0. 목차
- '인공지능'이란?
- '단순 제어'에서 '딥러닝'까지
- '머신러닝'을 이용한 요소 기술
- '인공지능' 발전 방향
- '인공지능'의 부작용
- '오픈 사이언스' 움직임 가속화
- '인공지능' 정책 동향
- '인공지능' 관련 기업

1. '인공지능'이란?
'인공지능(AI: Artificial Intelligence)'는 인지, 학습 등 인간의 '지적 능력(지능)'의 일부 도는 전체를 '컴퓨터를 이용해 구현하는 지능'을 의미한다. '인공지능(AI)'는 단순 신기술이 아닌 '4차 산업혁명'을 촉발하는 핵심 동력으로 기술혁신을 통해 산업 구조의 변화를 야기하고, 사회·제도의 변화까지 유발할 것으로 전망되고 있다. '4차 산업혁명'은 2016년에 '클라우스 슈바프(Klaus Schwab, 1938~)'가 의장으로 있는 '세계 경제 포럼(WEF: World Economic Forum)'에서 주창된 용어로 '인공지능(AI)', '빅데이터(Big Data)' 등 디지털 기술로 촉발되는 초연결 기반의 지능화 혁명을 말한다. 이로 인해 산업뿐만 아니라 '국가 시스템', '사회', '삶' 전반에 걸쳐 혁신적 변화가 일어날 것으로 전망된다. '4차 산업혁명'은 컴퓨터와 인터넷으로 대표되는 정보 혁명인 '3차 산업혁명'에서 한 단계 더 진화한 혁명으로 말하기도 한다.
'사물인터넷(IoT: Internet of Things)'의 확산으로 인해, 앞으로는 무선으로 연결되지 않은 기기를 찾아보기 어려울 것이다. 이를 통해 확보한 막대한 데이터를 어떻게 활용할 것인가에 대한 문제가 인공지능 분야에서 중요하게 대두되고 있다. 일례로 IoT 기능을 갖춘 웨어러블 기기를 신체에 장착하면 맥박이나 심박수의 변화로 사람의 감정을 인지할 수 있게 되는 등, 방대한 비정형 데이터가 IoT를 통해 수집된다. 이를 통해 인공지능은 사람의 지능을 뛰어넘는 '초지능(Super Intelligence)' 단계로 진화할 것으로 전망된다.
인공지능 서비스가 제공되기 위해서는 'PC', '모바일', 'IoT'를 통해 생성되는 대량의 데이터를 확보하고, 이러한 데이터를 인공지능 기술인 '머신러닝', '시각·언어·청각 지능', '상황·감정 이해', '추론·지식 표현', '행동·협업 지능' 및 지능형 에이전트에 투입하여 '인공지능 모델(AI Model)'을 생성해야 한다. 아울러 인공지능 서비스 제공을 위해서는 대량의 데이터 학습이 필요함에 따라, '클라우드(Cloud)' 및 'CPU', 'GPU' 기반의 고성능 '컴퓨팅 인프라(Computing Infrastructure)'가 필수적으로 투입된다. 이러한 프로세스를 통해 개발된 인공지능 모델이 최종적인 서비스로 '제조', '의료', '유통', '금융' 등의 응용산업에 제공된다.
1-1. '인공지능'은 향후 기업의 승패를 좌우하는 근간
McKinsey Global Institute가 2018년에 발표한 Note From The AI frontier: Modelling The Impact of AI on The World Economy의 자료에 따르면, 인공지능은 2030년까지 전 세계 GDP에 13조 달러를 기여할 것으로 전망되었다. 이로 인해 세계 GDP가 연평균 1.2% 추가 성장할 것으로 예측하였다. 인공지능 기술은 향후 기업 성장의 성패를 좌우하는 근간으로 작용할 것이다. 기업의 인공지능 역량에 따라 매출 성과에 쏠림 현상이 발생할 것으로 전망된다.
또한 McKinsey Global Institute는 인공지능 도입이 국가·기업 간 격차를 더 벌릴 수 있다고 전망하였다. 인공지능 도입 및 흡수 정도에 따라 각 국가를 4개의 그룹으로 분류했을 때, 이 중 1그룹에 속한 글로벌 리더는 중국과 미국이다. 두 나라는 현재 인공지능의 공급 경쟁을 주도하고 있으며, 다른 나라들과 차별화되는 독특한 강점을 지니고 있다. 규모 효과는 더 큰 투자를 가능하게 하고, 네트워크 효과는 인공지능을 최대한 활용하는 데 필요한 인재들을 유치할 수 있게 하고 있다. 중국과 미국은 인공지능 관련 '특허', '논문', '인용 수' 등이 다른 나라보다 크게 앞서고 있다. 또한 '밴처캐피털(Venture Capital)', '사모펀드', '인수합병' 등 대외투자에 상당한 투자를 진행하고 있으며, 2016년 기준 GDP의 약 2~3%를 인공지능 연구개발비로 투자했다.
한국은 캐나다, 프랑스 등과 함께 두 번째 그룹에 위치하고 있다. 두 번째 그룹은 선도 기업만큼은 아니지만 일정 수준의 인공지능 기술 인프라를 갖추고 있다. 또한 두 번째 그룹에 속한 국가들 중 상당수가 둔화된 생산성을 활성화시킬 수 있는 돌파구로써 인공지능을 도입하려는 의지가 강하다. 높은 인건비를 대체할 수 있는 수단으로 활용할 예정이다.
2. '단순 제어'에서 '딥러닝'까지
'머신러닝(Machine Learning)'은 인공지능의 한 분야로, 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야를 말한다. '딥러닝(Deep Learning)'은 여러 '비선형 변환 기법(Nonlinear Transformation Method)'의 조합을 통해 높은 수준의 추상화를 시도하는 기계학습 알고리즘의 집합이다. 큰 틀에서 사람의 사고방식을 컴퓨터에게 가르치는 기계학습의 한 분야를 의미한다.
'머신러닝(Machine Learning)' 이전의 인공지능은 인공지능이 수행해야 하는 규칙들을 프로그래머가 일일이 코드를 작성해야 했다. 하지만 머신러닝 기술이 도입되면서 인공지능이 스스로 학습하고 규칙을 만들어 내고 있다. '머신러닝(Machine Learning)'이 다양한 정보를 먼저 학습하도록 하고 그 학습한 결과를 이용하여 새로운 것을 예측하도록 하는 기술이라면, '딥러닝(Deep Learning)'은 이러한 학습도 스스로 판단해 미래의 상황을 예측하는 것이다. 즉, '머신러닝'은 사람이 트레이닝 데이터를 알맞게 분류한 뒤 컴퓨터가 인식할 수 있도록 하는 것이고, '딥러닝'은 사람이 개입하지 않고 스스로 답을 내는 것이다.
뇌과학의 발전으로 인간 두뇌의 인지 프로세스와 학습하는 방식이 밝혀지면서, 인간의 두뇌를 모사한 '신경망(Neural Network)'을 학습의 주요 방식으로 사용하는 '딥러닝(Deep Learning)' 기술이 발전하였다. '딥러닝'은 두뇌가 입력 이미지를 분석할 때 기본적인 단위로부터 상위 레벨의 인지가 이루어지는 것과 유사하게 신경망을 다층 구조로 구성하는 것이다. 입력층과 출력층 사이에 하나 이상의 숨겨진 층을 쌓는 방식으로 '심층 신경망(Deep Neural Network)'을 구성함으로써 이를 기반으로 기계학습을 하는 기술을 말한다. 딥러닝의 기본 모델로는 'CNN(Convolution Neural Network)'과, 시간에 따른 시계열 데이터로 처리하는 'RNN(Recurrent Neural Network)' 등이 있고, 계속 새로운 구조가 개발되고 있다. 이들 기본 모델은 주로 이미지와 음성 데이터 학습에 적용되고 있다.
3. '머신러닝'을 이용한 요소 기술
'머신러닝'을 이용한 요소 기술에는 '시각 지능', '언어 지능', '음성 지능' 기술이 대표적이다.
3-1. 시각 지능
이미지·영상 데이터 기반의 '시각 지능'은 이미 인간 수준을 넘은 시각 인식률을 보이고 있으며, 상황을 이해하고 새로운 이미지를 생성하는 기술로까지 발전하였다. 이미지 객체 인식의 정확도를 경쟁하는 ImageNet 경진대회에서 2015년에 '마이크로소프트(Microsoft)'가 96.43%의 정확도를 달성하며, 인간의 인식률인 94.9%를 추월하였다. 그리고 2017년에는 중국의 대학팀이 97.85%의 인식률을 달성하였다. 한국의 경우, '한국전자통신연구원(ETRI: Electronics and Telecommunications Research Institute)'의 '딥뷰 프로젝트(DeepView Project)'를 통해 시각 지능 핵심기술을 개발하였으며, 2017년 ImageNet에서 사물 검출 부문 2위를 달성하였다. 이미지·영상의 외형적 특징을 통해 이해하는 기술이 발전하고 있으며, 눈·코·입 모양 등 상관관계를 분석해 표정을 이해하거나, 감정을 추측하고, 이미지 속 상황을 정확히 이해하여 언어로 표현하는 기술이 등장하고 있다.
컴퓨터 과학자 '이안 굿펠로우(Ian Goodfellow, 1987~)'에 의해 제안된 'GAN(Generative Adversarial Networks)' 기술의 등장으로 인해, 이미지 인식 기술은 데이터의 양이 부족한 환경에서도 실제와 매우 유사한 이미지를 생성하는 단계에 이르고 있다. 'SK 텔레콤'은 DiscoGAN을 개발하여, 핸드백에 어울릴만한 구두 디자인이나 패턴을 생성해 사용자에게 추천하는 기술을 선보였으며, 인공지능 최고권위 학회인 'ICML2017(The International Conference on Machine Learning)'에서 평가자 저원으로 최고점을 받았다. 한편, '네이버(Naver)'는 2개의 '판별망(Discriminant Network)'과 3개의 '생성망(Generative Network)'을 통해 구현한 StarGAN을 개발하였다. StarGAN은 '머리색', '성별', '나이', '감정' 등 여러 개의 특징을 한 번에 변화시킬 수 있는 이미지 벼환 모델로 CVPR2018 학회에서 발표되었으며, 국내 산학기관 중 유일하게 상위 2% 논문에 선정되었다.
3-2. 언어 지능
최근 '언어 지능'은 텍스트·음성 데이터 기반 학습을 통해 사람에게 의존하지 않고 스스로 언어를 이해하며, 인간의 억양과 유사한 수준으로 음성을 생성하는 단계로 진입하였다. 전문가가 단어 간의 관계를 사전에 설정하는 방식으로 전문가의 '능력', '경험', '투자 비용' 등의 한계가 있는 '온톨로지(Ontology)' 기반 기술에서 인간의 개입을 최소화하고, 데이터 기반 학습을 통해 스스로 언어를 이해하게 하는 '워드 임베딩(Word Embedding)' 방식으로 전환되고 있다.
'구글(Google)'은 데이터 기반 'word3vec'이라는 알고리즘을 개발하여, 뉴스 서비스를 통해 약 1000억 개의 단어를 기계학습에 적용하였다. 개별 단어가 아닌 구문 단위로 유사한 단어를 벡터 공간에 위치시키는 방식인 '워드 임베딩(Word Embedding)' 방식으로 구현하였다.
3-3. 음성 지능
언어 인식의 지능을 갖게 된 인공지능은 사람의 목소리를 이해하고, 생성하며, 악센트뿐만 아니라, 문장 단위에서의 억양까지 매우 정교한 수준으로 구현하고 있다. '딥마인드(Deep Mind)' 기존 최고 수준이었던 구글의 '음성 생성 기술(TTS: Text to Speech)'를 획기적으로 발전시켰다. 방대한 데이터를 통해 사람의 목소리 패턴을 분석하여 언어를 생성하는 방식이며, WaveNet 논문으로 발표되었다.
IBM 음성 인식 기술은 '딥러닝 기술'과 'WaveNet'을 결합한 모델로, 2017년에 정확도가 5.5% 에러율에 도달하였다고 발표하였다. 한편 같은 해 2017년에 '마이크로소프트(Microsoft)'의 음성인식 기술은, 음성 인식의 정확도가 5.1% 에러율에 도달해 인간 수준을 넘어섰다고 발표하였다.
4. '인공지능' 발전 방향
4-1. '사용자 중심 연구'로 치중될 전망
글로벌 기업들은 플랫폼과 상용 서비스를 활용한 대용량 학습 데이터 확보 전략을 사용하고 있다. 이에 대응하기 위해, 소규모 학습 데이터로 성능 향상이 가능하며, 다양한 분야로 도메인 확장이 가능한 '준지도·비지도 학습', '전이 학습(TL: Transfer Learning)', '강화 학습(Reinforcement Learning)', '사용자·도메인 맞춤형 적응 기술' 등의 원천기술이 필요할 것으로 전망된다. '자율로봇(Autonomous Robot)', '자율주행 자동차(Self-Driving Car)' 등의 연구를 위해서는 기계가 사람 및 환경과 상호 작용하며 학습 데이터를 스스로 만들어 낼 수 있는 능력이 반드시 필요하다.
컴퓨터가 사람처럼 생각하고 배울 수 있도록 하는 인공지능 기술 '딥러닝(Deep Learning)'의 성능이 비약적으로 발전하고 있는 가운데, '슈퍼컴퓨터(Supercomputer)'와의 결합까지 이루어져 딥러닝 분야는 인공지능 분야에서 최고의 연구 영역 중 하나가 될 전망이다. '범용 인공지능 플랫폼', '산업별 특화 인공지능 플랫폼'의 등장으로 인한 '데이터 확보' 및 '선점 경쟁'으로 인한 '사용자 중심 연구'에 치중될 것으로 예상된다.
4-2. 설명 가능한 인공지능
의사결정 과정이 설명 가능하면서, 인간 수준의 인식 정확도를 갖는 인공지능 기술 개발 육성 및 제도화 요구가 증가되고 있다. 의사 결정의 이유에 대한 설명을 요구하는 '유럽연합(EU: European Union)'의 '일반 개인정보보호법'이 2018년 5월 28일에 발효되었다. 한편, '설명이 불가능한 인공지능 기술'은 향후 중요 작업으로 여겨지는 '의료', '군사' 등 중요 작업에는 적용이 불가능할 전망이다.
인공지능의 핵심기술은 일부 상용 서비스에 제공되고 있다. 하지만 아직은 기술적 한계에 의해 분야 및 기능이 제한적이다. 본격 시장 확장을 위해서는 핵심기술 경쟁의 가속화가 필요하다. IT 분야의 전문 리서치 기업 '가트너(Gartner)'는 2018년 10대 전략기술 트렌드 중 하나로 '대화식 인공지능(Conversational AI)'을 선정하였다. 세계 기업들이 전문 분야에 대한 복잡한 대화를 인간 수준으로 이해하고 응대하기 위한 기술 개발에 초점을 맞추고 있다.
4-3. 교감형 인공지능
한국 정보통신기획평가원이 발표한 'ICT R&D 기술로드맵 2023 SW·AI·차세대 보안' 보고서에 따르면, '교감형 인공지능' 연구 지원이 필요하다. '교감형 인공지능'이란 언어적·시각적 특징을 이용한 인간의 '의도', '감정' 등의 이해를 넘어서는 '비언어적 특징의 이해', '인간-인공지능 간의 상호작용의 고도화', '라포 형성 등에 대한 고차원적 이해'가 가능한 인공지능을 말한다. 뇌과학의 입장에서는 청각·시강의 입력에 대한 반응을 분석하고, 수학적 패턴 형성을 시도하는 연구가 진행될 것으로 전망된다.
쇼핑과 고객 서비스 분야에서 기업들은 인공지능을 활용해 고개 만족도를 높이고 있다. 이에 산업 내 관련 기업을 M&A 하거나 제휴해 분야별 전문성을 높여가며 독보적인 위치를 선점하기 위해 노력하고 있다.
5. '인공지능'의 부작용
인공지능은 잘 활용하면 많은 혜택을 받을 수 있으나 '시민에 대한 무차별적인 감시와 통제', '일자리', '세금', '인공지능 윤리기준' 등의 문제가 발생하고 있다.
- 시민에 대한 무차별적인 감시와 통제: 지능화된 CCTV를 통하여 시민에 대한 무차별적인 통제가 가능해질 수 있다. '조지 오웰(George Orwell)'의 '1984'와 같이 '텔레스크린(Telescreen)'을 통해 시민을 24시간 감시와 통제를 할 수 있다.
- 일자리: 'ANI(Automatic Number Indentification)'의 단순 반복적 행정업무에 대응하는 인력의 구조조정이 가능해져, 일자리의 상실과 새로운 일자리의 창출이 필요한 문제가 있다. 단기적으로 콜센터 챗봇 활용 시 직원 해고가 아닌 직원 어시스턴트 역할을 수행토록 조정할 수 있다.
- 인명 살상용 무기 개발: '구글(Google)'은 국방부가 수집한 영상 정보를 해석하는 등 무인항공기의 공격 목표를 향상하기 위한 '메이븐 프로젝트(Maven Project)'를 중단한 사례가 있다. '메이븐 프로젝트(Maven Project)'는 구글의 인공지능 이미지 인식 기술을 활용해, '드론(Drone)'이 수집한 영상 자료를 분석하는 시스템을 개발하는 사업이다. 구글 내부에서는 인공지능 기술이 인명 살상용 무기 개발로 악용될 가능성이 높다며 중단을 요구했다. 일부 구글 인공지능 연구원들은 회사 방침에 반발하여 퇴사하기도 했다.
5-1. 인공지능 윤리기준
무인 자율주행 자동차에 의해 사고가 발생하는 것 역시 부작용 사례 중 하나다. 실제 자율주행차의 사고 발생 시 자율주행 자동차에 대한 시험 중단 및 규제 강화의 조치가 잇따르고 있다. 2015년 11월 인류 역사상 처음으로 사람이 없는 자동차가 캘리포니아주 팔로알토의 도로를 달리다 교통경찰에게 딱지를 받았다. 하지만 경찰은 운전석에서 아무도 발견할 수 없었다. '구글(Google)'의 무인 자동차가 사고를 우려해서 지나치게 저속 운행을 하고 있었던 것이다.
2023년 기준, 한국의 현행법 체계는 '사람'과 '법인'만을 권리 의무로 주체로 하고 있는데, 행위 책임을 묻기 위해서는 어떤 경우에도 '사람'의 행위가 있어야만 한다. 따라서 알고리즘 판단과 제어에 의한 자율 운행 차량의 사고는 그 책임 소재가 불분명한 문제가 있다. 가장 많이 사용되는 예로 '트롤리 딜레마(Trolley Dilemma)'가 있다. 앞서가던 트럭이 갑자기 정차할 경우 그대로 직진하여 운전자만 부상에 이르게 할 것인지, 우측으로 핸들을 돌려 길에 있는 행인 3명과 추돌할 것인지 등에 대한 선택을 해야 하는 경우를 생각해 보자. 이때, 알고리즘에 기초한 판단의 결과에 대한 책임을 누구에게 물을 수 있느냐에 대한 소재가 불분명하다.
6. 오픈 사이언스 움직임 가속화
최근 디지털 기술의 발전에 따라 영국 성과 및 자료를 개방 또는 공유하고, 온라인 플랫폼을 통해 연구자들 간 협업을 이루려는 '오픈 사이언스' 움직임이 가속화되고 있다. '오픈 사이언스(Open Science)'란 '공공연구의 성과를 디지털 형태로 공개하고 확산시켜, 그 사회경제적 편익을 제고하려는 일종의 공적 개입'으로 정의 가능하다. 이는 크게 '오픈 액세스(Open Access)', '오픈 데이터(Open Data)', '오픈 콜라보레이션(Open Collaboration)'으로 구분 가능하다. '오픈 액세스(Open Access)'는 연구 성과물 공개를 의미하고, '오픈 데이터(Open Data)'는 출판 전후로 생성된 모든 연구 데이터 공개를 의미하고, '오픈 콜라보레이션(Open Collaboration)'은 개방형 환경에서 연구자들의 협력을 의미한다.
인공지능 분야 또한 이러한 체계하에서 빠르게 발전하고 있다. 예컨대 전통적인 저널보다는 'NIPS(Neural Information Processing Systems)' 또는 'ICML(International Conference on Machine Learning)'과 같은 학술대회에서 우선적으로 연구 결과를 발표하고 있으며, '깃허브(GitHub)' 등을 통해 결과물로서의 '소스코드(Source Code)' 및 'API(Application Programming Interface)'를 공유하고 있다. 또한 '이미지넷(ImageNet)'은 영상처리와 관련된 '기계학습 데이터(Machine Learning Data)'를 무료로 공개하고 있으며, 전 세계 인공지능 연구자들은 '텐서플로우(Tensorflow)'나 '파이토치(PyTorch)'와 같은 오픈 인공지능 플랫폼을 활용하여 공동 연구를 진행하고 있다.
'소프트웨어 정책 연구소(SPRI: Software Policy & Research Institute)'가 발간한 글로벌 기업의 인공지능 연구역량 분석 보고서를 보면 'IBM', '마이크로소프트(Microsoft)', '알파벳(Alphabet)'이 인공지능 연구협력 네트워크의 중심에 위치해 있으며, 이들 글로벌 기업 간 인공지능 연구협력의 성과는 매우 높은 것으로 확인된다. '마이크로소프트'와 '메타' 공동연구의 'FWCI(Field Weighted Citation Impact)'는 25.00, '텐센트(Tencent)'와 'IBM'은 22.47로 매우 높으며, 협력연구의 FWCI는 대부분 1을 상회하고 있다.
6-1. 글로벌 기업들은 왜 오픈소스 인공지능을 출시하는가?
글로벌 기업이 오픈소스 인공지능을 출시하는 이유는 다음과 같다. 딥러닝 등 인공지능의 핵심 알고리즘은 이미 어느 정도 정립되어 있다. 따라서 알고리즘보다는 이 알고리즘이 적용되는 기반 데이터가 더욱 중요하다. 인공지능 기술은 전통적인 ICT 산업 부문을 넘어 전통산업을 포괄하는 매우 광범위한 영역으로 응용이 되며, 응용 대상 영역에서 얻어지는 사용자 피드백 등 케이스 의존적인 성격이 강하기 때문이다. 예컨대 '머신러닝'의 기본 알고리즘은 '금융', '의료', '교육' 등 모든 분야에 응용 가능하지만, 개별적인 응용 대상 분야 자체에 대한 노하우가 없으면 그러한 알고리즘이 실제로 구현될 수가 없는 것이다.
따라서 '구글(Google)'과 같은 거대 글로벌 선도기업도 혼자만의 힘으로는 인공지능 기술의 보급 확산을 달성할 수 없다. 개방형 혁신 생태계를 통하여, 다양한 분야에서 인공지능 기술을 응용하는 주체들이 모두 협력하여야만 한다. 그래야만 인공지능 기술의 확산 및 보급이 가능하다. 인공지능 선도 기업들도 개별 연구가 아닌 협력을 통해 연구를 공동 추진하고 있다. 한국도 인공지능 역량 확보를 위한 '연구 협력 네트워크 참여 확대', '글로벌 우수 기간과의 연구 지속성'이 필요한 것으로 판단된다.
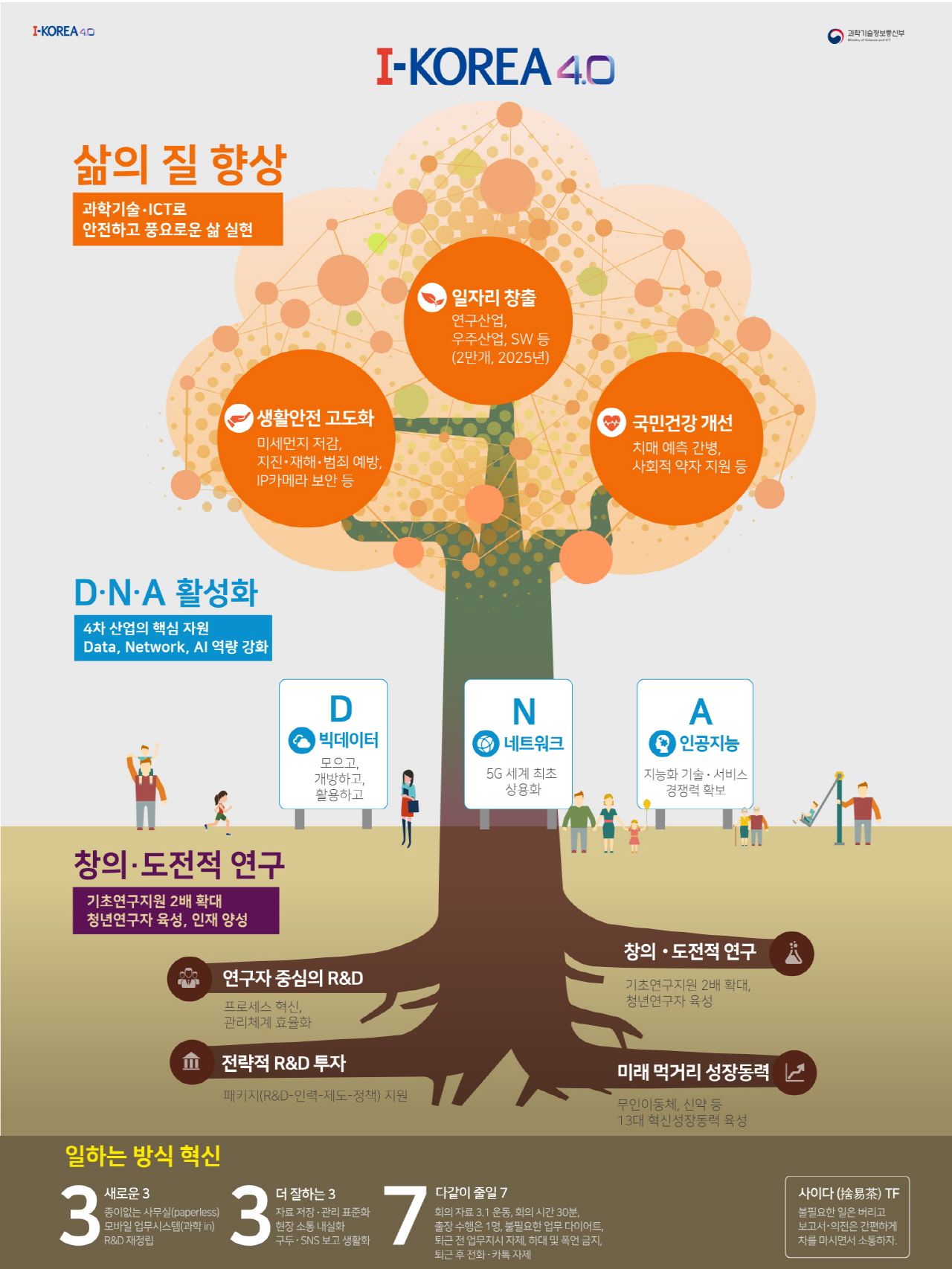
한국도 2017년에 I-KOREA 4.0을 통해 '인공지능 허브' 및 '연구거점 인공지능 브래인랩' 조성 계획 발표했다. I-KOREA 4.0은 '4차 산업혁명 대응계획'을 추진하기 위해 만든 정책 브랜드이다. 방대하고 복잡한 대응계획을 'I-Korea 4.0'이라는 브랜드를 통해 쉽게 이해하고 직관적으로 받아들일 수 있게 했다. 'I-KOREA 4.0'에서 'I'는 '지능(Intelligence)', '혁신(Innovation)', '포용과 통합(Inclusiveness)', '소통(Interaction)'을 의미한다. 이는 지능화 기술을 통한 4차 산업혁명 강국이 되겠다는 목표와 이를 실현하는 데 국민 중심의 포용, 통합, 소통을 가장 우선의 가치로 두겠다는 대응계획의 지향점을 뜻한다. 이에 기반한 기업들의 참여가 인공지능 성장에 성패를 좌우할 것으로 보인다.
7. '인공지능' 정책 동향
최근 전 세계 주요 국가는 인공지능의 이용 증진과 기슬 발전을 위한 활성화 정책을 수립하고 있다. 일련의 정책 방안들은 '핵심 원천기술 개발', '인재 양성 및 교육', '공공 및 민간 영역 적용', '윤리', '표준화', '규제', '데이터 및 디지털 인프라 제공' 등을 공통적으로 포괄하고 있다.
인공지능 원천기술 관련 정책을 발표한 국가는 '미국', '중국', '프랑스', '캐나다'이며, 주요 정책 방향은 연구센터 유치 경쟁, 정부 주도의 기술 개발이다. 가장 적극적인 국가는 프랑스이며, '에마뉘엘 마크롱(프랑스어: Emmanuel Jean-Michel Frédéric Macron)' 대통령부터 나서서 연구센터 유치에 노력하고 있다. 연구기반이 탄탄한 캐나다와 자금력이 수많은 인력이 있는 중국도 해외 우수인력과 연구센터 유치 경쟁 중에 있다.
- 캐나다: 2017년 전 세계 최초로 국가 차원의 인공지능 전략을 제시한 캐나다는 '범캐나다 AI 전략(Pan-Canadian AI Strategy)'를 통해 인공지능 연구 확산 및 인재 육성에 향후 5년간 1억 25000만 달러를 투자할 계획을 발표하였다. 이 전략은 '핵심 영역에 대한 자금 투자'나 '데이터 프라이버시(Data Privacy)', '인재교육' 등 파편화된 지원책을 제시한 것이 아닌 '토론토(Toronto)', '벤쿠버(Vancouver)', '몬트리올(Montreal)', '애드몬톤(Edmonton)' 등 지역에 국제적인 인공지능 연구 거점을 구축하는 '클러스터(Cluster)' 육성 전략을 강조했다는 점에서 특징적이다.
- 프랑스: '에마뉘엘 마크롱(프랑스어: Emmanuel Jean-Michel Frédéric Macron)' 대통령으 2018 1월 글로벌 주요 기업 경영진 140여 명을 베르사유궁으로 초청하여 '노동시장 개편'부터 '세금 인하', '규제 완화'를 약속했다. 또한 국가 전반의 혁신 기회로 인식하고, 글로벌 인공지능 선두국가 도약을 위해 2022년까지 총 15억 유로를 투자할 것을 발표했다. 또한 프랑스는 자국의 우수한 기초연구 역량·인재를 바탕으로 글로벌 기업의 인공지능 연구센터를 다수 유치, 핵심 인공지능 혁신역량을 확보하고자 노력하고 있다. 이러한 정책에 힘입어 삼성전자는 파리에 AI 센터를 설립했다.
- 미국: '미국'은 정부가 '직접 투자하는 영역'과 '간접 지원하는 영역'을 철저히 구분한 것이 특징이다. 전자의 경우 기초연구로서 '범용 AI(AGI)', '로봇(Robot)', '하드웨어(Hardware)' 등에 장기 투자하거나 '제조', '교통', '국방', '통신' 등 공공부문에 적극 투자하고 있다. 후자의 경우에는 2012년 범정부 차원의 챌린지 플랫폼 'Challenge.gov'을 구축하여, 전 산업 영역에서 도전형 과제를 제시하여, 관련 연구가 민간에 확산될 수 있도록 한 것이 대표적이다.
- 중국: '중국'은 정부 주도로 인공지능 산업 활성화를 추진하고 있다. 그 간 ICT 정책에서 자국 산업의 성장과 내수 활성화를 위해 폐쇄적인 전략을 취해온 반면, 인공지능 분야에서는 시장 개방과 오픈소스 생태계 구축을 천명하였다는 점에서 의미가 있다. 특히 인공지능 생태계에 있어서는 개방·협력형의 생태계를 조성하는 것이 중요한 과제이다.
- 독일: 독일의 정책은 인공지능의 사회경제적 확산을 전방위적으로 포괄하고 있지 않으며, 기술력 확보 차원에서 제조공정의 혁신에 집중하고 있다. 다만 초기의 'Industry4.0' 정책에서 대기업 위주의 정책에 대한 실패를 자인하면서, 중소기업 육성을 강구하고 있다는 점에서 주목할 필요가 있다. '하이테크 전략 2020'의 10대 프로젝트 중 하나로 추진된 'Industry4.0'이 처음에는 민간 주도로 추진되었으나, 중소 벤처 기업의 참여를 적절히 이끌어내지 못해 대기업 위주의 정책으로 변모되면서, 정부의 역할을 강조하는 민·관 협력 형태의 'Platform Industrie 4.0'으로 방향을 선회하였다는 것이다.
- 일본: 일본은 국가 및 사회에 만연한 문제점을 밝혀, 인공지능 관련 정책을 일관되게 추진하는 '거시적 정책 목표가 분명하다는 점'과 '매년 세부적인 시책의 진행 과정을 점검하고 구현하려는 구체성을 띤다는 점'에서 주목할 만하다. 특히 '실업률 증가', '고령화 사회 진입', '인구 감소' 등 사회 문제의 해결을 위해 인공지능 분야를 적용하려고 하고 있다. 이는 사람 중심의 혁신 성장을 강조하는 한국의 인공지능 분야 활용 취지와 유사하다.
7-1. '한국'의 정책 동향
'한국'은 시장 불확실성으로 인공지능 투자를 뒤늦게 시작해 왔으나, '공격적인 M&A', '전담조직 확대' 등으로 추격에 나섰다. 최근에는 인공지능 플랫폼 개발 상용화를 적극 추진하는 등 글로벌 시장에서의 기회 포착 가능성을 타진하고 있다. 그러나 경쟁국 대비 국내 인공지능 기술력과 전문 고급 인재의 양적 질적 수준은 여전히 취약한 것이 현실이다. 인공지능 기술혁신 인프라 역시 보완이 시급하다. 인공지능 부야 석박사급 고급인력 수가 절대적으로 부족한 가운데, 미래 수요에 대비한 고급인재 확보 전망도 불투명한 상태이다. 특히 한국의 최고 대학 연구기관의 인공지능 연구원 수는 미국·유럽 등 인공지능 기술선 도국 뿐 아니라, 급부상 중인 중국에도 뒤처지는 상황이다.
4차 산업혁명이 도래함에 따라, 급변하는 패러다임에 대응하기 위해 한국 정부는 주요 핵심 기술인 인공지능 분야에 대한 전략 수립 및 대규모 'R&D(Research and Development)'를 추진 중에 있다. 대통령 직소 4차 산업혁명위원회가 '4차 산업혁명 대응계획(2017년 11월)'을 확정·발표한 가운데, 국내 인공지능 R&D 경쟁력 확보를 위한 'AI R&D 세부 전략(2018년 05월)'을 발표하여, 인공지능 기술로 인한 새로운 변화를 창출하기 위한 청사진을 제시하고 있다. 또한 '데이터 가치사슬 전주기 화성화', '세계적 수준의 인공지능 혁신 생태계 조성', '데이터 인공지능 융합 촉진'으로 데이터·인공지능 선도국가로 도약하고자 하는 혁신성장 전략투자의 일환으로 '데이터·AI 경제 활성화 계획(2019년 1월)'을 발표하였다. 이 계획은 이후 5년 동안 '데이터의 수집·유통·활용 전 단계 활성화', '세계적 수준의 인공지능 생태계 조성', '산업 전 분야의 인공지능 간 융복합을 촉진'하는 9개 정책 과제를 포함하고 있다.
이 외에도 인공지능기술 역량의 조기 확보를 위한 대규모 R&D 과제를 추진하고 있다. 특히 시각·언어 등의 기술 개발 중심의 국가전략 프로젝트를 추진하여 인공지능 핵심 기술을 확보하고, 경제적·사회적 대응을 위한 정책을 추진하고 있다. 또한 고위험·차세대 기술 분야에 대한 인공지능 기술력을 확보하기 위해, '중장기 투자 지원' 및 '범용 기술 중심의 연구'를 추진하고 있다. 아울러 인재 양성 및 인프라를 지원하여 세계적 수준의 인공지능 기술력 및 R&D 생태계 확보를 위한 비전을 제시하고 있다.
2015~2017년에는 인공지능 SW 주요 과제로 'SW 컴퓨팅 산업 원천 기술 개발'의 '딥뷰(Deep View, 시각 지능)'와 '엑소 브레인(Exobrain)'이 있다. 또 2017년 '국가전략프로젝트(인공지능)'에서는 '설명 가능한 딥 기계학습 추론 프레임워크 개발' 등이 있다. 또한 신기술·신산업 창출을 위해 각종 규제를 유예하거나 면제하는 '규제 샌드박스(Regulatory Sandbox)'를 도입하였다. '규제 샌드박스'를 통해, 각종 데이터를 개발하고 전문 대학원을 개소하는 등 '조기 적용', '데이터(Data)', '컴퓨팅(Computing)' 등 개발 인프라 및 사업 집중 지원 등을 통해 신기술 도전·상용화의 장으로 정착하고 있다.
8. '인공지능' 관련 기업
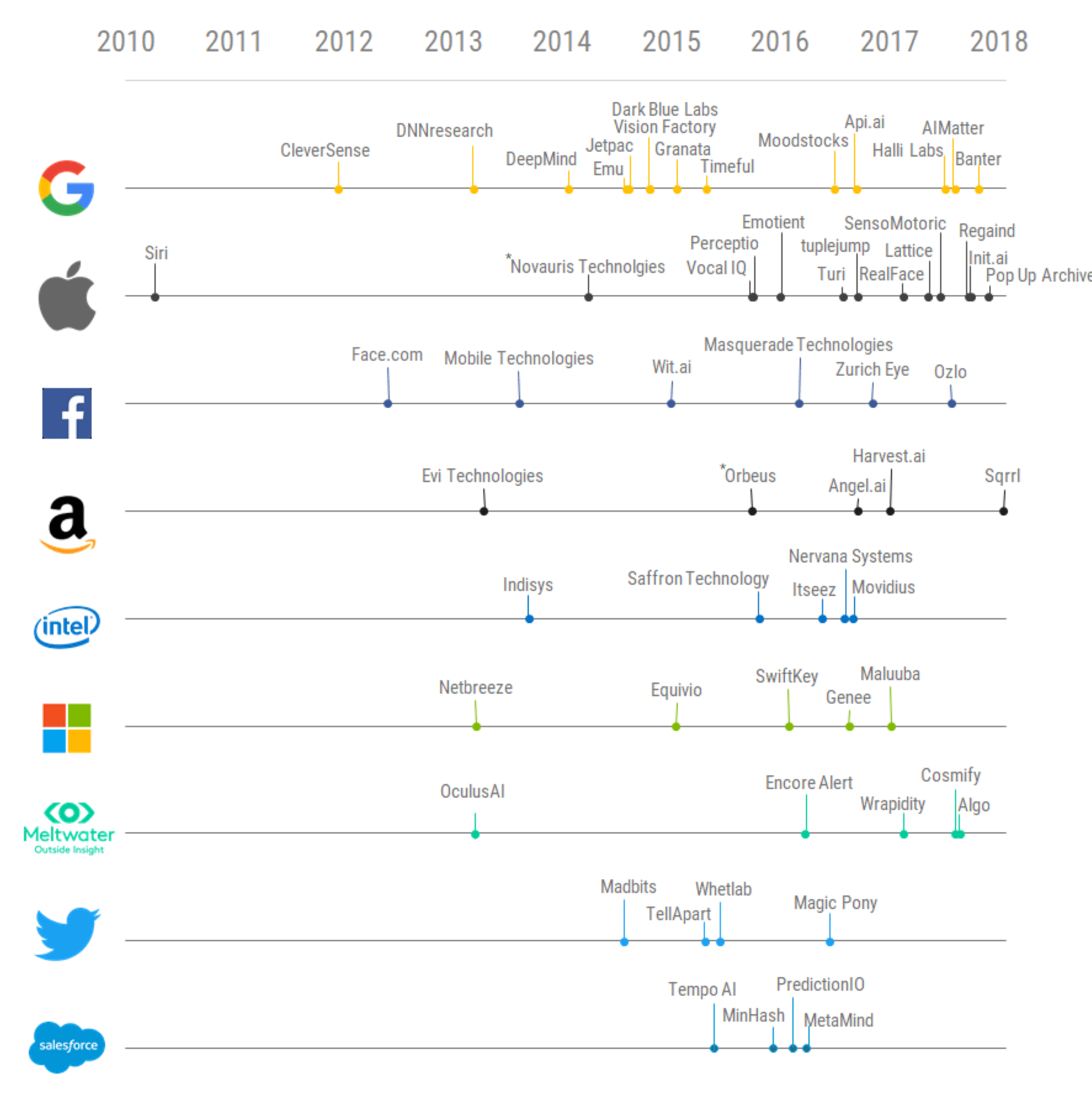
소매업에서 농업에 이르기까지 모든 산업 분야의 대기업들이 인공지능을 제품에 통합하려고 하고 있다. 하지만 인공지능 관련 개발자 및 인프라가 부족한 상황이다. 이로 인해 '구글(Google)', '애플(Apple)', '메타(Meta)' 등의 주요 해외 IT 업체들은 기술력과 인재 확보를 위해 전 세계 인공지능 스타트업을 적극적으로 인수하고 있다. 인공지능 분야 글로벌 스타트업의 수는 2018년 10월 기준, 약 5200개로 추정되며, 2018년 2월 기준 115개 스타트업이 '구글', '애플' 등 대기업에 인수된 것으로 조사되었다.
8-1. 딥마인드(DeepMind)
- 국적: 영국
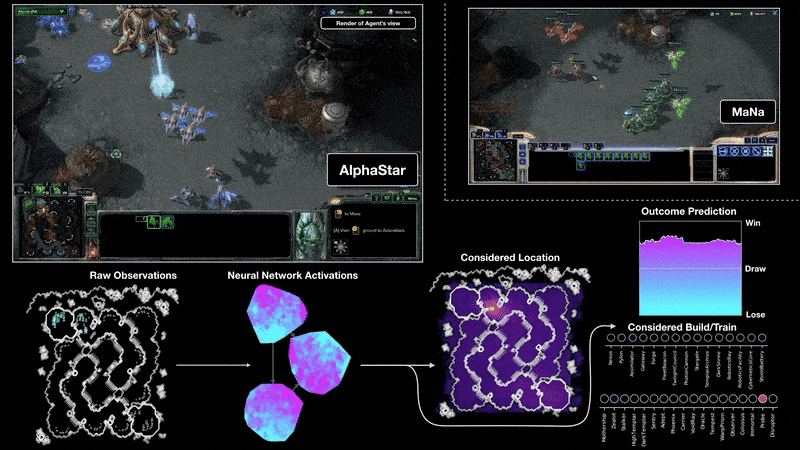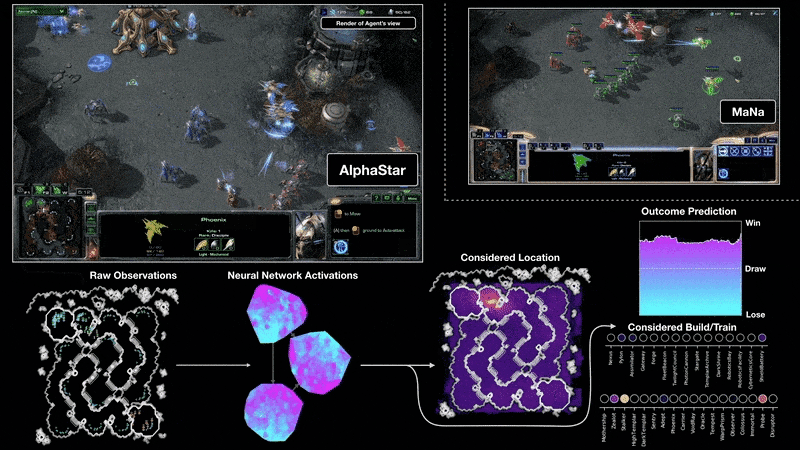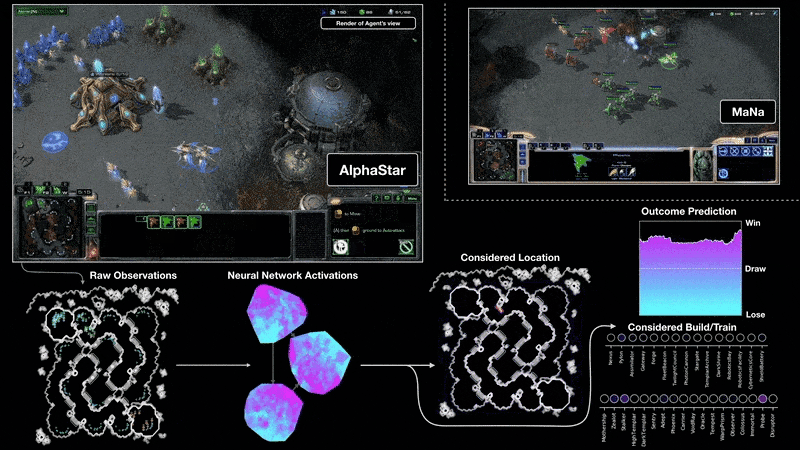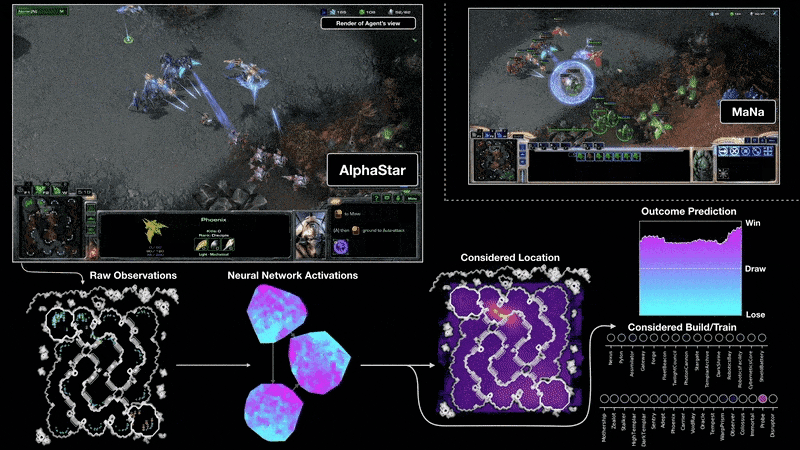
'딥마인드(DeepMind)'는 2011년에 설립된 인공지능 프로그램 개발 업체로, '딥러닝(Deep Learnign)' 기술을 이용한 인공지능 플랫폼 '알파고(AlphaGo)'를 개발하였으며, 문자-음성 변환 시스템 '태코트론(Tacotron 2)'를 개발하여 인공지능 업계를 주도하였다. 2019년 1월에는 개발 중인 '스타크래프트2(Starcraft 2)' 인공지능 '알파스타(Alpha Star)'로 프로게이머들과 대결하여 10대 1의 승리를 거둔 바 있다. 2019년 4월에는 의료진처럼 복잡한 안구질환을 실시간으로 정밀 진단할 수 있는 'AI 의사' 상용화에 성공하였다.
8-2. 메타(Meta)
- 국적: 미국
'페이스북(FaceBook)'은 2004년에 설립된 세계 최대의 '소셜 네트워크(Social Network)' 서비스 기업이다. '페이스북'은 자사의 플랫폼에 업로드되는 방대한 '빅데이터 이미지(Big Data Image)'를 이용해 얼굴 인식용 인공지능 솔루션인 '딥페이스(Deepface)'를 개발하였다. 2019년 2월 Facebook은 알고리즘 학습 능력을 높이기 위해, 기존 디자인과 전혀 바른 방식으로 작동하는 새로운 종류의 인공지능 반도체 칩 개발계획을 밝혔다. 한편, '페이스북(Facebook)'은 2021년에 '메타(Meta)'로 사명을 바꾸었다.
8-3. 애플(Apple)
- 국적: 미국
'애플(Apple)'은 2016년에 '러스 살라쿠트디노프(Russ Salakhutdinov)'를 인공지능 책임자로 영입하였으며, 머신러닝 벤처기업인 '투리(Turi)'와 인공지능 분야 스타트업 6개 이상을 인수하였다. '애플'은 2014년부터 '타이탄 프로젝트(Titan Project)'라는 이름으로 자율주행차를 개발하고 있다. 2018년 1년간 5000명 이상의 직원을 이 프로젝트에 투입하고 '더그 필드(Doug Field)' 전 '테슬라(Tesla)' 엔지니어링 책임자를 '프로젝트 매니저(Project Manager)'로 임명하였다. 아울러 2019년 9월에는 캘리포니아 주 당국의 규제로 인하여 정상적인 운영을 할 수 없는 자율주행 스타트업 'Drive.ai'를 인수하였다.

8-4. IBM
- 국적: 미국
IBM은 '왓슨(Watson)'이라는 인공지능 플랫폼을 만들었다. '왓슨(Watson)'은 2011년 미구의 유명 퀴즈 방송에 출연하여 74번 연속 승리를 한 참가자, 가장 많은 우승 상금을 획득한 참가자와 대면하여 압승을 거두었다.
IBM은 이후 금융, 쇼핑, 법률 분야에 진출하였다. IBM의 'Watson for Ontology' 기술은 방대한 양의 의료 데이터를 분석하여 의사의 의학 판단을 돕는 의료용 인공지능이다. 'Watson for Ontology' 기술은 'IBM 왓슨 닥터(IBM Watson Doctor)'로 상용화되어, 미국 뉴욕 '슬론 케터링 암센터(Sloan Kettering Cancer Center)'와 'MD 앤더슨 암센터(MD Anderson Cancer Center)'에서 암 진단과 최적의 치료법 검색 등에 이용되고 있다. 한국에서도 '가천대 길병원', 'SK 주식회사' 등에서 암진단과 치료 등에 활용하기 위해 Watson for Ontology 기술을 도입하여, 2016년 10월부터 활용 중에 있다. 다만, 1~2년 정도 지나 세계 의료 시장에서 성능을 한계를 드러냈다. 가천대 길병원이 도입 1주년을 맞아 발표한 연구결과에서도 의료진과 왓슨의 의견 일치율은 55.9%였으며, 4기 위암 환자에 대한 의견 일치율은 40%에 그치는 수준에 머물렀다.
8-5. 켄쇼 테크놀로지(Kensho Technologies)
- 국적: 미국
'켄쇼 테크놀로지(Kensho Technologies)'는 금융 업계에 사용되는 인공지능 알고리즘을 개발하는 업체이다. '자연어 처리(Natural Language Processing)'와 '머신러닝(Machine Learning)' 등의 기술을 활용한 '시장 동향 분석', '투자 조언' 등의 기능을 제공하고 있다.
2018년에 한국의 유진자산운용은 '켄쇼 테크놀로지(Kensho Technologies)'와 플랫폼 사용 라이선스 계약을 체결한 '로보 어드바이저(Robo-Advisor)' 회사 '디셈버앤컴퍼니(December & Company)'와 업무 제휴를 체결하고 '유진 챔피언 뉴이코노미 AI 4.0 주식 펀드'를 출시하였다.
8-6. 아마존(Amazon)
- 국적: 미국
'아마존(Amazon)'은 '알렉사(Alexa)'라는 음성인식 인공지능 비서를 개발하였다. '알렉사(Alexa)'는 문자를 음성으로 바꿔주는 기술인 'TTS(Text to Speech)' 기술에 '딥러닝(Deep Learning)'을 결합한 것이다. 2019년 기준, 아마존과 협력하고 있는 제조사는 3500여 개가 넘으며, 알렉사와 연동 가능한 기기는 2만 개 이상으로 파악된다. 아마존은 2018년 9월 인공지능 플랫폼 알렉사가 적용된 '전자레인지', '차량용 인공지능 스피커', '벽시계', '스피커용 앰프', '스마트 플러그(Smart Plug)' 등 13종의 기기를 발표하였다. 세계 최대 전자상거래 업체인 '아마존'이 인공지능 가전제품 시장에 뛰어든 만큼, 파급력이 상당할 것이라는 전망이 나왔다. 'LG전자'도 '알렉사(Alexa)'를 적용한 '냉장고', 'TV' 등의 가전제품을 출시하고 있다.
8-7. 레노버(Lenove)
- 국적:중국
중국의 PC 업체 '레노버(Lenove)'는 2018년부터 인공지능 무인 편의점 '레노버 러쿠 언맨드 스토어(Lenove Lecoo Unmanned Store)' 정식 운영에 돌입하였다. 인공지능 얼굴인식 기술로 얼굴 등록을 마치면, IoT 기술을 통해 자동으로 소비자 손에 있는 상품을 검측하게 되고, 얼굴인식을 통해 계좌를 찾아 소비자가 매장을 나서면 자동으로 결제되도록 구현된 시스템이다. '레노버'는 PC, 스마트홈 기기' 등을 제조하는 업체로 인식되어 왔으나, 새로운 유통 구조에 맞춰 사업을 확장하고 있다.
8-8. 텐센트(Tencent)
- 국적: 중국
'텐센트(Tencent)'는 2018년 9월에 인공지능 개방 플랫폼 'AI.QQ.COM'을 발표하였다. '텐센트(Tencent)'는 'AI 랩(AI Lab)'과 '위챗 AI(WeChat AI)' 등에서 지금까지 축적한 인공지능 기술을 집대성해, 100여 가지의 인공지능 인터페이스를 오픈하였다. 오프라인 인공지능 액셀러레이터와 인공지능 창업자 지원을 강화하면서, 인공지능 개방형 생태계를 적극적으로 조성하겠다는 의지를 내비친 것이다.
'텐센트(Tencent)'의 인공지능 연구는 '머신러닝(Machine Learning)', '컴퓨팅 비주얼(Computing Visual)', '음성인식(Voice Recognition)', '자연어 처리(NLP: Natural Language Processing)' 등 4가지 영역에 초점을 두고 있다. '텐센트'는 인공지능 사업의 일환으로 인공지능 생태 기반의 거위 농장을 운영 중에 있으며, 거위 얼굴인식에 인공지능 기술을 접목하여 사육 효율을 높이고 있다.
8-9. Inkitt
- 국적: 독일
Inkitt는 회원들이 직접 자신이 창작한 스토리를 홈페이지에 등록하고, 다른 회원과 함께 독서 경험을 공유하는 플랫폼이다. 편집자 대신 '빅데이터(Big Data)'와 '인공지능(AI)'을 활용해 독자들의 '행동 데이터(Behavior Data)'를 분석하고 이러한 고객 데이터를 바탕으로 '베스트셀러(Best Seller)'를 예측하고 책을 출판하는 신생 출판사이다.
8-10. 네이버(Naver)
- 국적: 한국
'네이버(Naver)'는 포털 운영을 통해 축적한 '빅데이터(Big Data)'를 기반으로 범용적으로 활용될 수 있는 지능형 개인 비서를 개발하고 글로벌 기업들과 맞대결하고 있다. '네이버 앱'의 음성검색 엔진 '클로바(CLOVA)'와 안면인식 카메라 앱인 '스노우(Snow)'를 통해 시각·청각 정보 수집·분석 기술력을 확보하였다. '자연어 처리·대화'는 '네이버-i', 기계학습 기반 번역은 '파파코(Papago)', 검색·추천은 'AiRS' 등 개별 서비스로 제공하고 있다. '음성인식', '이미지 인식', '대화형 엔진' 등이 통합되어 있으며, 스마트폰 앱 뿐 아니라 다양한 기기와 연동이 가능하다.
8-11. 카카오(Kakao)
- 국적: 한국
'카카오(Kakao)'는 인공지능 기술을 중심으로 모든 것을 연결하는 기업으로 발전하고 있다. '데이터 커넥션 부서'와 '인공지능 기술 개발 부서'를 묶어 인공지능 부문으로 통합하고 있다. 카카오는 사전 등록한 특정인의 목소리만을 구별하는 화자 인식 기능을 도입하여, 자사 인공지능 스피커 '카카오 미니'와 '카카오톡'의 결합 강화에 활용하고 있다. 한편, 카카오는 현대기아차와 협업하여 자동차에 '카카오!'를 활용한 서버형 음성인식 기술을 탑재한 상용화 실적을 보유하고 있다.
카카오는 2018년 1월, 국내 업계 최초로 인공지능 개발자들이 알고리즘 설계 시 준수해야 할 사항을 명문화한 인공지능에 관한 윤리규범을 제정·발표한 바 있다.
8-12. 솔트룩스(Slatlux)
- 국적: 한국
'솔트룩스(Slatlux)'는 인공지능과 빅데이터 기술 융합을 통한 혁신 플랫폼과 지능형 서비스를 제공해온 업체이다. '솔트룩스'는 2016년에 인간처럼 학습 및 추론을 할 수 있는 인공지능 플랫폼 '아담(ADAM)'을 출시하여 상용화하였다. 2018년에는 사용자들이 스스로 개개인의 취향과 성격을 반영해 특화시키고 진화시켜 나갈 수 있는 인공지능 기반의 '가상 아바타(Virtual Avatar)' 서비스 기술인 '에바(EVA)'를 선보였다.
8-13. 셀바스 AI
- 국적: 한국
'셀바스 AI'는 필기인식 솔루션 업체로, '스마트폰', '태블릿' 등 휴대 단말기 입력 솔루션의 국산 기술을 확보해 외산 솔루션 시장을 대체하였다. '셀바스 AI'는 인공지능 의료 녹취 솔루션 '셀비 메디보이스(Selvy MediVoice)'를 2018년 9월 대구 파티마병원에 공급 계약을 체결하며, 국내 업체 최초로 의료 녹취 솔루션을 상용화하였다.
8-14. 엑셈(Exem)
- 국적: 한국
'엑셈(Exem)'은 국내 인공지능 대표기업 중 하나로, '빅데이터(Big Data)', '인공지능(AI)', '애플리케이션 성능 관리' 전문 기업이다. 2015년 6월 '코스닥(KOSDAQ)'에 상장하였다.
'엑셈(Exem)'은 2019년 4월, 인공지능 기반의 차세대 IT 운영 솔루션 '엑셈 에이아이옵스(EXEM AIOps)'를 상용화했다. '엑셈 에이아이옵스'는 딥러닝 기반 학습과 분석으로 IT 인프라 운영 상황을 예측하고 선제적 장애 대응을 지원하는 솔루션으로, '웹 애플리케이션 서버(WAS: Web Application Server)', 'DB' 등 개별 단위 모니터링 솔루션에서 한 단계 진화한 통합 IT 운영 관리체계를 지원하고 있다. '엑셈 에이아이옵스(EXEM AIOps)'는 'AI 엑스포 코리아 2019'에 참석하여 직접 체험해 볼 수 있는 전시 부스를 운영하였으며, 여러 관계자들의 주목을 받았다.
한편, '엑셈'은 행정안전부의 지능형 전자정부 정책으로 사업 기회가 넓어질 것으로 전망되고 있다. 행정안전부가 빅데이터 분석 기술을 행정에 도입해, 전자정부 시스템의 행정력을 높이는 '지능형 전자정부 정책'을 추진하는 데 속도를 내기로 하였다. 이에 따라 관련 업체인 '엑셈'의 성장도 기대된다.
8-15. 아임클라우드
- 국적: 한국
'아임클라우드(Imcloud)'는 인공지능 채팅봇 '에디(Addie)'를 출시하여, 콜센터로 문의하는 고객들의 질의에 자동으로 답변하고 있다. 아임클라우드 사내 고도화된 '그래픽 처리 장치(GPU)'를 기반으로, '딥러닝(Deep Learning)', '대화 플로우(Conversation Flow)', '빅데이터 및 클라우드 병렬처리 기술' 등의 집약체로, 기존 콜센터 고객들의 질문 패턴 중 100여개의 토픽을 파악해 응답이 가능하다. 학습과 응대 경험을 통해 패턴 분석을 정밀화하고 있다.
8-16. SK텔레콤
- 국적: 한국
'SK텔레콤'은 실생활 인공지능 플랫폼 기반 음성인식 서비스 '누구(NUGU)'를 개발하여, 사용자 언어의 문장 형태를 알아듣는 '음성인식' 및 '자연어 처리', 스스로 학습을 통해 진화하는 '딥러닝(Deep Learning)' 등 인공지능 기술을 바탕으로 다양한 서비스를 제공하고 있다. SK텔레콤은 2017년, 우성건영이 짓는 오피스텔에 '누구(NUGU)'와 '스마트 스위치(Smart Switch)', '스마트 플러그(Smart Plug)', 'SOS 버튼(SOS Button)' 등을 연동한 IoT 기반 '스마트홈 서비스(Smart Home Service)'를 제공한 바 있다.
8-17. LG전자
- 국적: 한국
'LG전자'는 LG그룹의 주력 계열사로, 가전제품 및 모바일 통신기기를 제조하는 업체이다. '음성 인식', '영상 인식', '센서 인식' 등을 연구해 온 '인텔리전스 연구소'를 각각 인공지능을 전담하는 '인공지능 연구소'와 로봇을 전담하는 '로봇 선행 연구소'로 분리 확대하여 'LG 씽큐(ThingQ)'를 개발하였고, 이를 가전제품과 스마트폰에 탑재하고 있다. LG전자가 선보인 '씽큐 TV'는 사용자 음성으로 TV를 손쉽게 제어할 수 있으며, 영상을 분석해 '명암비', '선명도', '입체감' 등을 자동으로 조정하도록 학습되어 있다.
8-18. 한컴 MDS
- 국적: 한국
'한컴 MDS'는 '한글과컴퓨터' 그룹 계열사로, 1994년에 설립된 '임베디드 솔루션(Embedded Solution)' 전문기업이다. 주요 사업은 시스템 개발 기간은 단축하고 개발 효율성을 높이는 데 필요한 '토털 솔루션(Total Solution)'을 제공하는 것이다. 현재 '인공지능(AI)', '사물인터넷(IoT)', '빅데이터(Big Data)', '클라우드(Cloud)', '로봇(Robot)' 등 4차 산업혁명 핵심 기술을 접목하여 기존 '임베디드 시스템(Embedded System)' 기술과 시너지를 창출할 수 있는 분야로 영역을 확대해 가고 있다.
'한컴 MDS'는 2014년에 빅데이터 업계의 '구글(Google)'이라 불리는 '스플렁크(Splunk)' 사업권을 확보함에 따라 '머신러닝', '인공지능', 'IoT' 등 IT 분야로 사업을 다각화하고 있다. '스플렁크(Splunk)'는 캘리포니아주 샌프란시스코에 위치한 미국의 다국적 기업으로, 기계가 생성한 '빅 데이터(Big Data)'를 웹 스타일 인터페이스를 통해 '검색(Search)', '모니터링(Monitoring)', '분석(Analysis)'하는 소프트웨어를 개발하고 있다.
8-19. 플리토(Flitto)
- 국적: 한국
'플리토(Flitto)'는 2019년 7월에 코스닥 시장에 상장된 '사업모델 특례상장' 1호 기업이다. '플리토'는 번역 플랫폼이라는 독창적인 사업을 앞세워 이 제도를 적용받았다. '플리토(Flitto)'는 집단지성 및 검수 과정을 거쳐 정제한 후, 이러한 언어 데이터를 필요로 하는 국가 연구기관 또는 IT 산업 내 다양한 기업 고객 등에게 판매하는 사업을 영위하고 있다. '플리토'는 영어, 중국어, 스페인어, 독일어 등 전세계 25개 언어 번역 서비스를 제공한다. 플리토 고객사에는 '현대자동차', '네이버(Naver)', '카카오(Kakao)', 'CJ E&M' 등 국내 기업뿐만 아니라 '텐센트(Tencent)', '구글(Google)', '샤오미(Xiaomi)'와 같은 해외의 대기업도 있다.