-
데이터 시각화(Data Visualization)과학(Science)/산업 (Industry) 2023. 8. 24. 11:09
'데이터 시각화(Data Visualization)'는 나열된 데이터를 지식화하기 과정으로, 데이터가 의미하는 바를 직관적으로 이해할 수 있도록 표현할 수 있도록 표현하는 기술이다. '데이터 시각화'를 통해 대량의 데이터를 동시에 전달할 수 있도록 지원하고, 새로운 관점의 지각적 추론을 가능하게 하며, 정보의 빠른 확산을 유도할 수 있다. 최근에는 '데이터 시각화(Data Visualization)' 기술이 '빅데이터(Big Data)', '인공지능(AI)', '가상현실(VR)' 기술 등과 접목되어, 대량의 데이터를 효과적으로 전달하는 방향으로 진화하고 있다.
0. 목차
- '데이터 시각화'란?
- 빅데이터 기술
- 시각화 기법
- '데이터 시각화' 관련 기업

데이터 시각화(Data Visualization) 1. '데이터 시각화'란?
단순 통계치나 복잡한 표로 만들어진 데이터는 이해하기가 쉽지 않을뿐더러, 이를 바탕으로 신속한 의사결정을 내리기 어렵기 때문에 '데이터 시각화(Data Visualization)'라는 과정이 필요하다. '빅데이터(Big Data)'는 단순한 선형적 구조로 표현하는 것이 어렵기 때문에, 각 데이터의 특성에 맞는 시각화 방식을 이용한다. 다양한 시각화 방식을 통해 정보 전달 시간을 단축하고, 빅데이터에서 도출된 유의미한 정보를 효과적으로 전달할 수 있다. '빅데이터 시각화'는 '정보 시각화'를 기반으로 하고 있으며, 전달하고자 하는 데이터의 특성에 따라 '시간 시각화', '분포 시각화', '관계 시각화', '비교 시각화', '공간 시각화' 등이 활용될 수 있다.
- 시간 시각화: 시간에 따른 데이터의 변화를 시각적으로 표현하는 방법 (예 : 누적 막대 그래프)
- 분포 시각화: 데이터를 전체 관점에서 부분들의 분포로 시각적으로 표현하는 방법 (예 : 원 그래프)
- 관계 시각화: 데이터 세트 간의 유사성, 상관관계를 표현하는 방법 (예 : 산점도, 버블 차트)
- 비교 시각화: 여러 가지 변수를 동시에 비교하는 방법 (예 : 방사형 차트)
- 공간 시각화: 지도를 활용하여 시각화하는 방법 (예 : 통계 주제도)
효과적인 데이터 시각화를 위해서는 시각화된 데이터로 전달하려는 메시지가 무엇인지를 명확히 결정하고 불필요한 부분들은 생략하여 단순, 명료하게 정보를 전달해야 한다. 이를 위해서는 도구의 사용법뿐만 아니라 예술적 감각, 데이터로 소통하고자 하는 사람에 대한 이해와 관심 그리고 많은 경험이 복합적으로 필요하다.
반응형2. 빅데이터 기술
'빅데이터(Big Data)'는 '규모(Volume)', '다양성(Variety)', '변동성(Velocity, 데이터 변동 속도)'이 모두 커서 기존의 방식으로는 분석하기 어려운 디지털 데이터를 의미한다. 여기서 말하는 기존 방식이란 숫자 데이터를 정형화된 형태로 저장하고, 모집단의 특성과 추세를 통계적으로 분석하는 것을 의미한다. '빅데이터'는 수치화가 어렵고 형태가 다양하고 빠르게 변화하는 비계량적인 비정형 변수들을 포함한다. 빅데이터 분석은 이렇게 비정형 데이터들에 대한 분석이 주를 이루기 떄문에 분석 결과가 특정 값으로 나타나기보다는 시각화된 형태로 나타나는 경우가 많다.
'빅데이터'는 4차 산업혁명의 핵심 요소로 자리 잡고 있다. '빅데이터'는 특히 '인공지능', '사물인터넷', '증강현실', '가상 현실', '자율주행차', '5세대 이동통신' 등 향후 주목받는 신산업의 필수적인 요소로 평가되고 있다. 이에 따라 세계 각국은 '데이터 수집' 및 '데이터 분석' 기술 활성화에 수많은 노력을 기울이고 있다. 한국도 '데이터 3법 개정(2020년 8월 15일부터 시행)'과 '한국판 디지털 뉴딜 추진'을 시작으로 정책 및 제도 개선을 위한 노력을 기울이고 있다. 예를 들어, 한국 정부는 민간 수요가 높은 국세청 등 정부 기관의 핵심 데이터를 개방하거나, 인공지능 모델 학습을 위한 학습용 데이터를 정부 주도로 구축하는 등의 정책을 펼치고 있다. 즉, 빅데이터 기술 수준이 4차 산업혁명의 신기술 수준 그리고 신산업 발전에 직결되면서, 데이터와 데이터 가공 기술은 국가 산업 발전의 경쟁력이 되고 있다.
데이터를 지배하는 기업이 4차 산업혁명을 주도할 것이라는 예측이 나오고 있으며, 데이터를 경쟁자보다 더 잘 활용하는 기업들이 2020년대의 산업을 주도하고 있다. '아마존(AMAZON)'의 경우, 이용자의 패턴을 빅데이터로 분석·예측하고 배달해 주는 기술을 적용하였으며, '지멘스(SIEMENS)'의 경우 스마트 공장의 센서 데이터를 이용하여 불량을 최소화하는 기술을 활용하고 있다. 데이터 활용뿐만 아니라, 데이터 생태계를 주도하려는 기업들의 노력도 상당히 진행되고 있다. 글로벌 대기업들은 스스로 데이터를 확보할 수 있는 생태계를 구축하고, 참여 기업에 이익을 공유하는 방식으로 비즈니스를 확립 중이다. '구글(Google)', '아마존(Amazon)', '애플(Apple)', '페이스북(Facebook)' 등은 '자사 플랫폼', '기업', '가입자 데이터'를 연결하여 지속적으로 사업 영역을 확장시키고 있다.
빅데이터 기술은 데이터를 수집·저장·처리·분석하고, 분석된 데이터를 시각화하는 기술을 의미한다. 빅데이터는 기존의 단순한 선형적 구조로 표현하는 것이 어렵기 때문에 데이터의 분석뿐만 아니라, 분석된 데이터의 시각화가 매우 중요하다.
2-1. 빅데이터 수집
'데이터베이스(Database)'는 특정 그룹이나 조직의 내부와 외부에 존재하는 데이터들의 수집을 기반으로 생성된다. 빅데이터 수집은 '로그 수집기(Log collector)', '센싱(Sensing)', '크롤링(Crawling)', '오픈 API(Open API)' 기술을 통해 수행된다.
- 로그 수집기(Log collector): '로그 수집기'를 통해 조직 내부에 존재하는 웹 서버의 로그를 수집하고 '웹 로그(Weblog)', '트랜잭션 로그(Transaction Log)', '클릭 로그(Click Log)', '데이터베이스 로그(Database Log)' 데이터 등을 수집할 수 있다.
- 센싱(Sensing): '센싱' 기술은 '스마트팩토리(Smart Factory)' 등에 있는 센서를 통해 데이터를 수집하는 기술을 의미한다.
- 크롤링(Crawling): '크롤링' 기술을 주로 웹 로봇을 이용하여 조직 외부에 존재하는 '소셜 데이터(Social Data)' 및 '인터넷 데이터(Internet Data)'에 공개되어 있는 자료를 수집해오는 기술을 의미한다.
- 오픈 API(Open API): '오픈 API' 기술은 데이터의 생산·공유·참여 환경인 웹을 구현하는 프로그래밍 기술을 통해 필요한 데이터를 수집하는 기술을 의미한다.
2-2. 빅데이터 저장 및 처리
작은 데이터라도 모두 저장하고 실시간으로 데이터를 처리할 수 있도록, 대부분 '분산 저장 시스템'을 활용한다. 저장된 데이터들을 실시간으로 처리하기 위해 '분산 병렬 처리' 방식을 주로 활용하며, 일반적으로 '하둡 분산 파일 시스템(Hadoop Distributed File System)'을 통해 이기종 간의 하드웨어로 구성된 '컴퓨터 클러스터(Computer Cluster)'에서 대용량 데이터 처리를 수행한다.
'빅데이터 처리'는 빅데이터에서 유용한 정보와 숨어있는 지식을 찾아내기 위한 데이터 가공 및 분석 과정을 지원하는 기술을 의미한다. 대규모 데이터 처리를 위해서는 확장성이 필요하며, 데이터 생성 및 처리 속도를 해결하기 위한 '처리 시간 단축', '실시간 처리 지원', '비정형 데이터 처리 지원'이 필요하다. 이를 위해 '하둡(Haddop)', '구글 맵리듀스(Google MapReduce)' 등을 통해 데이터 처리를 지원하고 있다.
2-3. 빅데이터 분석
'빅데이터 분석' 기술은 데이터를 효율적으로 정확하게 분석하여 비즈니스 등의 영역에 적용하기 위한 기술로, 빅데이터에 숨어있는 패턴과 지식을 찾아내기 위한 기술을 의미한다. 빅데이터 분석을 통해 찾아진 패턴과 지식을 토대로 비즈니스 영역에서는 의사결정을 수행한다. '빅데이터 분석' 기술에는 '통계 분석(Statistical Analysis)', '데이터 마이닝(Data Mining)', '텍스트 마이닝(Text Mining)', '평판 분석', '소셜 네트워크 분석(Social Network Analysis)' 기술 등이 포함된다.
- 통계 분석(Statistical Analysis): '통계 분석'은 'R', 'SAS(Statistical Analysis System)' 등을 통한 다양한 통계기법을 통해 수행된다. R은 빅데이터 분석 기술 도구로, 기본적인 통계 기법부터 데이터 마이닝 기법까지 구현이 가능한 기술 도구이며, SAS는 통계 해석을 중심으로 한 소프트웨어 패키지이다. 최근에는 '기계 학습'(Machine Learning), '신경망(Neural Network)' 등을 이용한 '데이터 마이닝' 기술이 가장 각광받고 있다.
- 마이닝(Mining): '마이닝(Mining)'이란 데이터로부터 통계적인 의미가 있는 개념이나 특성을 추출하고 이것들 간의 패턴이나 추세 등의 고품질의 정보를 끌어내는 과정이다. 데이터는 형태에 따라 고정된 구조 형태로 구성된 데이터를 '정형데이터(Structured Data)'로, 정해진 구조가 없을 때는 '비정형 데이터(Unstructured Data)'로 구분한다. 정형 데이터를 이용한 마이닝을 '데이터 마이닝(Data Mining)', 비정형 데이터를 이용한 마이닝을 '텍스트 마이닝(Text Mining)'이라고 한다.
- 평판 분석: '평판 분석'은 소셜 미디어 등의 정형 또는 비정형 텍스트의 긍정 선호도를 판별하여 분석하는 기술로, 주로 특정 서비스 및 상품에 대한 시장 규모 예측 및 입소문 분석 등에 활용된다.
- 소셜 네트워크 분석(Social Network Analysis): '소셜 네트워크 분석'은 소셜 네트워크의 연결 구조 및 연결 강도 등을 바탕으로 사용자의 명성 및 영향력을 분석하는 기술이다.
이러한 빅데이터 분석을 통해 도출된 빅데이터의 패턴과 지식은 비즈니스 의사결정에 활용되고 있어, 비선형적인 결과 값을 알아보기 쉽게 표시하는 '데이터 시각화(Data Visualization)' 기술의 중요도가 증가하고 있다.
반응형3. 시각화 기법
'데이터 시각화(Data Visualization)'는 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적인 수단으로 정보를 전달하는 과정을 말한다. 빅데이터 내에 수많은 패턴들을 시각화하여, 핵심 개념과 아이디어를 직관적이고 명확하게 이해할 수 있도록 하는 것이 '데이터 시각화'의 목적이다. '데이터 시각화'는 '차트(Chart)', '그래프(Graph)' ,'맵(Map)'과 같은 시각적 요소를 사용하여 빅데이터에서 '추세', '이상 값', '패턴'을 쉽게 이해할 수 있도록 하는 기법이다. 빅데이터의 세계에서 '데이터 시각화' 도구는 막대한 양의 정보를 분석하고 데이터 기반 의사결정을 내리는 데 필수적이다.
'빅데이터 시각화'는 '정보 시각화'를 기반으로 하고 있다. '정보 시각화'는 '대규모 수량', '비수량 데이터'를 '색채', '통계', '이미지' 등을 활용해서 시각적으로 표현하는 것을 의미한다. 정보 시각화 방법에는 '시간 시각화(Time Visualization)', '분포 시각화(Distribution Visualization)', '관계 시각화(Relationship Visualization)', '비교 시각화(Comparison Visualization)', '공간 시각화(Spatial Visualization)'가 있다. 다양한 시각화 방식을 통해 정보 전달 시간을 단축하고, 빅데이터에서 도출된 유의미한 인사이트를 비즈니스에 빠르게 적용하도록 할 수 있다.
시각화 종류 시각화 기법 예시 시간 시각화 꺾은선 그래프(Line Graph) 막대 그래프(Bar Graph) 누적 막대 그래프 점 그래프(Dot Graph) 분포 시각화 트리맵 차트(Treemap Chart) 파이 차트(Pie Chart) 도넛 차트(Donut Chart) 누적 연속 그래프 관계 시각화 버블 차트(Bubble Chart) 히스토그램(Histogramm) 산포도(Scatter Plot) 비교 시각화 히트맵(Heatmap) 히트 행렬(Heat Matrix) 방사형 차트(Radial Chart) 평행 좌표계(Parallel Coordinate System) 다차원 적도법 공간 시각화 지도 맵핑 방식 - 시간 시각화(Time Visualization): 빅데이터에서 시간과 관련된 데이터를 전달하고자 할 경우 '시간 시각화(Time Visualization)' 기법이 사용된다. 시계열 데이터에서 가장 큰 특징은 트렌드이다. 시간의 흐름에 따라 인구 분포가 변화하고, 사업 영역이 변화하고, 사람들의 취향이 변화한다. 이러한 변화가 얼마나 진행되었는지 측정해서 기록한 것이 '시계열 데이터(Time Series Data)'이다. 변화의 패턴을 찾아서 트렌드를 알기 위해서는 개별 측정 데이터보다는 전체적인 벼화의 추이를 알아야만 한다. 즉, 한 가지 구간에 대한 특정 값보다는 다구간에 걸친 데이터 변화량의 전달이 더 중요하다. '시간 시각화'를 통해 전체적인 데이터의 변경 추이, 급격하게 데이터가 증가하거나 감소된 구간이 있는지, 눈에 띄는 특정 구간이 있는지, 일정한 패턴이 있는지 여부 등을 확인할 수 있다. '시간 시각화(Time Visualization)'는 '꺾은선 그래프', '막대 그래프', '누적 막대 그래프', '점 그래프' 등으로 표시될 수 있다.
- 분포 시각화(Distribution Visualization): '분포 시각화(Distribution Visualization)'는 데이터의 전체적인 분포를 확인하기 위한 시각화 방식이다. '시간 시각화'의 단위가 시간인 것과는 달리, '분포 시각화'의 단위는 분류, 세부 분류 및 가짓 수다. '분포 시각화' 자료를 통해 빅데이터의 '최대', '최소', '전체 분포'를 확인할 수 있다. '분포 시각화'에서는 '트리맵 차트(Treemap Chart)', '파이 차트(Pie Chart)', '도넛 차트(Donut Chart)', '누적 연속 그래프' 등이 사용된다.
- 관계 시각화(Relationship Visualization): 빅데이터를 통해 확인할 수 있는 중요한 지표 중 하나는 데이터 간의 관계이다. 집단 간에 유사점이 있는지, 특정 집단의 소집단이 존재하는지, 집단 간의 상관관계가 있는지를 '관계 시각화'를 통해 확인할 수 있다. '관계 시각화'에는 '버블 차트(Bubble Chart)', '히스토그램(Histogramm)', '산포도(Scatter Plot)' 등이 사용된다. 그중에서도 '관계 시각화'에 가장 많이 사용되는 차트는 '버블 차트'이다.
- 비교 시각화(Comparison Visualization): '비교 시각화' 기법은 하나 이상의 변수를 기준으로 대상을 비교할 수 있도록 하는 기법이다. 한 개 또는 두 개의 변수로 대상을 비교하는 것은 비교적 간단하지만, 비교 대상이 많아지거나 비교 변수의 개수가 늘어날 경우 고도화된 시각화 기법이 필요하다. 시각화 기법을 활용하지 않을 경우, 비교해야 할 대상의 숫자에 비교하려는 변수의 숫자를 곱한 만큼의 단위 비교 목록을 체크해야 한다는 무제가 존재한다. 비교 시각화 기법으로는 데이터를 전체적으로 시각화한 후, 흥미로운 부분을 선택적으로 시각화하는 것이 일반적인 접근 방법이다. 데이터를 한눈에 볼 수 있도록 값을 색으로 나타내어 표로 도식화하는 '히트맵(Heatmap)' 또는 '히트 행렬(Heat Matrix)'이 비교 시각화 기법에 일반적으로 사용되고 있다. 그 외에도 비교 시각화 기법에는 '스타 차트', '평행 좌표계', '다차원 적도법' 등이 사용된다.
- 공간 시각화(Spatial Visualization): '공간 시각화'는 지도 맵핑 방식을 통해 구현된다. 구체적으로 '공간 시각화'는 지도에 특정 시간 단위의 값을 맵핑하거나, 지도에 다양한 분류 값들을 맵핑하는 시각화 방식이다. 지도는 직관성을 폭넓게 활용한 지각화의 한 분야로, 지도를 읽는 것과 통계 그래픽을 읽는 방법은 매우 유사하다. 지도는 위치와 거리에 대한 직관적인 정보를 내포하고 있다. 위치와 색상 구분을 명확히 하고, 라벨이 위치를 가리지 않도록 정확한 투사 방식을 통해 지도를 기반으로 한 시각화 결과를 생성할 수 있다. 예를 들어, 시간 변수를 공간 시각화 방식에서는 애니메이션으로 특정 지역의 경제적인 성장 또는 몰락을 시각화할 수 있다.
다양한 시각화 기법을 사용한 데이터들을 아래의 예시를 통해 살펴보자.
3-1. 코스피 주가 지수
- 기법: 시간 시각화 - 꺾은선 그래프
아래의 그림은 코스피 지수의 추이를 '시간 시각화' 형태로 나타낸 것이다. 2020년 초에는 기존 트렌드와는 다르게 급격하게 지수가 감소한 부분을 확인할 수 있다. 이러한 그래프를 통해 해당 시점에 '코로나19(COVID-19)' 초기 당시 인해 주식 시장에서 자본이 많이 빠져나갔음을 확인할 수 있다.
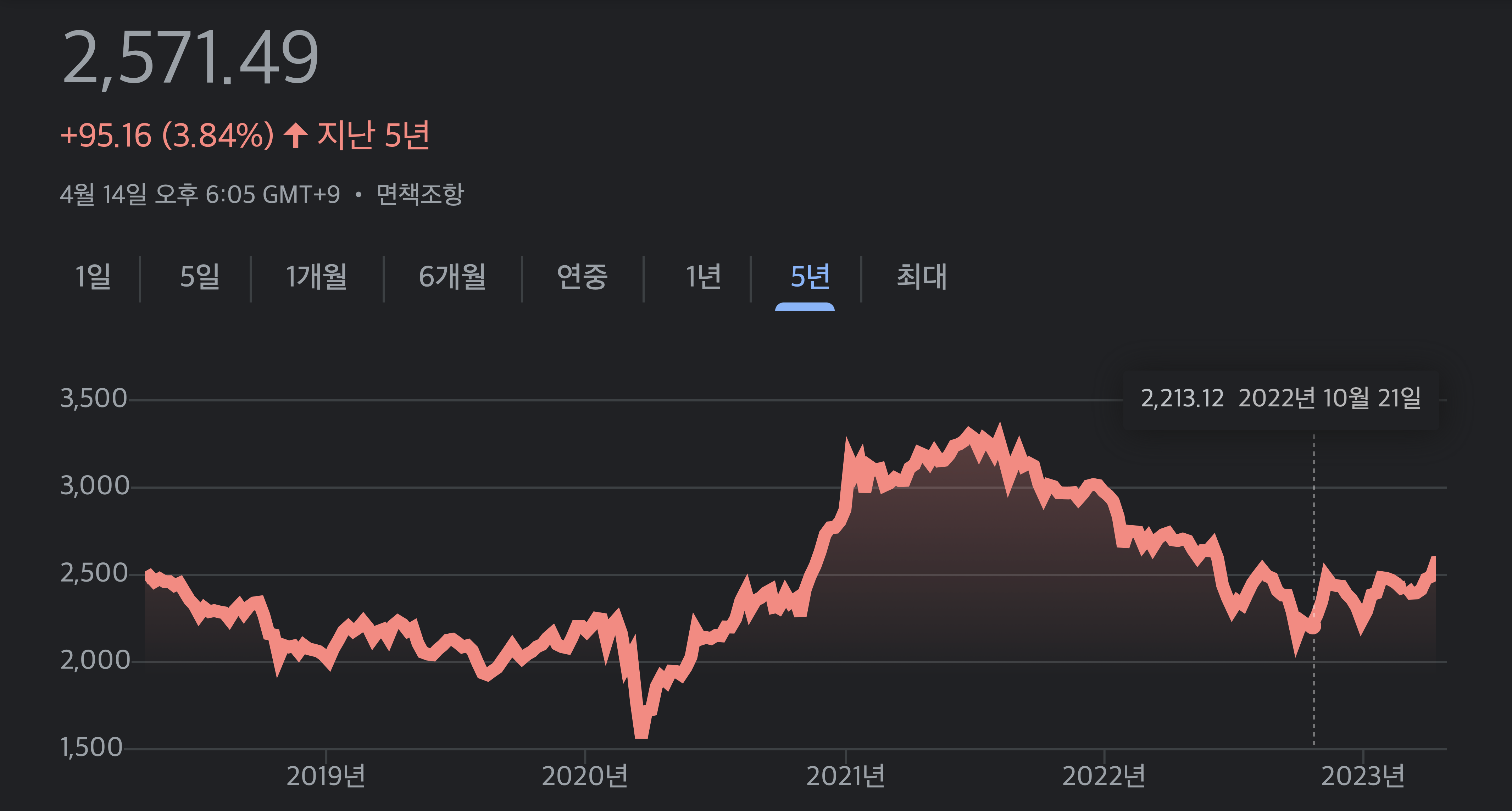
시간 시각화 예시 (코스피 지수 추이) 3-2. 외출 시 항상 마스크를 착용한다고 응답한 비율
- 기법: 분포 시각화
아래의 그림은 '코로나바이러스-19(COVID-19)'가 확산되었을 당시, '외출 시 항상 마스크를 착용한다고 응답한 비율'을 '분포 시각화' 형태로 분석한 지도이다. '외출 시 항상 마스크를 착용한다고 응답한 비율'이 95%를 넘는 나라는 한국이 유일했음을 알 수 있다.
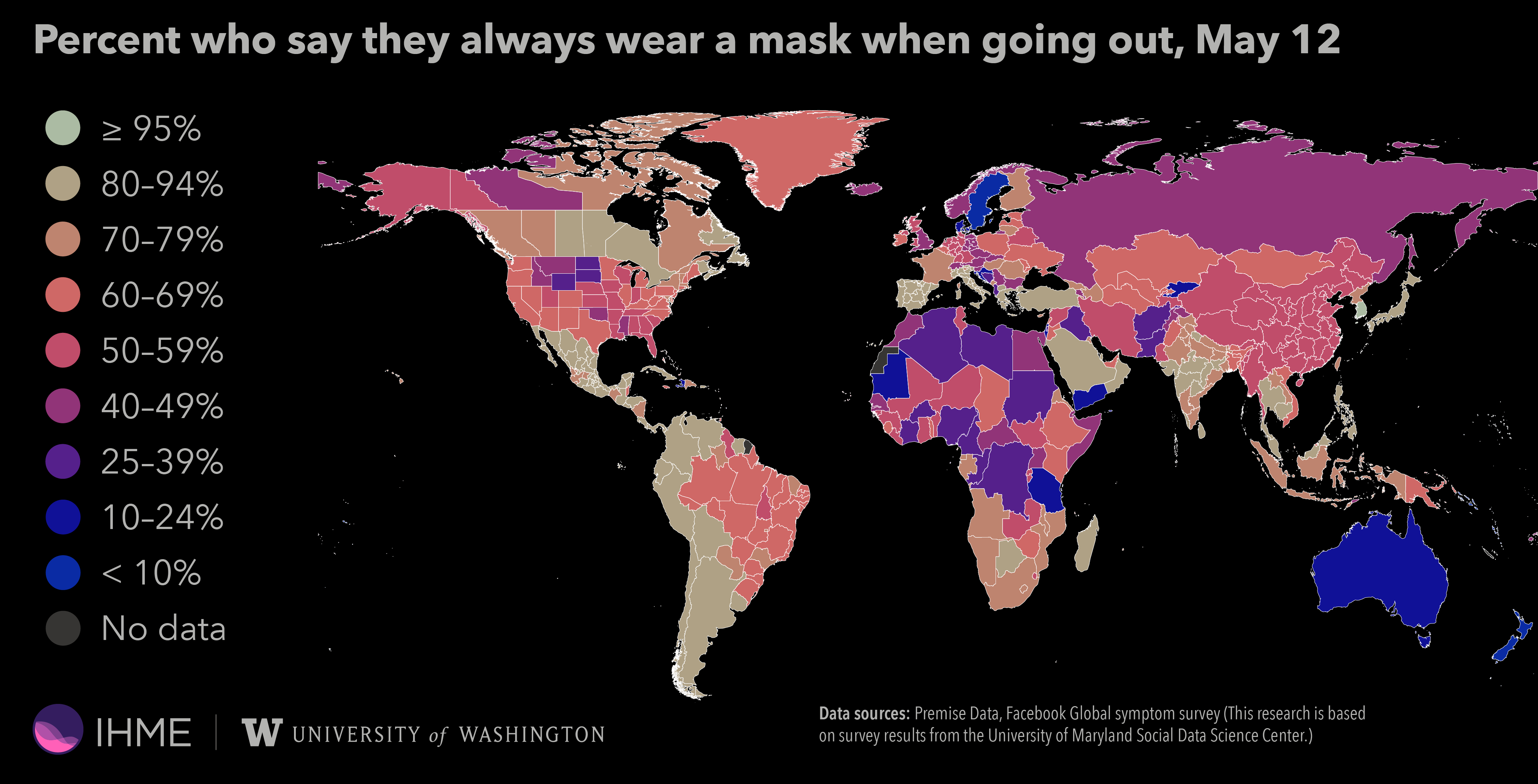
외출 시 항상 마스크를 착용한다고 응답한 비율 (2021년 5월 12일 기준) 3-3. S&P 500 시가총액 동향
- 기법: 분포 시각화 - 트리맵(Treemap)
아래의 그림은 분포 시각화에서 가장 많이 쓰이는 형태 중 하나인 '트리맵(Treemap)' 형태로 나타낸 S&P 500의 동향을 나타낸 차트이다. S&P 500 중 규모가 큰 종목들일수록 사각형의 크기가 크게 나타나고, 종목의 변동에 따라 색상으로 차트가 표시된다. 사용자들은 전체적인 주가 동향 및 기술·금융·커뮤니케이션 등의 '섹터(Sector)'별 주가 동향을 한눈에 확인할 수 있다.
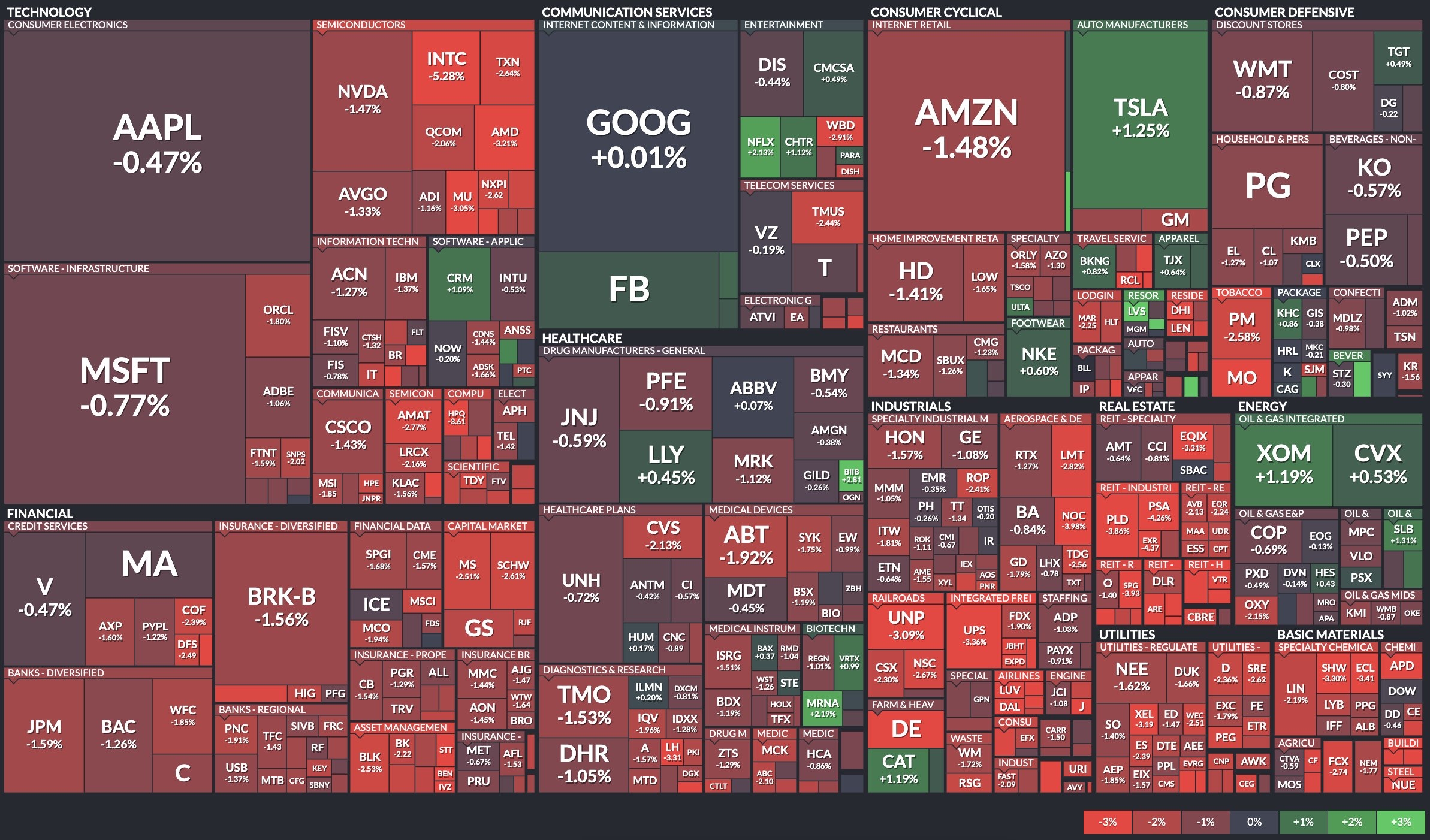
S&P 500 시가총액 동향 (2022년 6월 9일 기준) 3-4. 신경망 모델별 성능
- 기법: 관계 시각화 - 버블 차트(Bubble Chart)
아래의 그림은 '인공 신경망' 모델들의 성능을 '버블 차트(Bubble Chart)'로 나타낸 것이다. 가로축은 정확도, 세로축은 F1-Score로 구현하여 모델 각각에 대한 성능을 나타내며, 버블의 크기로 '재현율(Recall)'을 표시하고 있다. 해당 버블 차트를 통해 '신경망 모델들의 전체적인 정확도' 및 'F1-Score 추이'를 알 수 있으며, 특정 신경망 모델의 성능이 다른 모델들에 비해 압도적으로 높은 것을 한눈에 확인할 수 있다. 즉, 사용자들은 '버블 차트'를 통해 신경망 모델들의 성능 추이 및 모델들 각각의 개별 성능을 한눈에 비교할 수 있다.
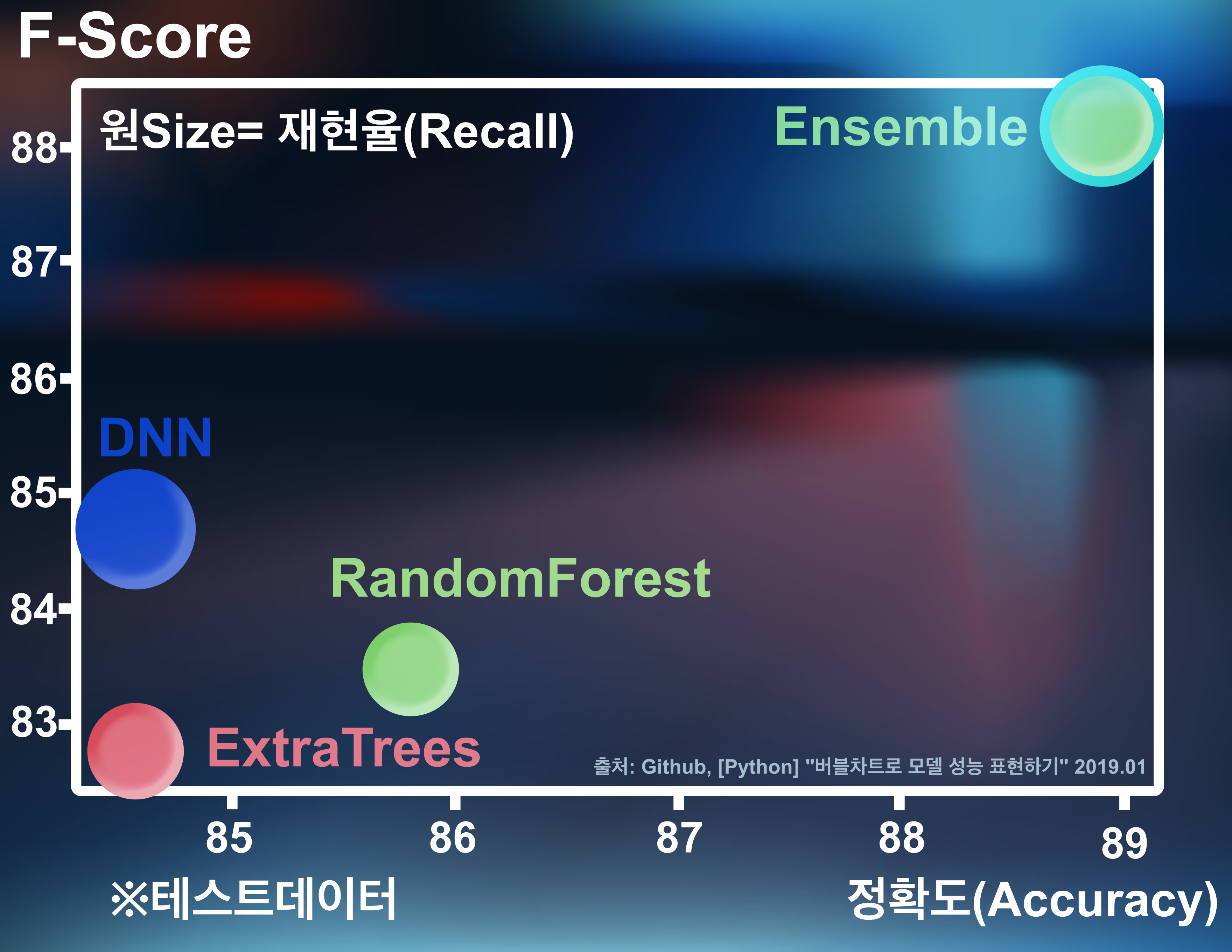
신경망 모델별 성능 버블 차트 3-5. 미국의 주별 범죄 동향
- 기법: 비교 시각화 - 히트맵(Heat Map)
- 출처: Tableau public "Crime Waves in the States"
아래의 그림은 미국의 주별 범죄 종류 및 연도에 따른 범죄 횟수를 히트맵으로 나타낸 것이. '히트맵(Heat Map)'을 이용하여 '주별 범죄 발생 동향', '범죄 종류별 범죄 발생 동향', '연도별 범죄 발생 동향'을 확인할 수 있다. '주(State)', '범죄 종류', '연도(Year)'라는 3가지 변수를 이용하여 시각화 자료를 표현한 것이다. 십만 건 이상의 미국 주별 범죄 현황을 데이터 각각으로 보면 동향을 파악하는 것이 어렵지만, 아래와 같은 히트맵을 활용할 경우, 단 한 장의 차트만으로도 다양한 관점의 분석이 가능하다. 즉, 히트맵은 전체 데이터를 한눈에 볼 수 있다는 장점이 있으며, 가지고 있는 데이터가 여러 개의 변수로 구성되더라도 일정 기준에 따라 분류하거나 단위에 따라 나누어 예외적인 값을 찾아낼 수 있다.
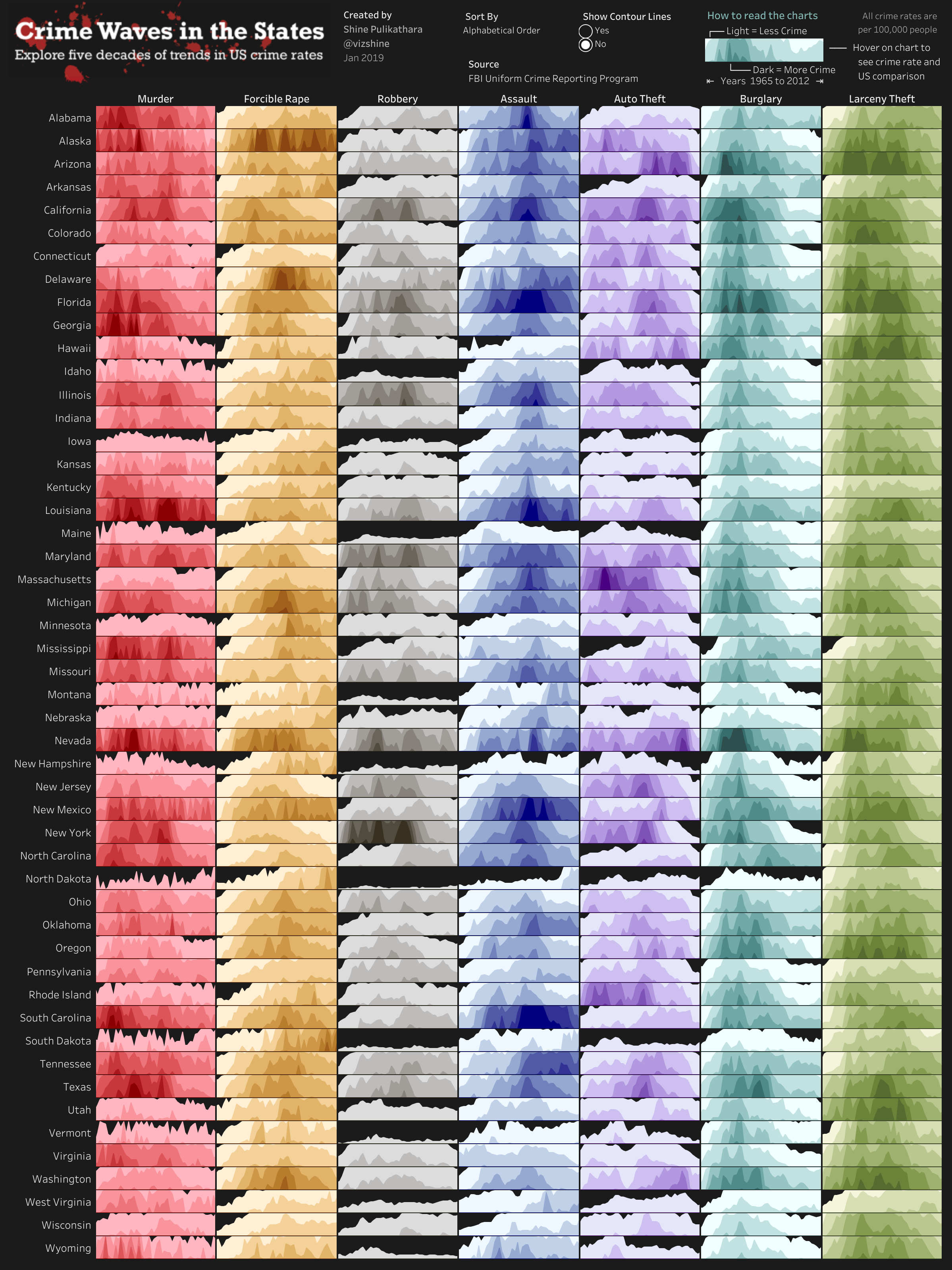
미국의 주별 범죄 동향 3-6. 서울시 구별 SNS 데이터 분포
- 기법: 공간 시각화 - 파이 차트
- 출처: 서양모, 김원균 "공간 빅데이터를 위한 정보 시각화 방법" 한국공간 정보학회지 v.23, no. 6 pp. 2015 12
아래의 그림은 서울시의 각 구를 기준으로 각 구에 포함된 SNS 데이터의 총 건수를 숫자로 나타내고 있으며, '파이 차트'는 해당 구의 SNS 데이터의 총 건수에서 '트위터(Twitter)', '인스타그램(Instagram)', '유튜브(Youtube)'가 차지하는 비율을 보여주고 있다.
서울시 구별 SNS 데이터 분포 4. '데이터 시각화' 관련 기업
데이터 시각화 기술은 '세일즈포스(Salesforce)'를 포함한 글로벌 대기업들이 리딩하고 있다. 국내에서도 빅데이터 및 인공지능 기술을 개발하는 코스닥 기업들의 관련 시장 진입이 시작되었다.
4-1. 세일즈포스(Salesforce)
- 국적: 미국
- 플랫폼: 태블로(Tableau)
- 요약: 전 세계 독보적인 데이터 시각화 솔루션 제공
'세일즈포스(Salesforce)'의 '태블로(Tableau)'는 간단한 조작만으로 데이터를 분석하고 시각화된 자료를 공유할 수 있도록 한 솔루션이다. '태블로 소프트웨어(Tableau Software)'는 2003년 후발 주자로 '비즈니스 인텔리전스(BI: Buisiness Intelligence)' 시장에 뛰어들어, 기존 BI 산업의 강자였던 SAP를 제치고 세계 BI 솔루션 시장에서 1위를 차지하였다. '태블로 소프트웨어'는 이후 2019년도에 세일즈포스에 인수되어, 세일즈포스 사에서 '태블로 솔루션' 판매를 담당하고 있다. '태블로'는 간편한 시각화 과정을 내세워 전 세계 사용자들의 선택을 받고 있다. R에서 시각화를 하려면 코드를 입력하고, '데이터 임포트(Data Import)', '라이브러리 가동', '축의 변수명 지정' 등 번거로운 절차를 거쳐야 했던 것과 달리, 태블로에서는 간단히 '드래그 앤 드롭(Drag & Drop)'을 통해 데이터 시각화를 수행할 수 있다. '태블로 솔루션'은 국내에 2014년도에 런칭되어, 2019년 상반기 기준 1000여 개 이상의 고객을 확보하였다.
태블로(Tableau) 4-2. 구글(Google)
- 국적: 미국
- 플랫폼: 구글 데이터 스튜디오(Google Data Studio)
- 요약: 다양한 구글 서비스와의 호환성을 내세운 데이터 시각화 솔루션 제공
'구글(Google)'은 2016년도에 '비즈니스 인텔리전스(BI: Bussiness Intelligence)' 데이터 시각화 시장 발전 트렌드에 따라 '구글 데이터 스튜디오(Google Data Studio)'를 출시하였다. 구글의 '데이터 스튜디오'는 다른 구글 서비스들과의 호환성을 기반으로 빠르게 성장하고 있으며, 웹 분석 솔루션의 대표 주자로 자리매김한 '구글 애널리틱스(Google Analytics)', '구글 시트(Google Sheets, 구글의 스프레드시트)' 등 구글에서 제공하는 다른 서비스들과 곧바로 데이터 호환이 가능하다. 특히 '구글 데이터 스튜디오'는 '구글 애널리틱스(Google Analytics)'에서 사용되는 대부분의 지표를 지원하고, 무료 솔루션이라는 점에서 다른 플랫폼보다 우위를 가진다.
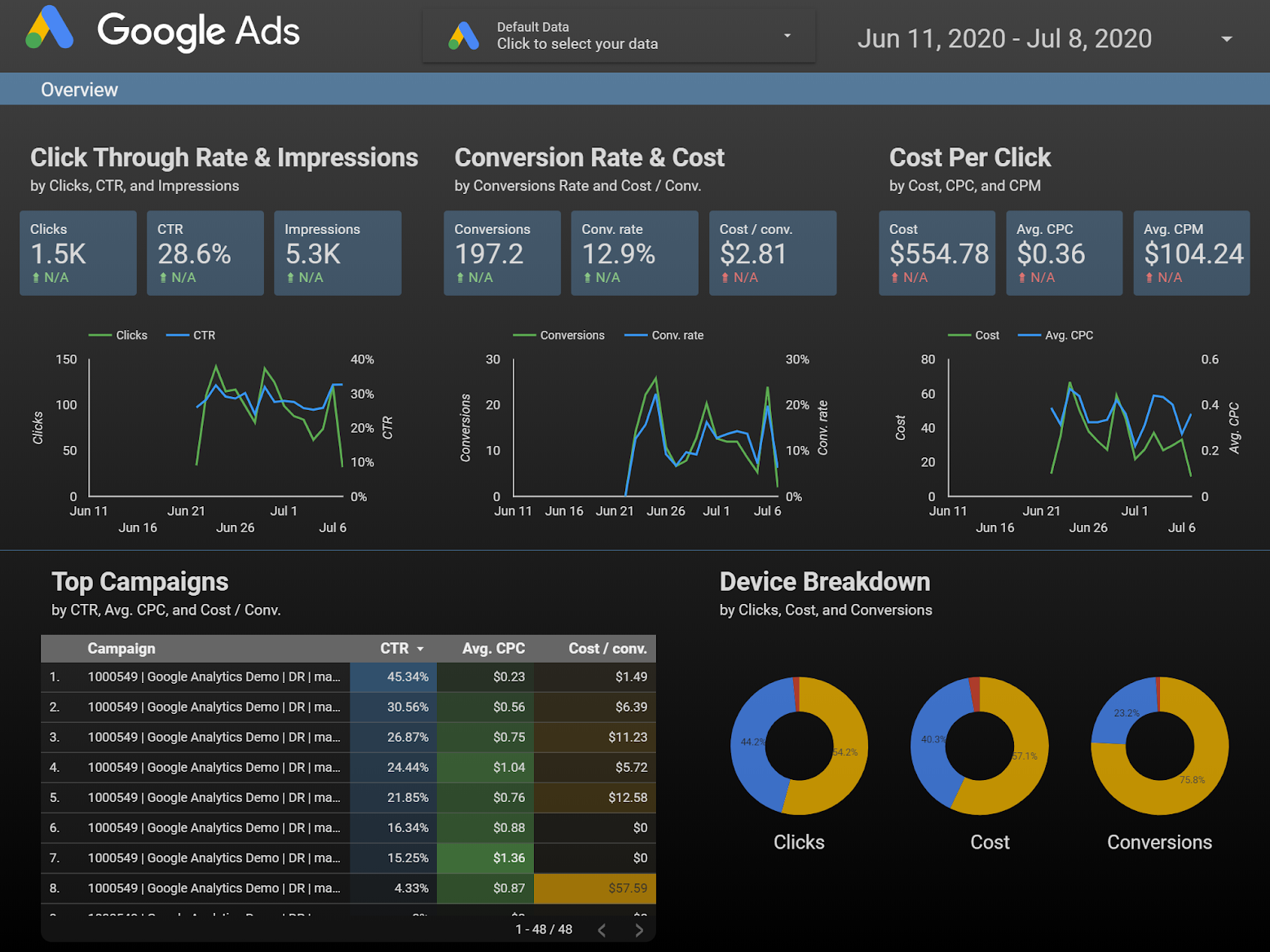
구글 데이터 스튜디오(Google Data Studio) 4-3. 마이크로소프트(Microsoft)
- 국적: 미국
- 플랫폼: Power BI
- 요약: 마이크로소프트 기본 서비스와 호환성을 강조한 BI 솔루션
'마이크로소프트(Microsoft)'의 Power BI는 비즈니스 분석 플랫폼으로, '다양한 데이터의 원본(엑셀, CSV, XML 데이터 파일 등)'에 연결하여 데이터 통합 분석을 수행한 후, '대시보드(Dashboard)'를 통해 시각적으로 분석을 생성한다. Power BI는 기존에 일반적으로 사용되던 마이크로소프트 서비스를 기반으로 손쉽게 동작이 가능하다. 또한 사용자들의 진입 쉽다는 점에서 Power BI의 점유율이 점차 증가하고 있는 추세이다.
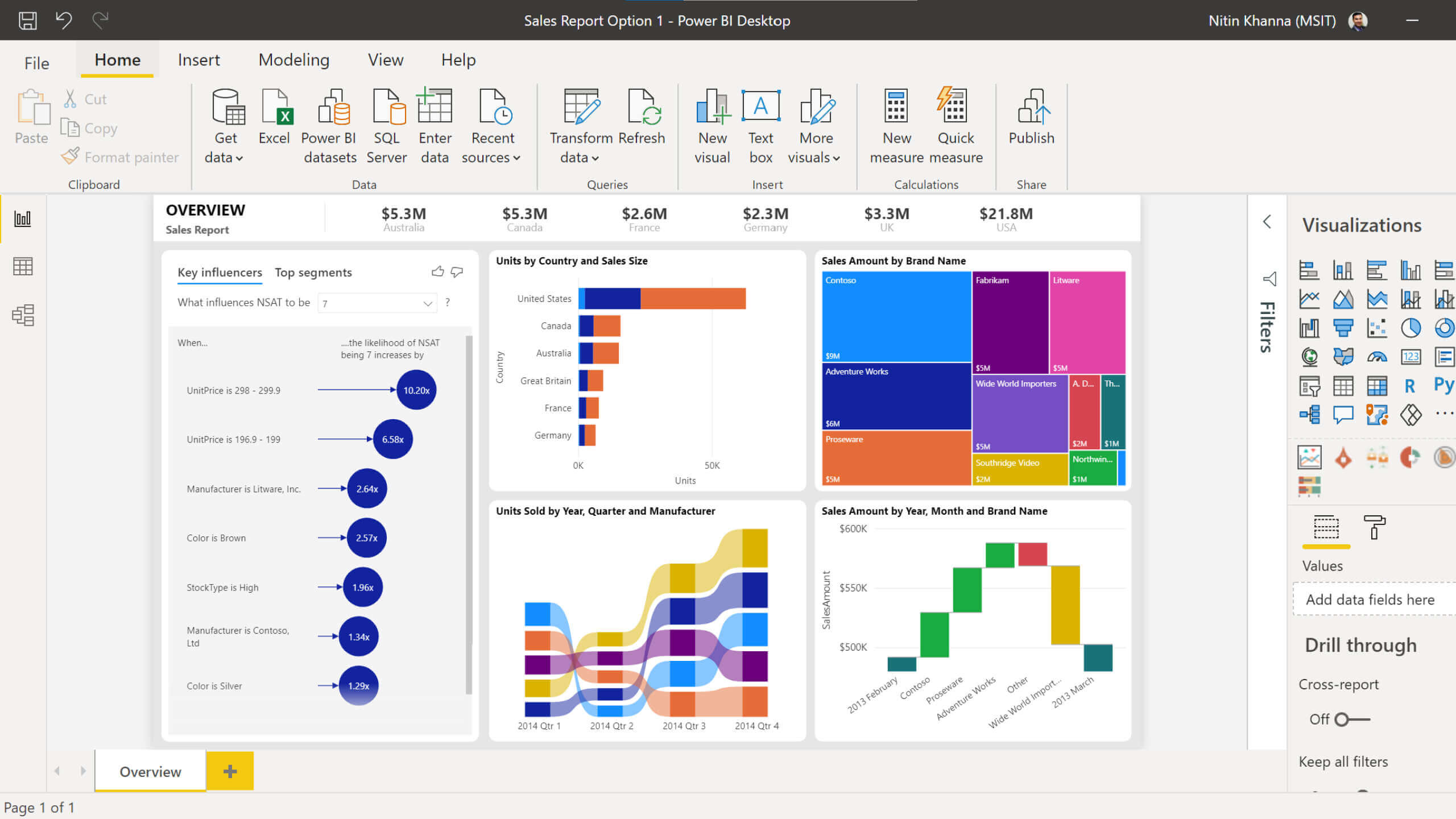
Power BI 4-4. 뉴스젤리
- 국적: 한국
- 플랫폼: DAISY
- 요약: 데이터 시각화 특화 솔루션 제공
'뉴스젤리'는 데이터 시각화에 특화된 기업으로, 2014년에 설립된 후 2016년에 '데이터 시각화 솔루션(Data Visualization Solution)인 DAISY를 출시하였다. DAISY는 은평구, 성남시, 기상청, 농협, KB에서 사용되고 있는 솔루션으로, 대용량 데이터의 활용이 자유롭지 않은 엑셀과 차별화하여 대시보드 단위로 차트를 관리할 수 있도록 한다.
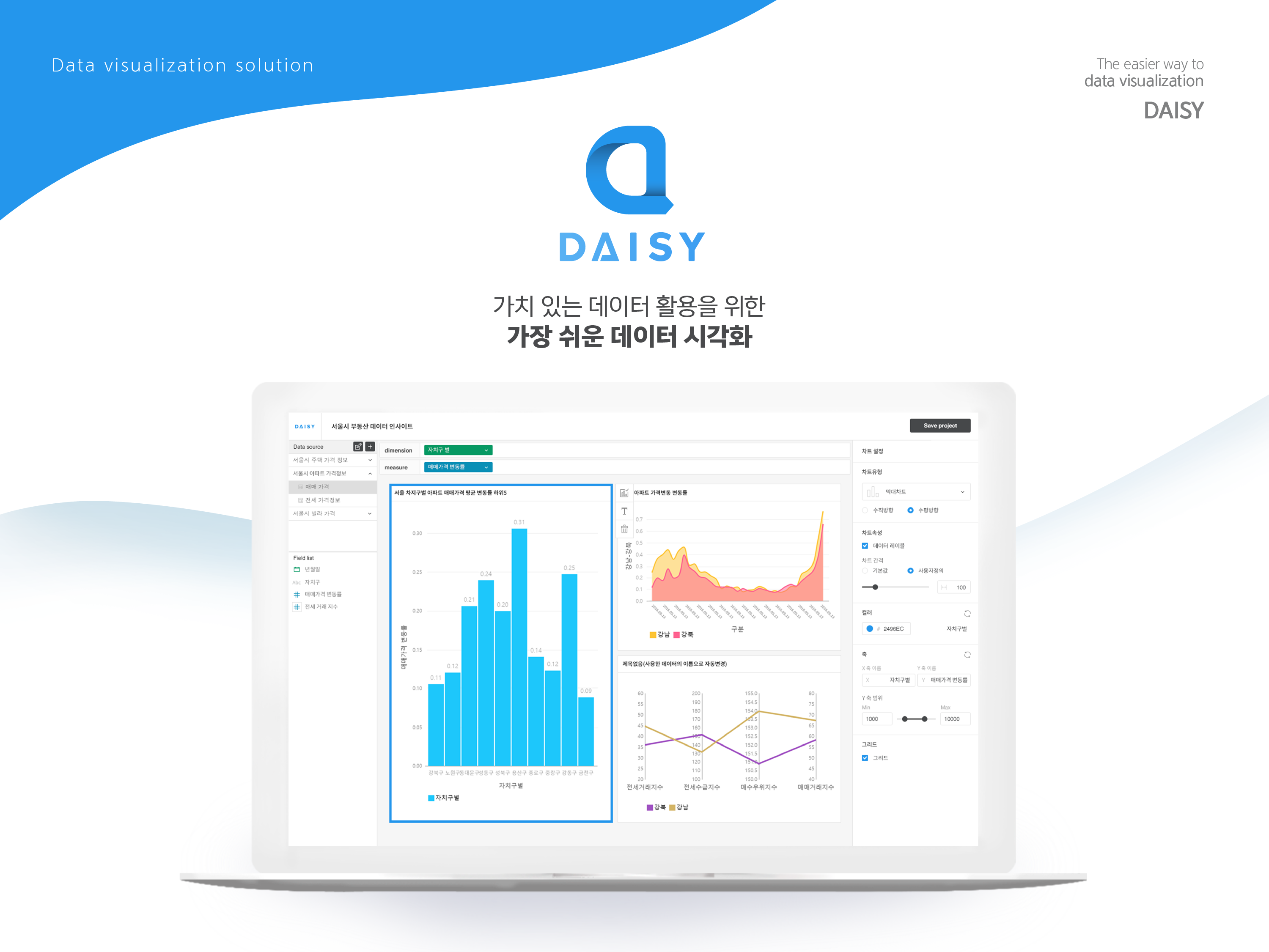
DAISY 4-4. 와이즈넛(WISEnut)
- 국적: 한국
- 플랫폼: WISE BIC Analyzer
- 요약: 빅데이터 솔루션 제공
'와이즈넛(WISEnut)'은 2000년도에 설립된 '인공지능 기반 챗봇', '빅데이터 수집', '분석 솔루션' 전문 기업으로, 빅데이터 의미분석 솔루션을 제공하고 있다. '와이즈넛'의 WISE BIC Analyzer는 비정형 빅데이터의 의미를 분석하고 빠른 의사결정을 지원하는 솔루션이다. 해당 솔루션은 '텍스트 마이닝(Text Mining)' 및 '분류 기술'을 기반으로 구현되었다. WISE BIC Analyzer는 '형태소 분석', '자연어 처리', '표현어 추출' 기술을 포함하는 감성 분석용 언어 처리를 통해 감성 분석 결과를 지수화하고, 긍정 또는 부정 트렌드를 분석하며, 이슈나 급상승 키워드를 분석하여 제공하고 있다.

WISE BIC Analyzer 4-5. 비아이매트릭스(Bimatrix)
- 국적: 한국
- 플랫폼: i-STREAM, i-AUD
- 요약: 빅데이터 솔루션 제공
'비아이매트릭스(Bimatrix)'는 기업의 경영 환경에 대응할 수 있도록, 의사결정을 지원하는 빅데이터 및 BI솔루션을 제공하고 있다. 비아이매트릭스의 i-STREAM은 데이터 전처리부터 데이터 분석까지 지원하는 데이터 분석 솔루션이며, i-AUD는 대시보드 화면 제작에 최적화된 BI 솔루션이다. i-AUD는 실시간 데이터를 반영하는 '동적 차트', '현황판', '플래시 타입 차트' 등 대시보드 시스템 구축을 지원하여 '데이터 시각화(Data Visualization)'를 통한 의사결정을 지원하고 있다.

i-STREAM 4-6. 바이브컴퍼니
- 국적: 한국
- 플랫폼: Sometrend Biz
- 요약: SNS와 올라인 플랫폼에서 발생하는 고객·브랜드·상품 등에 대한 데이터를 수집·분석·시각화
'바이브컴퍼니(VAIV Company)'는 200년 7월 다음커뮤니케이션 내부에서 사내 인큐베이팅을 통해 '다음소프트'로 설립되었으며, 2020년 8월 14일 바이브컴퍼니로 상호를 변경한 후, 기술특례상장을 통해 2020년 10월 28일에 코스닥 시장에 상장되었다. 바이브컴퍼니의 Sometrend Biz는 빅데이터 분석 솔루션으로, SNS와 온라인 플랫폼에서 발생하는 고객·브랜드·상품 등에 대한 데이터를 수집·분석·시각화하여 인사이트를 제공하는 솔루션이다. Sometrend Biz은 '트위터', '블로그', '인스타그램', '뉴스' 등 채널 별 언급 추이를 확인하고, 카테고리에 따른 연관어를 분류하여 제공함으로써 기업들에게 고객의 관심 변화를 실시간으로 확인할 수 있도록 한다. 또한 Sometrend Biz은 연관어 시각화 데이터를 통해 기업의 평판을 확인할 수 있다.
Sometrend Biz 4-7. 솔트룩스(Saltlux)
- 국적: 한국
- 플랫폼: Bigdata Suite
- 요약: 정형 빅데이터와 비정형 빅데이터의 융합 분석 솔루션
'솔트룩스(Saltlux)'는 2000년에 설립된 인공지능 및 빅데이터 기술 기업인 '시스메타'를 시작으로, 2006년에 사명을 솔트룩스로 변경한 기업이다. '솔트룩스'는 2020년 07월에 기술특례상장 제도를 통해 코스닥 시장에 상장되었다. 솔트룩스의 Bigdata Suite는 정형 빅데이터와 비정형 빅데이터의 융합 분석 솔루션이다. Bigdata Suite는 기업 및 공공 빅데이터에 대한 '시맨틱 검색/분석', '지능화', 'IoT 센서', '생산 및 운영시스템 로그'와 같은 스트림 빅데이터에 대한 실시간 분석·예측 기능을 제공하고 있다. Bigdata Suite의 시각 분석 엔진은 다양한 형식의 데이터 소스를 연결하여, 인터렉티브한 시각화 라이브러리들을 이용하여 시각적 분석 기능을 제공한다.

Bigdata Suite 4-8. 엑셈(Exem)
- 국적: 한국
- 플랫폼: Flamingo
- 요약: 빅데이터 수집·저장·정제·분석·모니터링이 가능한 솔루션
'엑셈(Exem)'은 2001년에 설립된 후 2014년에 상장된 빅데이터 솔루션 기업으로 '플라밍고(Flamingo)'를 통해 빅데이터 수집·저장·정제·분석·모니터링이 가능한 솔루션을 제공하고 있다. '하둡(Haddop)' 기반으로 빅데이터 플랫폼을 사용하는 기업들이 빅데이터 운영 중 발생한 이슈를 해결하는 데 해당 솔루션을 활용할 수 있다. '플라밍고(Flamingo)'를 통해 빅데이터를 관리하는 기업들은 '플랫폼 모니터링', '데이터 정제·처리를 위한 워크플로우 기능'을 이용하여 빅데이터 통합 분석 및 성능 관리를 손쉽게 수행할 수 있다.
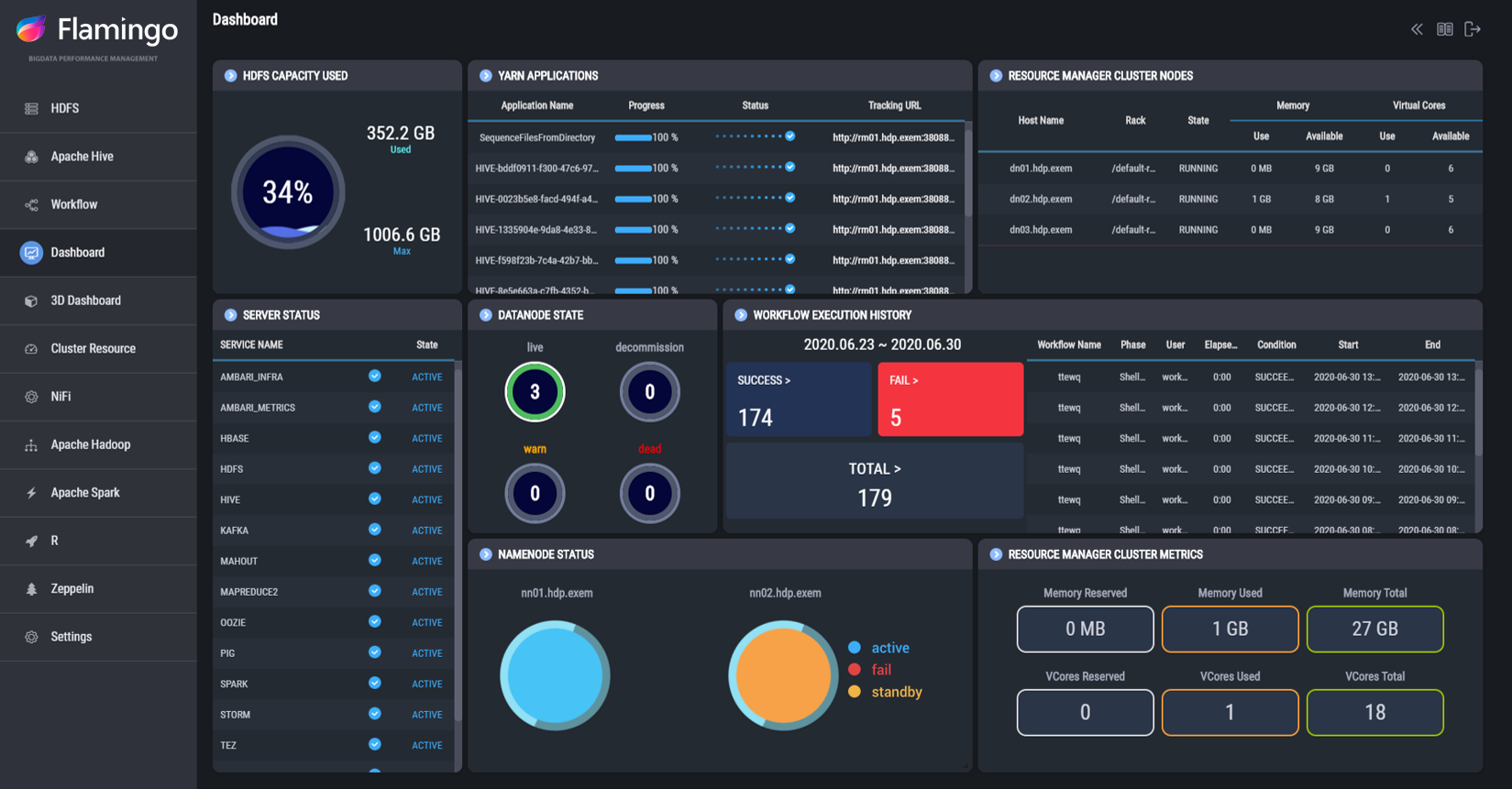
Flamingo (대시보드 화면)