴보면 아래의 그림과 같다. 하지만 이와 같은 분류는 컴퓨터 관련 기술의 급속한 발전으로 인해 구분이 모호해지고 있다.
- 마이크로 컴퓨터(Micro Computer): '마이크로 컴퓨터'는 최근 가장 널리 사용되고 있는 범용 컴퓨터다. '마이크로프로세서(Microprocessor)'를 '중앙 처리 장치(CPU)'로 사용하는 컴퓨터를 의미하며, 대표적으로 '워크스테이션(Workstation)'과 '개인용 컴퓨터(PC)'가 있다. '마이크로프로세서'는 '중앙 처리 장치(CPU)'를 반도체 칩 하나에 내장한 것이다. 최초의 '마이크로 프로세서'는 1970년대 초에 개발되었고, 마이크로프로세서를 사용한 '마이크로 컴퓨터'는 1970년대 중반에 개발되었으며, 1970년대 후반에는 개인용 컴퓨터가 등장했다. 1980년대에 들어서면서 '마이크로프로세서'의 성능이 급속도로 향상되면서, 개인용 컴퓨터의 응용 범위도 단순 응용에서부터 매우 복잡한 응용에까지 확산되고 있다. 최근에는 개인용 컴퓨터의 발전으로 '워크스테이션'과의 구별이 모호해지고 있다.
- 워크스테이션(Workstation): '워크스테이션'은 '과학자(Scientist)', '공학자(Engineer)', '애니메이터(Animator)'와 같은 전문직 종사자들이 개인용 컴퓨터보다 더 우수한 성능을 요구하여 만들어진 컴퓨터다. 외형은 개인용 컴퓨터와 비슷하다. 최근에는 '워크스테이션'의 가격이 떨어지고 '개인용 컴퓨터'의 성능이 강력해져서, '워크스테이션'과 '개인용 컴퓨터'의 구분이 사라지고 있다.
- 미니 컴퓨터(Mini Computer): '미니 컴퓨터'는 성능과 규모 측면에서 '마이크로 컴퓨터(Micro Computer)'와 '메인 프레임 컴퓨터(Main Frame Computer)'의 중간에 해당한다. '마이크로 컴퓨터'보다 '대용량 기억 장치'와 '고속의 주변 장치'들로 구성되어 있어서, 다수의 사용자가 동시에 한 미니 컴퓨터를 사용할 수 있었다. 초기의 미니 컴퓨터는 작은 규모의 연구실에서 10명 미만의 연구원들이 연구실 전용의 컴퓨터로 사용하도록 만들었다. 초기에는 '과학 기술용 수치 계산'과 '정밀 기계의 제어'를 목적으로 만들어졌으며, 사무 자동화에는 이용되지 않았다. 그러나 '컴퓨터 설계 기술의 발전'과 '부품 가격의 하락'으로 인해, '미니 컴퓨터'의 성능도 향상되어 사무 자동화에도 사용될 수 있는 '슈퍼 미니 컴퓨터'가 등장했다. 최근에는 '컴퓨팅 서버(Computing Server)', '파일 서버(File Server)', '네트워크 서버(Network Server)' 등과 같은 각종 서버의 등장으로 인해 그 자취를 감추게 되었다.
- 메인 프레임 컴퓨터(Main Frame Computer): '메인 프레임 컴퓨터'는 1초에 수십억 개의 명령어를 처리할 수 있는 고속의 컴퓨터로, '대형 컴퓨터'라고도 불린다. '메인 프레임(Main Frame)'은 '대기업', '관공서', '대학' 등에서 다수의 사용자가 공유하여 사용한다. '메인 프레임'에는 '단말기(Terminal)'를 통해 접근할 수 있는데, '단말기'는 '키보드'와 '모니터'가 통합된 장치를 말한다. '메인 프레임'의 응용 분야는 '은행', '보험', '병원 업무' 등에 널리 사용되고 있다.
- 슈퍼 컴퓨터(Super Computer): '슈퍼 컴퓨터'는 고속의 연산 처리를 위한 '중앙 처리 장치(CPU)', 대규모의 용량을 가진 '주기억 장치', 강력한 병렬 처리를 지원하는 '소프트웨어'로 이루어진 컴퓨터다. 슈퍼 컴퓨터는 고성능 마이크로프로세서를 수십만 개까지 사용하여 작업을 병렬로 처리하기 때문에, 초당 수조 개의 명령어들을 처리할 수 있을 정도로 매우 빠르다. '슈퍼 컴퓨터'는 '기상예측', '석유탐사', '원자력 개발' 등의 분야에서 사용되고 있다.
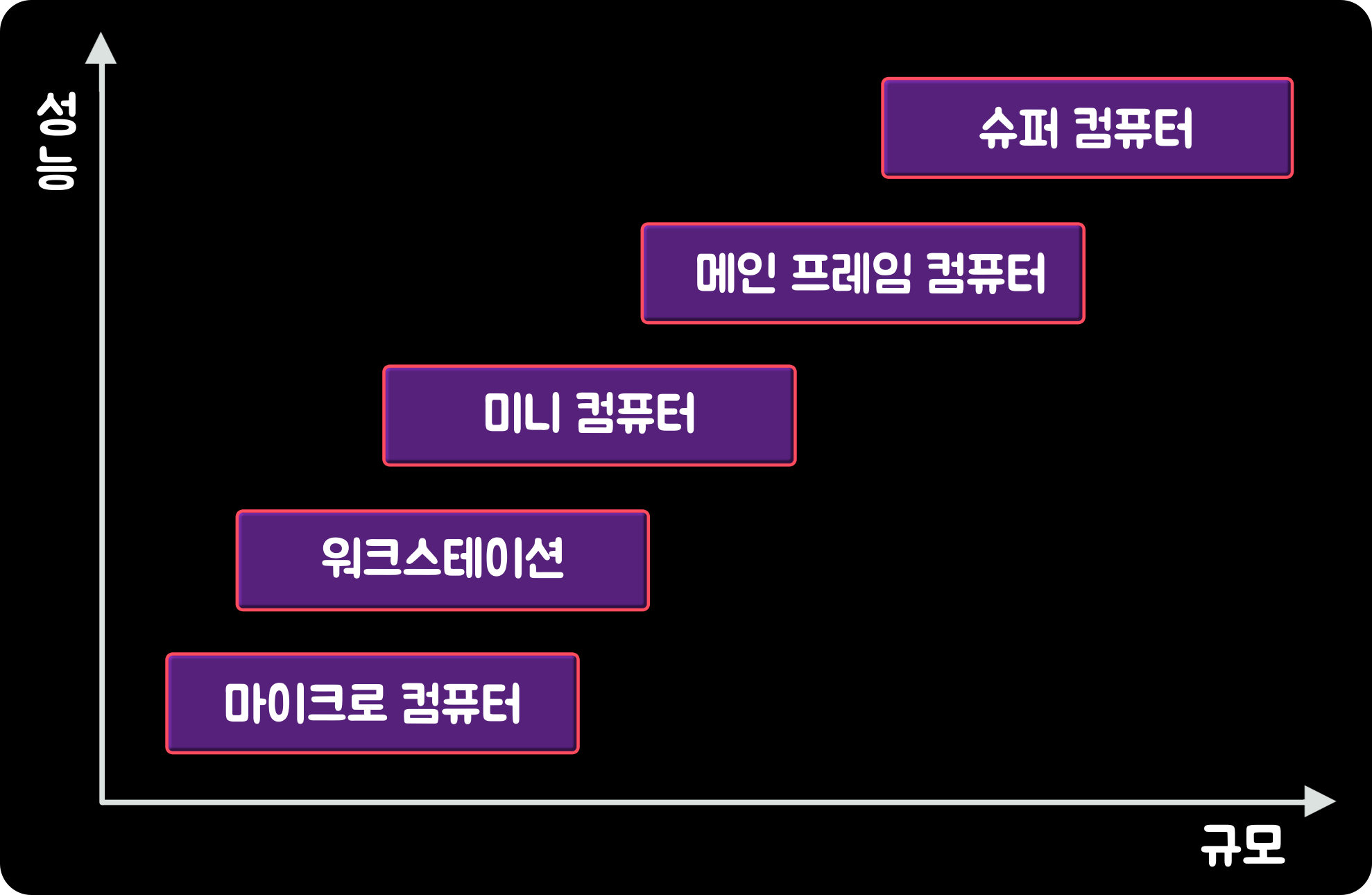
처리 성능과 규모에 따른 컴퓨터 분류 6. 프로그램 처리 과정
컴퓨터는 'C', 'C++', '자바(Java)', '파이썬(Python)' 등과 같은 '고급 언어(High-Level Language)'로 작성된 프로그램을 실행함으로써 다양한 문제를 해결할 수 있다. '프로그램(Program)'은 어떤 결과를 얻기 위해, 컴퓨터가 받아들일 수 있는 형태의 '명령어(Instruction)'를 나열하여 구성한 문장이다. 프로그램은 보통 '고급 언어(High-Level Language)'로 작성한다. 이렇게 작성된 프로그램은 영문자와 숫자로 이루어져 있어 사람들은 이해하기는 쉽지만 컴퓨터는 이해할 수 없다. 따라서 고급 언어로 작성된 프로그램은 '컴파일러(Compiler)'라는 소프트웨어를 이용해 컴퓨터가 이해할 수 있는 언어인 '기계어(Machine Language)'로 번역해야 한다. 컴퓨터는 모든 정보를 0과 1로 구성된 2진수로 작성해야 이해할 수 있는데, 이때 2진수로 표현된 언어가 '기계어(Machine Language)'이다.
'고급 언어(High-Level Language)'는 컴퓨터의 종류에 관계없이 거의 동일하지만 '기계어'는 컴퓨터마다 다르다. 이러한 언어의 차이를 해결하기 위해 '고급 언어'와 '기계어' 사이에는 컴퓨터 고유의 중간 언어가 존재하는데, 이를 '어셈블리어(Assembli Language)'라고 한다. '고급 언어'로 작성된 프로그램을 처리하기 위해서는 일단 '어셈블리어'로 번역되고, 그다음 해당 컴퓨터가 이해할 수 있는 '기계어'로 번역된다.
각 어셈블리어 명령어 동작을 개략적으로 이해할 수 있도록 사용된 기호인 LOAD, ADD, STOR를 '니모닉(mnemonic)'이라고 한다. 명령어들은 CPU가 수행할 동작뿐만 아니라, 처리할 데이터가 저장된 '메모리 주소(Memory Address)'나 '레지스터 번호(Register Number)'도 구체적으로 지정해 준다. 이와 같이 명령어들은 CPU의 내부 구조와 밀접한 관계가 있기 때문에 '어셈블리어' 프로그래머는 컴퓨터의 내부 구조를 이해하고 있어야 프로그램을 작성할 수 있다. '어셈블리어'로 작성된 프로그램은 '언어 번역 프로그램'인 '어셈블러(Assembler)'가 '기계어(Machine Language)'로 번역해준다.
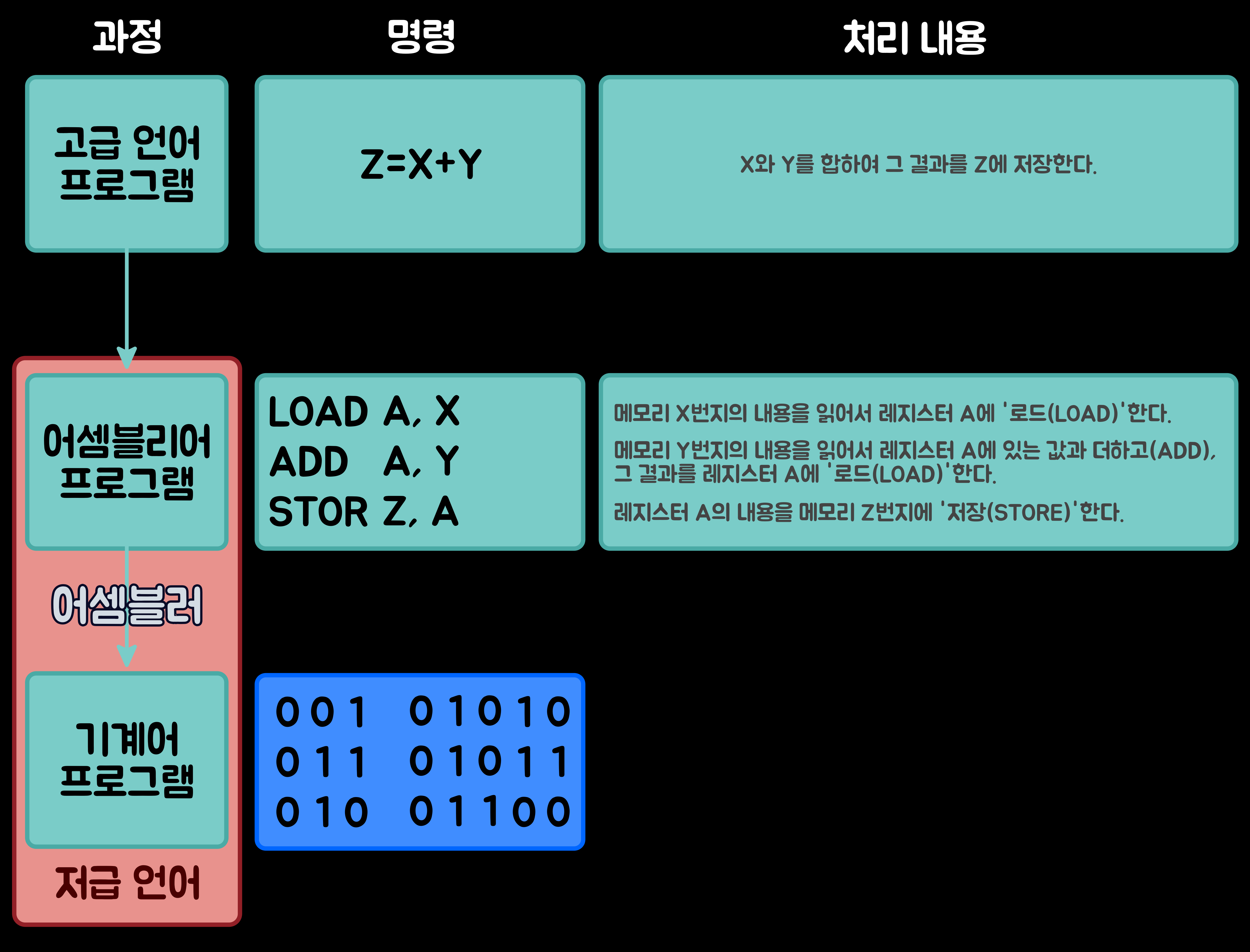
고급 언어 프로그램의 변환 과정과 예 6-1. 기계어 처리
변화의 마지막 단계인 '기계어(Machine Language)'는 2진수인 0과 1의 조합으로 이루어진다. 이 예에서는 '어셈블리 명령어'들이 각각 8비트 기계어로 번역되었다고 가정했다. 또한 번역된 기계어는 3비트 '연산 코드(Opcode)'와 5비트 '오퍼랜드(operand)'로 구성되어 있다고 가정했다. 여기서 '연산 코드(opcode)'는 수행할 연산을 지정하고, '오퍼랜드(operand)'는 명령어가 사용할 데이터가 저장되어 있는 기억 장소의 주소를 가리킨다.
아래의 그림 B는 번역된 기계어들이 '주기억 장치(Main Memory)'에 순서대로 저장되어 있는 모습을 개략적으로 나타낸 것이다. 그림 C에서 기계어는 0번지부터 저장되어 있고, 계산에 사용될 데이터는 10번지와 11번지에 각각 저장되어 있다. '중앙 처리 장치(CPU)'가 한 번에 처리할 수 있는 비트들의 그룹을 '워드(Word)'라고 하는데, 이 예에서는 한 워드의 길이를 8비트로 가정했다.
중앙 처리 장치(CPU)'는 '주기억 장치)'에 저장되어 있는 '기계어(Machine Language)'를 순차적으로 읽는다. 읽힌 기계어 중에서 앞의 3비트를 이용해 명령의 종류를 해독하는 기능은 '중앙 처리 장치(CPU)' 내부의 '제어 장치(CU: Control Unit)'에서 수행한다. 그리고 '로드(LOAD)', '저장(STOR)' 동작은 '제어 장치'에서 이에 필요한 제어 신호들을 발생시켜서 수행하고, 덧셈은 '산술 논리 연산 장치(ALU)'에서 수행한다.
- LOAD A, X: 연산 코드 001은 '레지스터 A에 로드하라'는 명령을 지정해 주는 비트고, 오퍼랜드 01010은 로드될 데이터가 저장되어 있는 메모리의 주소다. 2진수 01010은 10진수로 10이므로, 오퍼랜드가 10번지를 가리키고 있다. 따라서 이 기계어 '001 01010'은 메모리 10번지의 내용을 읽어 '레지스터 A'에 로드하라는 의미이다.
- ADD A, Y: 연산 코드 011은 더해서 '레지스터 A에 로드하라'는 명령을 지정해 주는 비트고, 오퍼랜드 01011은 10진수로 11이므로, 오퍼랜드가 10번지를 가리키고 있다. 따라서 이 기계어 '011 01011'은 '레지스터 A의 내용과 메모리 11번지의 내용을 더해 그 결과를 레지스터 A에 로드하라'는 의미이다.
- STOR Z, A: 연산 코드 010은 레지스터 A의 내용을 저장하라'는 명령을 지정해 주는 비트고, 오퍼랜드 01100은 10진수로 12이다. 따라서 이 기계어 '010 01100'은 '레지스터 A의 내용을 메모리 12번지에 저장하라'는 의미이다.
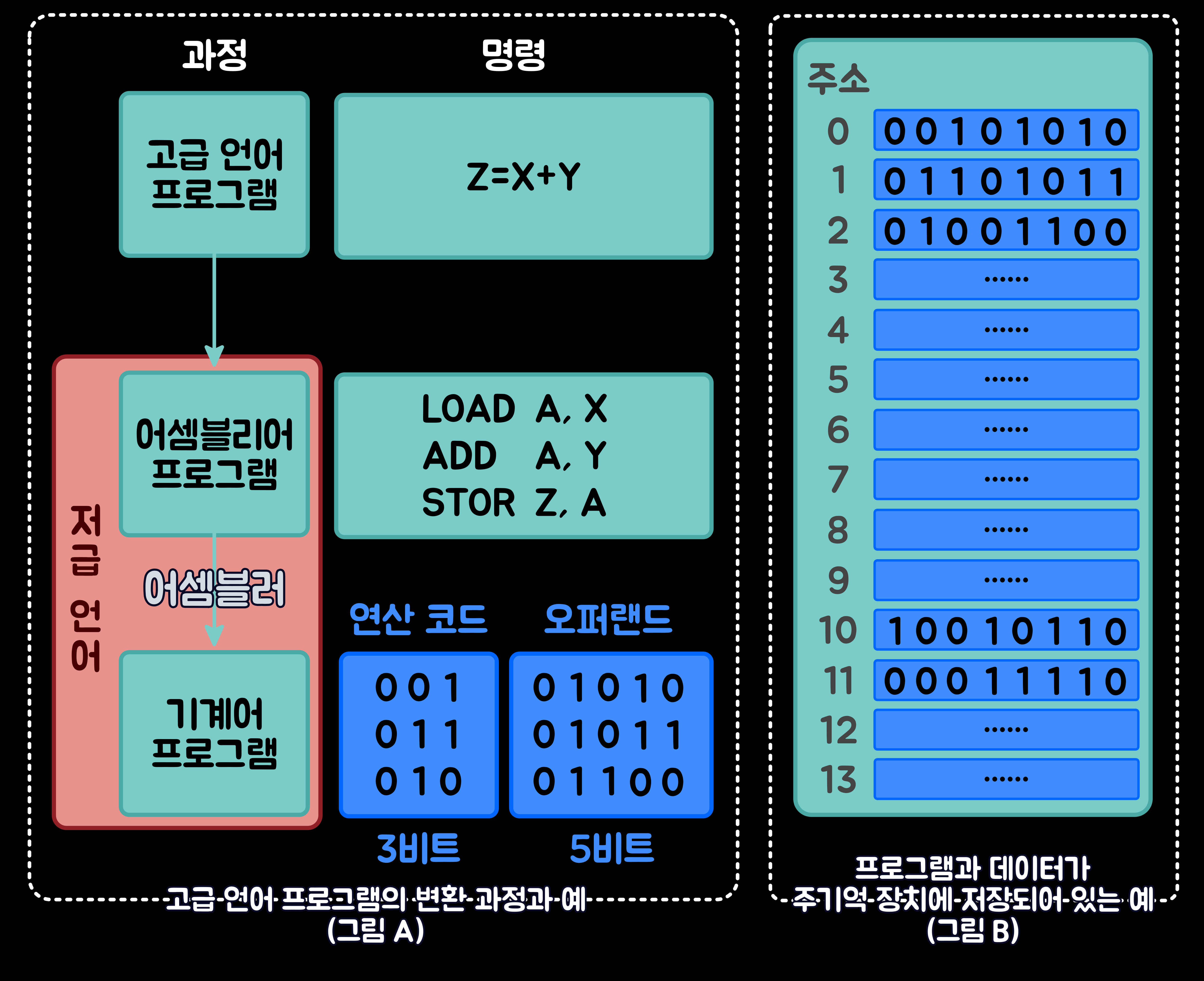
6-2. 컴퓨터 시스템의 계층 레벨
아래의 표는 '컴퓨터 시스템(Computer System)'의 추상화 레벨을 정리한 것이다. 일반적으로 '컴퓨터 구조(Computer Architecture)'에서는 레벨 0부터 레벨 2까지를 다룬다.
추상화 레벨 구성 예시 레벨 6 사용자 응용 프로그램(Application) 레벨 5 고급 언어 C, C++, 자바(Java), 포트란(Fortran) 등 레벨 4 어셈블리어 어셈블리 코드(Assembly Code) 레벨 3 시스템 소프트웨어 운영체제(OS: Operating System), 라이브러리(Library) 레벨 2 기계어 명령어 세트 아키텍처 레벨 1 제어 '하드와이어(Hardwire)' 또는 '마이크로프로그램(Microprogram)' 레벨 0 디지털 논리 '논리 게이트(Logic Gate)', '와이어(Wire)' 등 - 레벨 6: '레벨 6'은 매우 친숙한 사용자 레벨이며 '응용 프로그램' 들로 구성된다. 이 레벨에서 사용자들은 '워드 프로세서', '그래픽 패키지', '게임' 등과 같은 프로그램을 동작시킨다.
- 레벨 5: '레벨 5'는 'C', 'C++', '자바(Java)', '파이썬(Python)' 등과 같은 '고급 언어(High-Level Language)'로 구성되어 있다. 이러한 고급 언어들은 '컴파일러(Compiler)'나 '인터프리터(Interpreter)'를 사용해 컴퓨터가 이해할 수 있는 '기계어(Machine Language)'로 변환되어야 한다. 변환 과정은 먼저 '어셈블리어(Assembli Language)'로 변환되고 다시 '기계어'로 변환된다. 이 레벨에서 사용자는 하위 레벨의 일부만을 알 수 있다. 프로그래머는 데이터 유형과 명령어들을 이해해야 하지만, 데이터 유형이 어떻게 적용되는지를 알 필요는 없다.
- 레벨 4: '레벨 4'는 '어셈블리어(Assembli Language)'를 포함한다. 고급 언어로 작성된 프로그램은 먼저 '어셈블리어'로 번역되고 다시 '기계어'로 변환된다. 이것은 일대일 변환을 의미하는데, '어셈블리어 명령어 1개'가 정확히 '기계어 명령어 1개'로 변환된다는 뜻이다. 이와 같이 레벨을 분리함으로써 '고급 언어'와 '기계어' 사이의 의미적 차이를 줄일 수 있다.
- 레벨 3: '레벨 3'은 시스템 소프트웨어 레벨로 '운영체제(OS)'와 '라이브러리(Library)'들로 구성된다. 이 레벨은 '다중 프로그래밍(Multi Programming)', '메모리 할당(Memory Allocation)', '프로세스 관리(Process Management)', '기타 중요 기능'을 담당한다. 종종 어셈블리어에서 기계어로 번역된 명령어는 이 레벨을 그대로 경유하여 하위 레벨로 전달된다. 운영체제는 '펌웨어(Firmware)' 다음으로 '하드웨어'와 가장 직접적으로 관련되는 소프트웨어이다.
- 레벨 2: '레벨 2'는 '명령어 세트 아키텍처(ISA: Instruction Set Architecture)' 레벨인 '컴퓨터 시스템(Computer System)'의 특정 구조에 의해 인식되는 '기계어'로 구성되어 있다. 특정 컴퓨터에 종속적인 기계어로 쓰여진 프로그램들은 전자 회로에 의해 직접 실행될 수 있다.
- 레벨 1: '레벨 1'은 '제어(Control)' 레벨로 제어 장치가 명령어들을 '해독(Decode)'하고 실행하며, 데이터들을 이동할 시간과 장소들을 결정한다. '제어 장치'는 상위의 '레벨 2'에서 기계어 명령어를 한 번에 하나씩 읽어서 필요한 동작을 수행하기 위한 신호들을 발생시킨다. '제어 장치'는 '하드와이어(Hardwired)' 방식과 '마이크로 프로그램(microprogrammed)' 방식 중 하나로 구현할 수 있다.
- 레벨 0: '레벨 0'은 '디지털 논리(Digital Logic)' 레벨로 '컴퓨터 시스템'의 물리적인 구성 요소인 '논리 게이트(Logic Gate)'와 이들을 연결하는 '와이어(Wire)'로 구성된다. 이것들은 모든 컴퓨터 시스템에 공통되는 수학적 논리의 기본 구성 요소이다.