0. 목차
- 신피질의 계층구조
- 계층적 패턴인식의 과정
- 리던던시(Redundancy)
- 파라미터는 어떻게 작동하는가?
- 자동 연상
- '기억'은 '인식'을 위해 존재한다.
- 정보처리 메커니즘의 보편성
- 학습
- 생각의 방향성
- '언어'의 계층적 속성
- 인공지능 모형설계
1. 신피질의 계층구조
'신피질'은 영어로 'neocortex'라고 하는데, 이는 라틴어로 '새로운 껍질(neo cortex)'에서 유래한 말이다. 신피질의 주요 기능은 계층적으로 구성된 정보의 패턴을 다루는 것이다. 또한 신피질 자체가 계층적인 방식으로 작동하기도 한다. 따라서 신피질이 없는 동물은 계층구조를 이해하는 능력이 없다고 할 수 있다. 즉, 포유류가 아닌 동물들은 '신피질'이 없으므로, 기본적으로 포유류가 아닌 능력은 계층적으로 이해하는 능력이 없다. 계층구조를 이해하고 활용하는 능력이 포유류에게만 있는 이유는, 포유류가 가장 최근에 진화한 뇌 구조를 가지고 있기 때문이다. 신피질은 시각적 대상에서 추상적 개념에 이르기까지 모든 것을 인식하며, 동작을 제어하며, 공간을 지각하는 일을 하며, 합리적을 판단을 하는 일까지 갖가지 추론을 하며, 언어도 구사한다. 기본적으로 우리가 '생각'이라고 간주하는 모든 능력을 간주한다.
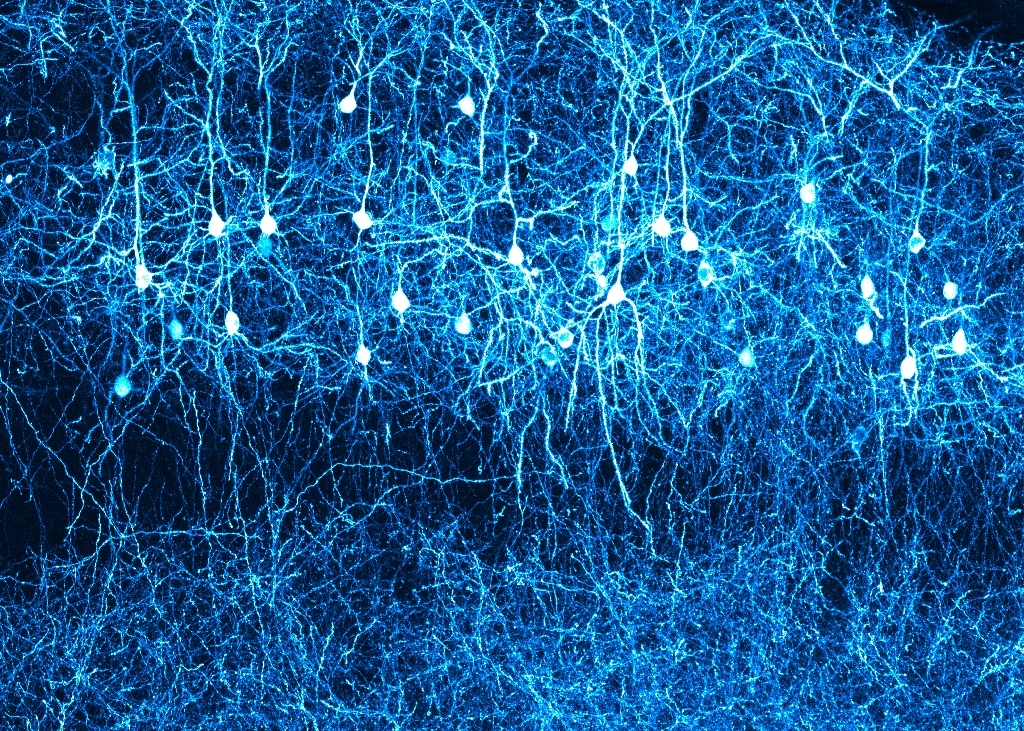
신피질은 뇌의 가장 바깥 면을 덮고 있다. 인간의 경우, 2mm 두께로 된 펼쳐진 2차원 조직이다. 설치류의 경우 뇌의 표면이 매끄러운데, 이 표면을 덮고 있는 신피질을 쫙 펼치면 우표 크기 정도가 된다. 하지만 영장류로 올라가면서 뇌의 표면에 깊은 주름이 생겨 돌기와 고랑이 만들어지고, 이로써 뇌의 표면적이 늘어나는 혁명적인 진화가 발생했다. 이로써 신피질은 인간 뇌 전체 무게의 80%까지 차지하게 되었다. 더욱이 호모사피엔스는 이마가 넓어지면서, 신피질은 더 많은 공간을 차지할 수 있게 되었다. 이렇게 발달한 '전두엽'은 특히 고차원적 개념과 관련된 한층 추상적인 패턴을 처리하는 기능을 한다.
1-1. 신피질은 여섯 개의 층으로 이루어져 있다.
얇은 신피질은 기본적으로 여섯 개의 '층(Layer)'으로 이루어져 있다. 가장 바깥쪽을 1층이라고 하고, 가장 안쪽을 6층이라고 한다. 2층과 3층에 있는 뉴런에서 솟아난 축삭은 신피질의 다른 영역과 연결되어 있다. 가장 안쪽에 위치한 5층과 6축에 있는 뉴런에서 솟아난 축삭은 신피질 아래에 있는 '시상(Thalamus)', '뇌간(Brainstem)', '척수(Spinal Cord)'로 이어진다. 6층에 있는 뉴런들은 특히 시상에 위치한 뉴런들로부터 시냅스를 통해 정보를 전달받는다.
세포층의 두께는 뇌의 부위마다 달라진다. 예컨대 운동피질에서는 6층이 매우 얇은데, 이곳에서는 시상, 뇌간, 척수로부터 정보를 전달받을 필요가 없기 때문이다. 이와는 반대로 시각 처리를 주로 담당하는 후두엽에서는 4층이 3개의 층으로 다시 나뉘는데, 이는 시상을 비롯하여 다양한 곳에서 들어오는 정보가 매우 많기 때문이다.

1-2. '뉴런 기둥'은 신피질을 구성하는 기본단위이다.
신피질의 특징 중 하나는 그 기본 구조가 매우 균일하다는 점이다. 1957년, 미국의 신경과학자 '버논 마운트 캐슬(Vernon Mountcastle, 1918~2015)'은 신피질의 신경세포들이 기둥처럼 뭉치를 이루고 있다는 사실을 발견했다. 더 나아가 1978년에 '버논 마이크 캐슬'은 신피질 전체에 똑같은 구조와 메커니즘이 끝없이 반복된다는 발견을 했다. 그는 이러한 발견과 더불어 뉴런의 기둥 뭉치가 신피질을 구성하는 기본단위라는 가설을 제시했다. 앞에서 설명한 바와 같이, 신피질의 층의 높이는 뇌의 영역과 관장하는 상호 연결성의 양에 따라 달라지지만, 그 토대가 되는 것은 모두 기본적인 뉴런 기둥이라는 것이다. '버논 마운트 캐슬'은 뉴런 기둥 안에 또 다른 기둥이 존재할 수 있다고 가정했지만, 더 작은 구조로 나눌 수 있는 가시적인 경계는 발견하지 못했다. 하지만 더 많은 실험을 통해 각각의 뉴런 기둥 역시, 반복되는 기둥 단위들이 모여 이루어진 것이라는 사실을 밝혀냈다. 이러한 기본적인 단위의 뉴런 기둥들은 제각각 '패턴인식기(Pattern Recognizer)'로 작동하며, 신피질의 기초를 구성하다. '버논 마운트 캐슬(Vernon Mountcastle)'이 이러한 '미세 기둥'을 발견하지 못한 것은, 눈으로 구분할 수 있다고 생각했기 때문이다. 하지만 패턴인식기 사이에는 물리적 경계가 존재하지 않는다. 각각의 패턴인식기들은 좀 더 밀접하게 얼기설기 엮여있다. 뒤에서 더 설명하겠지만, 신피질은 이런 방식으로 구성될 수밖에 없다.
결국 시각적으로 구분할 수 있는 '뉴런 기둥'은 패턴인식기들의 집합이다. 이 패턴인식기들은 우리가 살아가는 동안 서로 연결되기도 하고 끊어지기도 한다. 신피질에서 관찰할 수 있는 모듈 간의 정교한 연결망은 유전자 코드에 의해 미리 결정된 것이 아니라, 시간을 두고 습득하는 패턴을 반영하여 만들어지는 것이다. 인간의 신피질에는 약 50만 개의 '뉴런 기둥(피질 기둥)'이 있다. 높이 2mm에 0.5mm2 정도 공간을 차지하는 피질 기둥에는 대략 600개의 패턴인식기가 담겨 있고, 패턴인식기에는 각각 100여 개의 뉴런이 담겨있다. 결국 하나의 피질 기둥에는 6만 개의 뉴런이 담겨 있다. 그리고 이러한 피질 기둥이 신피질 전체에 걸쳐 50만 개 정도 존재한다. 신피질 전체를 따졌을 때, 패턴인식기는 총 3억 개, 뉴런은 총 300억 개 정도 존재하는 것이다. 신피질의 두께는 2mm 정도이며, 이는 패턴인식기 하나의 높이와 같다.
1-3. 신피질 전체에 '모듈(패턴인식기)'이 반복적으로 퍼져 있다.
학습의 기본단위가 뉴런 하나가 아니라 여러 개로 구성된 '모듈'이라는 가설은 스위스의 신경과학자 '헨리 마크램(Henry Markram, 1962~)'의 연구 결과와도 일치한다. '헨리 마크램(Henry Markram)'은 2011년 논문에서 실제 포유류의 신피질 뉴런을 스캔하고 분석함으로써 '피질의 가장 기초적인 단위로서 헵이 주장한 구조를 뒷받침하는 증거'를 찾으려고 했다. 그러나 그가 발견한 것은 '몇몇 뉴런들 사이에 연결성과 시냅스 가중치의 예측성이 매우 높으며 이들은 모두 특정한 제약에 안에서 움직인다.'는 것이었다. 그는 이 집합체의 시냅스 연결은 경험을 통해 쉽게 형성할 수 있는 것이 아니라고 결론을 내리면서, 이들은 지각을 위해 선천적으로 타고난, 레고 블록과 같은 지식의 블록처럼 작동한다. 기억의 습득은 이 블록을 결합해 건축물을 짓는 것과 같다고 추정했다.
'헨리 마크램'이 제안한 레고 블록은 '패턴 인식 마음 이론'에서 설명하는 '패턴인식 모듈(뉴런들의 집합체 모듈)'과 완벽하게 일치한다. '헨리 마크램'은 모듈 하나에 '수십 개의 뉴런'이 담겨있다고 추정했지만, 이는 신피질 5층만을 근거로 계산한 것이다. 5층에는 실제로 뉴런이 풍부하게 존재하지만, 6층에 분포된 뉴런의 일반적인 비율을 고려하면, 모듈에 100개 정도의 뉴런이 추론할 수 있다. 이것은 '패턴 인식 마음 이론'에서 제시한 뉴런의 양과도 일치한다. 신피질에서 발생하는 끊임없는 신경망 형성과 모듈의 존재는 오래전부터 주목받아 왔다. 하지만 뇌가 역동적인 처리 과정을 수행하면서도 안정적으로 모듈을 유지할 수 있는 메커니즘을 입증한 것은 '헨리 마크램'의 연구가 최초라고 할 수 있다.
1-4. '모듈(패턴인식기)'간의 연결방식은 놀라울 정도로 규칙적이다.
'미국 국립보건원(NIH: National Institutes of Health)'과 '미국 국립과학재단(NSF: National Science Foundation)'의 후원을 받아 '매사추세츠 제너럴 병원(Massachusetts General Hospital)'이 수행한 연구는 신피질 전체에 놀라울 정도로 규칙적으로 반복되는 연결 구조가 존재한다는 것을 입증했다. 2012년 3월 '사이언스(Science)'를 통해 발표한 논문에서는 신피질의 연결망이 잘 구획된 도시처럼 격자구조로 이루어져 있다고 설명한다. 뇌의 전체 구조는 기본적으로 맨해튼과 비슷하다. 2차원으로 구획된 거리 위해 수직으로 오르내리는 엘리베이터가 3번째 축을 형성하는 3차원 구조다. '사이언스(Science)'의 팟캐스트에 출연한 신경과학자 '밴 웨딘(Van Wedeen)'은 이 연구의 의미를 다음과 같이 설명했다.
이 연구는 3차원 구조로 되어 있는 뇌의 연결망을 탐구한 것입니다. 지난 수백 년 동안 과학자들이 뇌의 연결망을 상상하면서 떠올린 전형적인 이미지는 접시에 담긴 스파게티와 유사한 것이었습니다. 다시 말해, 서로 밀접한 세포들이 공간적 패턴을 이루며 배열되어 있는 것이 아니라, 제각각 개별적인 연결망으로 복잡하게 얽혀있을 것이라고 생각했습니다. 우리는 'MRI(자기공명영상)'을 활용해 이 문제를 실험적인 방식으로 탐구했습니다. 우리가 밝혀낸 사실은 뇌의 연결명이 가로-세로-수직 세 방향으로 뻗어 있으며, 이 경로들은 모두 평행으로 교차하며 일정한 배열을 형성합니다. 뇌의 연결망은 개별적인 경로들이 마구 뒤엉켜있는 스파게티 모양이 아니라, 단일하고 일관된 구조로 이루어져 있는 것이죠.
'밴 웨딘(Van Wedeen)'의 연구에 의하면, 신피질에 구축된 최초의 연결망은 모듈 그 자체와 마찬가지로 극도로 질서정연하고 반복적이다. 모듈의 격자구조는 신피질에서 '길잡이 연결망(Guide Connectivity)' 역할을 한다. 이러한 구조는 지금껏 연구된 영장류와 인간 뇌에서 한결같이 발견되며, 감각을 처리하는 하위 레벨에서 감정을 다루는 상위 레벨까지 신피질 전체에 걸쳐 뚜렷하게 나타난다. 우리 뇌는 처음부터 개개의 '패턴인식 모듈'이 언제든 연결될 수 있도록 '인프라스트럭처(infrastructure: 사회적 기반 시설)'를 미리 깔아 놓는다. 어떤 모듈이 다른 모듈과 연결하고 싶다고 해서, 그 둘 사이의 물리적 거리를 잇기 위해 한쪽 모듈에서는 축삭을 뻗고 다른 한쪽 모듈에서는 수상돌기를 뻗는 것이 아니다. 언제든 연결될 수 있는 상태이기 때문에, 전기 플러그를 꽂듯이 축삭 하나를 신경섬유의 말단에 꽂기만 하면 된다. 한편, 신피질에서 사용되지 않는 장거리 연결은 결국 끊어진다. 신피질에서 특정 영역이 손상되었을 경우 인접한 영역이 그 기능을 대체하지만, 원래 영역만큼 효율적으로 기능을 발휘하지는 못하는 것도 이 때문이다
1-5. 복잡한 뇌를 어떻게 적절한 수준에서 이해하는가?
이론적으로 화학은 물리학에 기초한 학문이기 때문에, 화학 문제는 물리학의 원리만 적용해도 풀 수 있다. 하지만 이는 매우 까다롭고 현실적으로 실행하기 어려운 일이기에, 화학만의 법칙의 모형이 필요한 것이다. 마찬가지로 물리학에서 열역학법칙을 추론해낼 수 있지만, 일단 '기체'라고 부를 수 있는 입자가 일정 수준 이상 존재하는 상황이 되면, 각 입자의 상호작용을 물리학 공식으로 풀기 어려워진다. 이런 경우에는 열역학법칙이 아주 잘 작동한다는 것을 알 수 있다. 생물학 역시 자신만의 법칙과 모형이 있다. 췌도 세포 하나는 엄청나게 복잡하여, 그것을 분자 수준부터 모형화하려면 상당한 어려움에 부딪힐 것이다. 하지만 인슐린과 소화효소를 조절하는 수준에서 췌장의 실제 기능을 모형화하면 복잡성이 크게 줄어든다.
뇌를 이해하고 모형화하는 작업도 마찬가지다. 뇌의 상호작용을 분자 수준에서 모형화하는 것은 뇌를 분해하여 재창조하는 리버스엔지니어링에서는 분명히 유용하고 필용한 작업이다. 하지만 지금 우리가 추구하는 목표는 뇌가 정보를 처리하여 인지적 의미를 만들어내는 메커니즘을 설명하는 모형을 만드는 것이다.
인공지능 분야의 창시자 중 하나로 인정받는 미국의 과학자 '허버트 사이먼(Herbert A. Simon, 1916~2001)'은 복잡한 시스템을 적절한 수준에서 이해하는 문제를 적절한 수준의 추상적인 언어로 멋지게 설명했다. 1973년에 자신이 고안한 'EPAM(Elementary Percever and Memorizer, 기초적인 인식-기억 장치)'이라는 인공지능 프로그램을 소개하면서 그는 다음과 같이 말했다.
"수수께끼 같은 EPAM 프로그램에 대해 제가 알고 있는 만큼 당신도 알고 싶어 한다고 합시다. 제가 제공할 수 있는 방법은 두 가지 입니다. 하나는... 루틴과 서브루틴의 전체 구조를 포함해 실제 프로그래밍된 방식을 그대로 보여주는 것입니다... 또 다른 하나는, 그러한 내용을 완벽하게 번역해놓은 무미건조한 EPAM의 기계어를 보여주는 것입니다... 어떤 것이 더 인색한 설명이고, 의미 있는 설명이고, 타당한 설명일까요? 하지만 고민할 필요는 없습니다. 저는 세 번째 방법을 가지고 있거든요... 세 번째 방법은 프로그래밍 언어는 하나도 보여주지 않고, 눈앞에 보이는 컴퓨터가 EPAM을 작동할 때 준수해야 할 전자기 등식과 경계조건을 보여주는 것입니다. 이것은 환원성과 불가해성의 절정이라고 할 수 있죠."
1-6. 인간은 논리를 처리하는 약한 반면, 패턴을 인식하는 능력은 뛰어나다.
인간은 논리를 처리하는 능력은 약한 반면, 패턴을 인식하는 능력은 놀라울 정도로 뛰어나다. 신피질은 기본적으로 거대한 패턴인식기라고 할 수 있다. 논리적 변환을 수행하기 위해 최적화된 구조가 아니다. 하지만 논리적인 사고를 하기 위해 우리가 의존하고 활용할 수 있는 기관은 이것밖에 없다.
예컨대 사람이 체스를 두는 방식과 일반적인 컴퓨터 체스 프로그램이 작동하는 방식을 살펴보자. 1997년에 세계 체스 챔피언 '가리 카스파로프(Garry Kasparov, 1963~)'를 이긴 슈퍼컴퓨터 '딥블루(Deep Blue)'는 초당 2억 개의 경우의 수를 분석할 수 있었다. 한편 '가리 카스파로프'에게 말을 이동할 수 있는 경우의 수를 초당 몇 개나 분석해낼 수 있느냐고 물었을 때, 그는 한 개도 어렵다고 대답했다. 그렇다면 그는 어떻게 딥블루와 대등한 경기를 펼칠 수 있었을까? 답은 고도의 훈련을 통해 습득한 강력한 패턴인식능력 덕분이다.
'가리 카스파로프(Garry Kasparov)'는 약 10만 개의 말의 이동경로를 알고 있었다. 이것은 우연한 숫자가 아니다. 어떤 분야든 대략 10만 개의 지식 뭉치를 통달하면 전문가가 될 수 있다. 셰익스피어는 약 10만 개의 어휘로 희곡을 썼다. 물론 개별 단어 수를 따지면 2만 9000개 정도이지만, 그 단어들을 대부분 복합적인 방식으로 사용했다. 의료진들의 지식공유를 위해 구축한 의학 분야 전문가시스템을 분석해 보면, 일반적인 의학전문가들은 자신의 전공분야에서 약 10만 개 정도의 개념을 통달한 것으로 나타났다. 물론 거대한 지식 저장소에서 지식 뭉치의 단위를 파악하는 것은 쉬운 일이 아니다. 하나의 항복이라고 하더라도 매번 경험할 때마다 조금씩 다르게 제시될 수 있기 때문이다.
'가리 카스파로프'는 체스판에 놓인 말을 보면서 자신이 알고 있는 말이 이동할 수 있는 10만 개의 경우의 수를 대조한다. 이러한 10만 번의 대조는 순식간에 일어나며, 눈 깜빡할 사이에 일치하는 것을 찾아낸다. 모든 뉴런이 패턴을 떠올리며 정보를 처리한다. 물론 이것은 모든 뉴런이 동시에 활성화되어야 한다는 의미가 아니다. 만약 그런 일이 일어나면 혼절하고 말 것이다. 패턴을 처리하는 작업은 곧, 뉴런이 활성화될 수 있다는 가능성을 고려하는 것까지 포함하기 때문이다.
1-7. 패턴 처리기가 훨씬 많은 인공 신피질도 등장할 것이다.
인간이 신피질에 저장할 수 있는 패턴은 약 3억 개 정도로 추정된다. 인간의 신피질 속에 총 3억 개의 패턴인식기가 있다고 했으므로, 신피질의 패턴인식기 하나가 패턴 하나를 반복해서 처리한다고 해도 무방할 것이다. 다시 말해, 패턴인식기 하나는 무수한 패턴의 복사본 중 하나를 상징한다.
3억 개라는 숫자가 매우 많거나 매우 적다고 느껴질지도 모르겠다. 어쨌든 호모사피엔스는 이것만 가지고 말과 글, 그리고 온갖 도구와 다양한 발명품을 만들어냈다. 이러한 발명품들은 또 다른 발명을 낳았고, '수확 가속의 법칙(Law of Accelarating Returns)'에 의해, 기술을 기하급수적으로 발전시켰다. 이런 성과는 지구에서 인간을 제외한 그 어떤 종도 이루어내지 못한 성과이다. 물론 침팬지를 비롯한 몇몇 종들 역시 언어를 사용하고 이해하며 원시적 도구를 사용하는 초보적 능력을 가지고 있다. 그들도 신피질을 가지고 있기 때문이다. 하지만 인간에 비해 크기가 상당히 작고, 특히 전두엽이 작다. 인간의 신피질은 자신의 지능을 이해할 수 있는 단계, 더 나아가 인간의 뇌보다 훨씬 강력한 인공지능을 만들어낼 수 있는 단계까지 도달했다. 결국 우리의 뇌는, 자신이 만들어낸 기술의 도움을 받아 3억 개의 패턴 처리기보다 훨씬 많은 패턴을 담아낼 수 있는 인공 신피질을 만드는 단계까지 나아갈 것이다. 이제 인간의 패턴 처리기가 수십억 개, 수백어 개로 늘어날 시대가 눈앞에 다가온 것이다.
2. 계층적 패턴인식의 과정
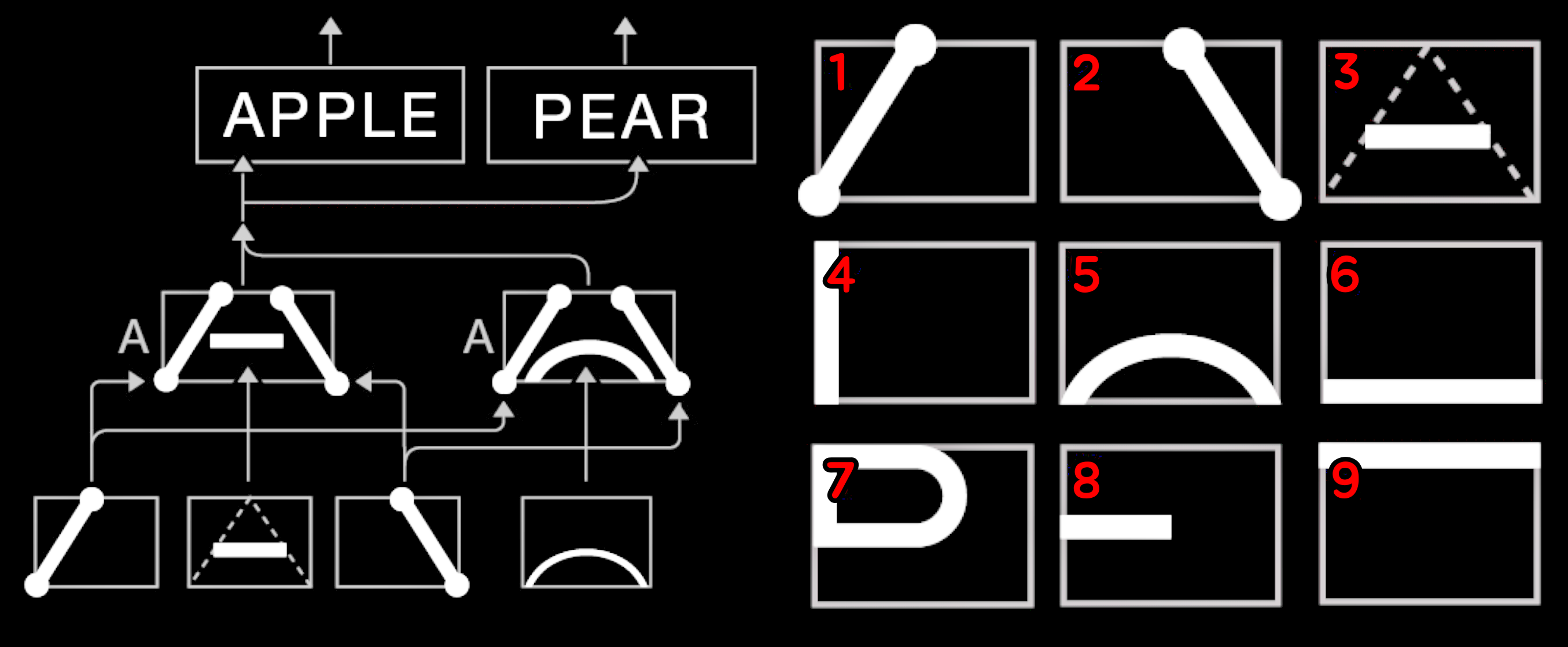
'패턴 인식 마음 이론(Pattern Recognition Theory of Mind)'은 신피질 내 패턴인식 모듈을 기반으로 한다. 앞에서 설명했듯이 패턴 모듈은 모두 계층 구조로 이루어져 있다. 여기에서는 이 이론의 지적 토대가 된 연구들에 대해 간단히 살펴볼 것이다. 2000년대 초반에 발표된 '제프 호킨스(Jeff Hawkins, 1957~)'와 '딜립 조지(Dileep George, 1977~)'의 연구에 대해 설명한다. 신피질에 존재하는 약 3억 개의 패턴인식기가 인식하는 패턴은 제각각 '입력부', '패턴명명부', '출력부' 세 부분으로 구성된다.
- 패턴의 첫 번째 부분은 '입력부'이다. '입력부'는 주요 패턴을 만들어내는 하위 패턴을 구성한다. 하위 레벨 패턴에 붙어 있는 설명은 그것을 참조하는 상위 레벨 패턴에서 활용하지 않을 수 있다. 예컨대 'A'라는 글자를 처리하기 위해서는 'A'를 구성하는 사선 2개와 가로선 하나를 참조해야 하지만, A를 처리하는 패턴들은 각각의 획에 붙어 있는 설명을 가져가지 않고도 그것을 활용할 수 있다.
- 패턴의 두 번째 부분은 '패턴명명부'이다. 인식된 패턴에 이름을 붙이는 곳으로 패턴 처리기에서 뻗어 나온 축삭에 담겨있다. 입력부로 들어온 신호를 종합하여 그것이 자신이 가지고 있는 패턴과 일치하는지 점검하고, 패턴이 일치한다고 판단될 경우 축삭을 활성화한다. 축삭 축삭을 활성화한다는 것은 패턴인식기가 패턴의 이름을 외친다는 뜻이다. "방금 A라는 글자를 봤어!"
- 패턴의 세 번째 부분은 '출력부'로, 상위 레벨 패턴으로 이어진다. A의 경우 'apple'처럼 'A'를 포함하는 단어들이 될 것이다. 어느 레벨이든 어떤 패턴이 인식되면, 그 패턴에 포함된 하위 레벨 패턴에 자극을 촉발한다. 신피질에서 하위 레벨은 수상돌기를 통해 연결된다. 눈여겨봐야 할 것은 '수상돌기(입력을 받는 곳)'는 여러 개지만, '축삭(출력을 내보내는 곳)'은 단 하나라는 것이다. 물론 축삭은 다시 여러 개의 축삭 말단을 통해 여러 개의 수상돌기로 신호를 전달할 수 있다.
여기에서 한 가지 명심해야 할 것은, 어떤 레벨이든 패턴이 된다는 점이다. 단순한 획도 패턴이고, 글자도 패턴이고, 단어도 패턴이다. 어떤 패턴이든 하위 레벨 패턴에서 올라오는 입력과 그렇게 들어온 신호에 기반한 패턴 인식과, 그 결과를 상위 레벨 패턴인식기로 전달하는 출력이 존재한다. 최하위 레벨에 입력되는 데이터는 감각 정보다. 하지만 이러한 정보도 신피질에서 한 레벨만 올라가더라도, 단순한 패턴으로 변모한다.
아래 그림의 왼쪽에서는 '하위 레벨 패턴'이 입력되어 'A"를 구성하는 두 개의 패턴을 만들어내고, 이 패턴은 다시 'A'를 포함하는 단어인 'APPLE'과 'PEAR'이라는 '상위 레벨 패턴'으로 출력되었다. 아래 그림의 오른쪽은 단순한 패턴들은 글자를 구성하는 도형이다. 이러한 패턴들은 '상위 레벨 패턴' 즉, 우리가 '글자'라고 부르는 범주에 속하는 패턴이 된다. (물론 신피질에는 글자라고 구분할 수 있는 범주가 존재하는 것은 아니다.) 예컨대, 1-2-3 패턴이 합쳐지면 A라는 글자로, 1-2-5 패턴이 합쳐져도 A라는 글자로, 4-7 패턴이 합쳐지면 알파벳 P로, 4-6패턴이 합쳐지면 알파벳 L로, 4-6-8-9 패턴이 합쳐지면 알파벳 E로, 하위 레벨 패턴이 입력되어 그 상위 레벨 패턴인 알파벳을 만들어낸다.
2-2. '시각 정보 처리', '청각 정보 처리'도 같은 방식으로 이루어진다.
'시각 정보'나 '청각 정보'를 처리할 때도 이와 똑같은 방식으로 계층적 패턴인식이 이루어진다. 물론 '시각 정보를 처리하는 신피질 영역'과 '청각 정보를 처리하는 영역'과 '글자를 처리하는 신피질 영역'은 다르다. 실제 사과를 바라보았을 때, 하위 레벨 패턴인식기는 곡선을 이루는 사과의 윤곽과 겉에 드러난 색깔 패턴을 탐지할 것이고, 그것이 패턴에 맞다고 판단하면 축삭이 활성화된다. 마찬가지로 소리의 진동수 조합을 탐지하여 청각 피질에 있는 패턴인식기로 정보를 올려보내고, 패턴에 맞다고 판단하면 축삭이 활성화된다.
이 사례에서 제시한 계층 구조는 '개념'의 '물리적 계층 구조'가 아니라 '개념적 계층 구조'라는 점을 명심해야 한다. 실제 패턴인식기들이 물리적으로 층층이 쌓여있는 것은 아니다. 신피질은 매우 얇은 껍질로, 신피질의 두께는 패턴인식기 하나의 높이와 같다. 개별적인 패턴인식기들의 수평적인 연결망이 개념적인 계층구조를 만들어낼 뿐이다.
2-3. 높은 레벨의 패턴을 인식하는 데에는 시간이 더 걸린다.
어떤 레벨의 패턴인식기가 다음 레벨의 패턴인식기로 인식을 전달하는 과정을 다시 생각해 보자. 정보는 기초적인 도형에서 글자로, 글자로 단어로 올라가는 개념적 계층구조를 따라 올라갔다. 이러한 패턴은 다시 단어에서 어절로, 어절에서 더 복잡한 언어구조로 계속해서 올라갈 것이다. 이렇게 레벨을 수십 번 타고 올라가면 '역설'이나 '질투'와 같은 고차원적인 개념까지 도달할 수 있을 것이다.
모든 패턴인식기가 동시에 작동한다고 해도, 이러한 개념적 계층구조를 타고 올라가는 데에는 시간이 걸린다. 인식이 한 단계 높은 레벨로 올라가는 데에는 0.01초~0.1초까지 시간이 걸린다. 실험 결과, 얼굴처럼 비교적 높은 레벨의 패턴을 인식하는 데에는 0.1초 이상 시간이 걸리는 것으로 나타났다. 패턴에 심각한 왜곡이 있을 경우 1초 이상 걸릴 수도 있다.
뇌가 일반적인 컴퓨터처럼 순차적으로 작동한다면, 최하위 패턴부터 차례대로 패턴인식을 수행할 것이다. 하위 레벨 패턴을 모두 고려해야 높은 레벨의 패턴인식을 올라갈 수 있기 때문이다. 그럴 경우, 레벨을 한 번 통과할 때마다 수백만 번의 정보처리 사이클이 돌아가야 한다. 이것은 뇌의 패턴인식 과정을 시뮬레이션할 때 실제로 컴퓨터 안에서 벌어지는 일이다. 하지만 그 시간이 길게 느껴지지 않는 것은, 우리가 장착하고 있는 생물학적 회로보다 컴퓨터가 수백만 배 빠르게 정보를 처리하기 때문이다.
3. 리던던시(Redundancy)
어떤 감각이든, 언어적인 개념이든, 사건에 대한 기억이든, 우리 삶에서 중요하게 여겨지는 항목은 하나의 패턴으로 존재하지 않는다. 중요한 패턴은 어떤 레벨에서나 여러 번 반복되어 입력된다. 이는 단순한 반복일 수도 있지만, 대부분 다른 측면과 시점이 반영된 조금씩 다른 반복이다. 어떤 방향에서든, 어떤 조명에서든 익숙한 얼굴을 알아볼 수 있는 이유도 바로 이러한 '리던던시(Redundancy)' 때문이다. 계층구조를 형성하는 각각의 레벨마다 상당한 리던던시가 존재하고, 이로써 그 개념에 발생할 수 있는 가변성을 충분히 처리해낼 수 있다.
'리던던시(Redundancy)'를 이해하기 위에 apple을 생각해 보자. apple을 가리키는 문자, 소리, 시각의 패턴인식기는 각각 하나만 있는 것이 아니다. apple이라는 신호를 인지하기 위해 활성화되는 패턴인식기는 적어도 수백 개는 될 것이다. 이러한 리던던시로 인해 apple이라는 대상을 정확하게 인식할 가능성은 높아지고, 또한 실재 세계에서 마주칠 수 있는 'apple'의 무수한 변이에도 대처할 수 있는 능력을 갖게 된다.
예컨대 apple이라는 글자의 필체는 제각각 다르기 때문에, 그러한 형태를 처리할 수 있는 많은 수의 패턴인식기가 있어야 apple이라는 글자를 인식할 수 있다. 이미지의 경우도 마찬가지이다. 실제 사과의 모양과 색깔은 제각각 다르기 때문에, 그러한 다양한 형태를 처리할 수 있는 많은 수의 패턴인식기가 있어야 실제 사과를 인식할 수 있다. 청각의 경우도 마찬가지이다. apple이라는 소리도 사람마다 발음, 음높이, 말하는 속도 등이 다르기 때문에 많은 수의 패턴인식기가 있어야 apple이라는 소리를 인식할 수 있다.
'패턴 인식 마음 이론'의 중요한 점은 각각의 패턴인식 모듈 안에서 패턴이 처리되는 방식이다. 패턴 인식기마다 입력된 정보가 일정 수준을 넘어가면 축삭이 활성화되는 '인식의 문턱'이 있다. 자신이 맡은 패턴을 성공적으로 인식했다고 신호를 보내는 것이다. 하지만 입력되는 패턴들이 모두 패턴인식기에서 동일한 비중으로 취급되는 것은 아니다. 수상돌기를 통해 입력되는 정보는 모두 패턴을 인식하는 데, 그 입력이 얼마나 중요한지를 나타내는 가중치가 함께 저장된다. 가중치가 낮은 입력은 생략되어도 상관없지만, 가중치가 높은 입력이 생략되면 축삭이 활성화될 가능성은 낮아진다.
3-1. 신피질은 얼마나 많은 패턴을 저장할 수 있을까?
그러면 신피질은 얼마나 많은 패턴을 저장할 수 있을까? 여기서도 '리던던시(Reundancy)'라는 현상을 고려해야 한다. 예컨대 우리는 연인의 얼굴을 단 한 번에 저장하는 것이 아니다. 수천 번 입력된 정보가 저장되는 것이다. 그중에는 똑같은 이미지가 반복되어 입력되는 경우도 있겠지만, 대부분 조명이나 표정이나 시점 등에 따라 제각가 달라 보이는 얼굴의 이미지가 입력된다. 하지만 우리 뇌는 컴퓨터와 달리 이미지 자체를 저장하는 것이 아니라, 패턴을 구성하는 요소들이 반복되어 입력되면서 그 자체로 '패턴'을 만드는 '특성의 리스트'로 저장된다.
전문가의 핵심 지식이 약 10만 개의 '지식 뭉치' 패턴으로 이루어져 있다고 할 때, 1개의 지식마다 약 100번의 리던던시가 입력되어야 한다고 가정하면, 약 1000만 개의 패턴이 입력되어야 한다. 그런데 전문지식 중에서도 핵심적인 내용은 좀 더 보편적이고, 광범위한 전문지식을 기반으로 성립되기 때문에 입력되어야 할 패턴은 3000만 개~5000만 개까지 치솟을 수 있다.
흔히 '상식'이라고 하는 지식이 우리 머릿속에 자리 잡기 위해서는 이보다 훨씬 많은 리던던시가 입력되어야 할 것이다. 소위 '거리의 지식'은 '책상머리 지식'보다 훨씬 많은 신피질의 작동을 요구한다. 책상머리 지식을 습득하는 데 100개의 패턴을 입력해야 한다면, 거리의 지식을 습득하기 위해서는 1억 개가 넘는 패턴을 입력해야 한다. 물론 리던던시 횟수는 고정된 것은 아니다. 아주 일상적인 패턴은 수천 번을 반복 입력해야 겨우 습득할 수 있지만, 아주 새로운 현상은 10번만 반복해도 습득할 수 있다.
4. 파라미터는 어떻게 작동하는가?
또한 활성화된 입력 정보의 수가 많다고 해서 패턴인식 모듈이 인식에 성공하는 것은 아니다. 가중치 파라미터를 적용한다고 해도 마찬가지이다. 입력 정보의 크기도 고려해야 한다. 그 입력 정보의 예상되는 '크기를 나타내는 파라미터'가 있고, 또 그 '크기가 얼마나 가변적인지 나타내는 파라미터'가 있다. 즉, 이러한 정보는 '예상되는 크기'와 '그 크기의 가변성'이라는 두 개의 수치로 코딩하여 입력할 수 있다.
- 음성 피라미터: 이러한 파라미터가 어떻게 작동하는지 쉽게 설명하기 위해 'steep'라는 음성 단어의 인식을 맡은 패턴인식기가 있다고 가정해 보자. 이 단어는 [s], [t], [E], [p]이라는 4개의 소리를 가지고 있다. [t] 음소는 '치음'으로, 혀끝을 윗잇몸에 대면서 공기의 마찰을 일으켜 만들어 내는 소리다. [t] 음소를 길게 발음하기란 애당초 불가능하다. [p] 음소는 '폐쇄음' 또는 '파열음'이라고 하는데, 이는 성도를 닫았다가 순간적으로 공기를 터트리듯 내보내면서 내는 소리다. 치찰음의 지속시간은 대개 [E]같은 장모음보다 짧지만, 이 역시 가변적이다. 음성 패턴들을 인식하기 위해서는 이러한 정보들이 인코딩되어야 한다. 예컨대 'step'과 'steep'은 매우 비슷하다. step의 [e]음소와 steep의 [E]음소는 공명진동이 다른 모음이지만 이런 차이에 의존하여 두 단어를 신뢰할 수 있는 수준으로 구별하는 것은 쉽지 않다. 하지만 step의 [e] 모음이 steep의 [E] 모음보다 비교적 짧게 발음된다는 사실까지 감안하면 두 단어를 훨씬 구별하기 쉬워진다. steep에서 [t]와 [p]는 예상되는 지속시간이 매우 짧고 예상되는 가변성도 작다. 반면, [s]는 지속시간이 짧은 것으로 예상되지만 길게 발음될 수도 있기 때문에 '가변성'이 크다. [E]는 예상 지속시간이 길지만 이 역시 가변성이 크다.
- 글자 피라미터: 소리 기호를 인식하는 경우에는 '크기 피라미터'가 발음의 지속시간을 의미하지만, 글자 기호를 인식하는 경우에는 상대적인 공간 크기를 의미한다. 예컨대 i라는 글자의 경우, 위의 점은 아래 막대보다 훨씬 작은 면적을 차지할 것으로 예상된다. 추상적인 개념을 다루는 신피질의 훨씬 높은 레벨에서는 매력, 역설, 행복, 좌절처럼 연속선 위에 존재하는 다양한 패턴도 다뤄야 한다. 신피질도 이러한 연속선 위에 존재하는 추상적인 패턴의 차이를 구분할 수 있다.
패턴인식 모듈이 하는 일은, 자신이 인식을 담당한 패턴이 실제로 유효한 입력에 의해 나타날 확률을 계산하는 것이다. 다시 말해, 이전 경험에 비춰봤을 때, 어느 정도 입력값이 반복되면 유사한 패턴이라고 판정할 것인지를 계산하는 것이다. 하위 레벨의 패턴인식기가 모두 활성화된다면, 다시 말해 하위 레벨 패턴이 모두 인식되면, 모듈로 들어오는 입력이 모두 활성화될 것이다. 또한 각각의 입력에 인코딩되어 들어오는 관찰된 크기를 패턴인식 모듈은 자신이 저장해놓은 크기 파라미터와 비교하여 패턴이 인식될 확률을 계산한다. '뇌'와 '인공지능시스템'은 결국 다음 3가지 요소를 고려하여, 자신이 인식을 담당한 패턴이 나타날 확률을 종합적으로 계산한다. 이러한 각각의 지표들을 계산하여 우리 뇌는 거대한 인식을 만들어내는 것이다.
- 관찰된 크기를 표시하는 파라미터가 인코딩되어 있는 입력 정보
- 입력 정보의 크기를 대조할 수 있던 파라미터
- 입력 정보의 가중치를 표시하는 파라미터
4-1. '생물학적 뇌'와 '인공지능 시스템'에서의 파라미터
생물학적 뇌의 경우, 이러한 파라미터들은 뇌 자신의 경험을 통해 입력된다. 음소 지식은 태어날 때부터 뇌에 존재하는 것이 아니다. 또한 언어마다 음소 단위는 크게 달라진다. 패턴마다 예상할 수 있는 입력 분포를 알아내려면 다양한 패턴 사례를 경험해야 한다. 이는 각각의 패턴인식기가 학습한 파라미터 속에 다양한 패턴 사례들이 인코딩되어 있다는 뜻이다.
과거 인공지능시스템에서는 언어학자들을 초빙하여, 앞에서 설명한 것처럼 음소들의 특성과 예상 지속시간 등을 표시한 파라미터를 수작업으로 입력했다. 하지만 인공지능시스템 역시 우리 뇌가 학습하는 방식과 유사하게 견본 데이터를 학습함으로써 스스로 이러한 파라미터를 발견해 내는 것이 훨씬 뛰어난 성능을 발휘한다. 물론 이 두 가지 방법을 모두 적용하면 더욱 좋다. 다시 말해, 초기 시스템을 구축할 때는 사람의 직관력의 도움을 받아 파라미터를 직접 입력하고, 그다음부터는 인공지능시스템의 발화의 실제 사례를 학습함으로써 패턴을 정교하게 다듬어 나가는 것이다.
5. 자동 연상
우리는 패턴이 완벽한 형태로 제시되지 않아도, 심지어 패턴이 상당이 왜곡되어 있어도 우리는 그것을 어렵지 않게 인식할 수 있다. 이것이 가능한 첫 번째 이유는 뇌의 자동 연상 기능 때문이다. '자동 연상(Autoassociation)'이란 패턴의 일부만으로 패턴 전체를 연상해 내는 능력으로, 패턴인식기 하나하나가 기본적으로 이러한 기능을 지원할 수 있도록 설계되어 있다.
5-1. 예상되는 입력의 '인식의 문턱'을 낮추거나 '입력을 가중치'를 높여준다.
하위 레벨의 패턴인식기에서 올라오는 입력은 제각각 처리 과정을 거쳐 상위 레벨의 패턴인식기로 올라가는데, 이렇나 정보 연결 과정에는 '가중치'가 고려된다. 다시 말해 패턴 안에서 그것이 얼마나 중요한지를 표시하는 것이다. 따라서 패턴의 가중치가 클수록 '인식했다'고 활성화할 것인가 말 것인가 판단할 때 더 중요한 요소로 고려된다. 예컨대 아인슈타인의 혀를 내미 표정, 침착맨의 구렛나룻와 수염은 그들의 외모를 학습하는 패턴에서 높은 가중치를 더해줄 것이다. 따라서 몇 가지 요인들이 결여되어 인식할 수 있는 가능성이 낮아지더라도, 각각 요인의 가중치에 따라 '인식의 문턱'은 충분히 넘을 수 있다. 하지만 패턴이 나타날 전반적인 가능성을 계산해내기 위해서는, '크기 파라미터'도 고려해야하기 때문에 단순히 총합을 가는 것보다 훨씬 복잡하다.
상위 레벨의 패턴인식기로부터 '패턴이 곧 나타날 것으로 예상된다'는 신호를 받았을 때, 인식의 문턱은 크게 낮아진다. 또는 그러한 신호가 예상되는 입력의 가중치를 크게 높여줌으로써 몇 가지 요인이 결여되어 있더라도 이를 충분히 보완해 줄 수도 있다. 어떤 방식으로 작동하든, 이러한 예측은 패턴인식기가 쉽게 활성화되도록 유도한다. 이런 현상은 또한 어느 레벨에서나 일어난다. '얼굴'과 같은 패턴은 최하위 레벨에서 몇 단계 위에 위치하는 패턴이기 때문에, 몇몇 특징이 생략된다 하더라도 우리는 그것을 어렵지 않게 인식할 수 있다.
예컨대 우리가 왼쪽에서 오른쪽으로 'A', 'P', 'P', 'L'이라는 글자를 인식했다고 하자. 'APPLE'이라는 단어를 인식한 패턴인식기는 곧이어 'E'가 나오리라 예상할 것이고, 'E' 인식기에 곧 E 패턴이 나타날 확률이 매우 높으니 준비하라는 신호를 내려보낼 것이다. 그러면 'E' 인식기는 'E'를 인식할 가능성을 더욱 높이기 위해 인식의 문턱을 낮춘다. 그다음에 나타난 실제 이미지가 'E'처럼 보이기는 하지만 '일반적인' 상황에서라면 'E'라고 인식할 수 없을 만큼 희미한 상태라고 해도 'E' 인식기는 예상하고 있던 글자인 만큼 실제로 'E'를 보았다고 생각하고 활성화할 것이다.
5-2. 불변이성
변형되거나 왜곡된 패턴이라도 어렵지 않게 인식할 수 있는 또 다른 이유는 '불변이성'이다. '불변이성(invariance)'이란 패턴에 변이가 발생한 경우에도 그것을 일관되게 인식하는 능력으로, 이는 4가지 방식으로 작동한다.
- 데이터 변형: 첫 번째 방식은 신피질이 감각 데이터를 받아들이기 전에 포괄적인 변형이 일어난다.
- 리던던시(Redundancy): 두 번째 방식은 피질의 패턴 기억에 존재하는 리던던시를 활용하는 것이다. 특히 중요한 항목의 경우 패턴마다 다양한 측면과 시점에서 인지한 수많은 변이들을 제각각 적용하고 처리한다.
- 리스트의 확대 적용: 세 번째 방식은 가장 강력한 방법으로, 특정한 리스트를 다른 분야까지 확대 적용하는 것이다. 어떤 범주에 속하는 패턴에서 발생하는 다양한 변이를 학습하여 그것을 하나의 리스트로 만들고, 이렇게 만든 리스트를 다른 범주에 속하는 패턴에도 그대로 적용할 수 있다. 은유나 직유와 같은 언어현상도 바로 이러한 '리스트의 확대 적용'의 결과로 이해할 수 있다.
- 크기 파라미터 활용: 네 번째 방식은 크기 파라미터를 활용하여 모듈에 여러 가지 변형된 패턴을 인코딩하는 것이다. 예컨대 'steep'이라는 단어를 여러 차례 들었다면, 이 음성단어를 인식하는 패턴 인식 모듈은 [E]의 지속시간의 예상가변성이 높다는 것을 표시함으로써, 다양한 발화현상을 하나의 모듈에 인코딩할 수 있다. [E]가 포함된 단어들이 모두 이러한 현상을 공유한다면, [E]에 할당된 패턴인식기는 그러한 가변성을 아예 고정된 변수로 코딩할 수도 있다. 하지만 [E]가 포함된 단어마다 예상되는 가변성의 크기는 다르다. 예컨데 'peak'의 [E] 음소는 'steep'의 [E] 음소만큼 길게 늘어지지 않는다.
6. '기억'은 '인식'을 위해 존재한다.
우리가 보는 시각 데이터는 최소한 2차원 정보이다. 얼굴을 볼 때 반드시 눈 먼저 보고 다음에 코를 보는 것은 아니기 때문이다. 우리가 듣는 청각 데이터도 최소한 2차원 정보이다. 여러 개의 악기나 목소리가 동시에 소리를 만들어낼 수 있기 때문이다. 우리다 느끼는 촉각 데이터도 최소한 2차원적 정보이다. 우리의 피부 자체가 기본적으로 2차원 감각이기 때문이다. 그리고 이러한 패턴은 시간이라는 새로운 차원이 더해지면서 3차원 데이터가 된다. 따라서 신피질의 패턴 처리에 입력되는 정보는 3차원 또는 적어도 2차원으로 이루어져 있다. 그런데 신피질 구조에서 패턴은 1차원, 즉 리스트처럼 순차적으로 입력될 수밖에 없다. 일단, 패턴 그 자체가 2차원이나 3차원 정보를 반영한다고 하더라도, 각각의 패턴 처리기에 입력되는 것은 1차원적 리스트라는 것을 기억해 주기 바란다.
우리가 대상을 인식하기 위해 패턴을 학습하는 것은, 기억의 토대를 이루는 메커니즘과 완벽하게 동일하다. 예컨대 실제 개를 보았을 때, 우리 기억은 '개'에 대한 보편적인 이데아 역할을 하고, 연주곡 을 들었을 때 우리 기억은 악보 역할을 한다. 실제로 기억은 우리가 학습하고 인식한 패턴의 리스트로 적절한 자극이 주어졌을 때, 그것을 파악하기 위한 판단 기준이 된다. 결국, 신피질에서 '기억(Memory)'은 '인식(Congnition)'을 위해 존재하는 것이다.
기억은 또는 또 다른 기억에 의해 촉발되어야 한다. 패턴을 인식할 때도 이러한 촉발 메커니즘을 경험할 수 있다. 'A', 'P', 'P', 'L'을 지각하면 'APPLE' 패턴은 다음에 E를 보게 될 것을 예측하고, 'E' 패턴이 곧 나타날 것이라는 신호를 촉발한다. 따라서 신피질은 우리가 실제로 'E'를 보기 전부터 'E'를 보게 될 것이라고 '생각'한다. 피질에서 이러한 상호작용이 주목받으면 'E'를 보기 전에도, 심지어 'E'를 찾을 수 없을 때에도 'E'를 떠올릴 것이다.
기억에서도 이와 유사한 메커니즘이 작동한다. 일반적으로 그러한 연상에는 완벽한 사슬이 존재한다. 오래된 기억을 촉발한 기억을 어렴풋하게 인식한다고 해도, 그것이 무엇인지 분명히 알 수 없다. 과거의 기억이 갑자기 튀어나오는 것처럼 보이는 이유도 그 때문이다. 하지만 몇 년씩 잠잠하게 묻혀있던 기억이 표면에 떠오르기 위해서는 어떤 '촉발'이 있어야 한다는 점은 명백하다. 기억은 그것을 촉발하는 기억이 사라지면 잊힐 수 있다.
6-1. 전체를 완벽하게 복사하지 않는 한, 기억을 해석해 내는 것은 사실상 불가능하다.
우리는 기억을 통해 생각한다. 기억은 모두 패턴의 나열로 저장되는데, 이러한 패턴에는 단어나 소리나 그림이나 비디오로 된 첨부파일이 달려 있찌 않다. 실제 이미지가 마음속에 존재하는 것이 아니기 때문에, 중요한 사건을 머릿속에 떠올리고자 할 때, 우리는 마음속에 저장된 패턴을 재구성해 이미지를 다시 만들어내야 한다.
따라서 누군가의 마음을 읽어서 그 사람의 신피질에서 무슨 일이 일어나고 있는지 알아낼 수 있다고 해도, 그 사람의 기억을 해석해 내는 것은 쉽지 않다. 무엇인가 촉발해 주기만을 기다리며 신피질에 저장되어 있는 패턴은 물론, 이미 촉발되어 활성화된 상태의 패턴 역시 마찬가지이다. 우리 눈에는 동시다발적으로 활성화되는 수백만 개의 패턴인식기만이 보일 것이다. 그리고 또 0.01초 뒤에는 그러한 패턴인식기로 인해 또 다른 패턴인식기들이 활성화되는 상태를 목격할 수 있을 것이다. 그러한 패턴은 다른 패턴의 리스트가 되고, 그 리스트는 또 다른 패턴의 리스트가 된다. 이런 과정은 최하위 레벨의 가장 기초적이고 단순한 패턴에 도달할 때까지 계속 반복된다.
전체 레벨의 정보를 모두 내 피질로 완벽하게 복사하지 않는 한, 더 높은 레벨의 패턴이 무엇을 의미하는지 해석하는 것은 사실상 불가능하다. 신피질 내에 존재하는 각각의 패턴은 그 아래 레벨에서 올라오는 정보 측면에서만 의미를 지니기 때문이다. 더 나아가 어떤 패턴이든 같은 레벨에 있는 다른 패턴은 물론 그보다 높은 레벨에 있는 패턴도 알아야 해석할 수 있다. 그런 패턴들이 '의미의 맥락'을 제공하기 때문이다. 결국 뇌에서 활성화된 연관된 축삭을 감지하는 것만으로는 그 사람의 마음을 온전히 읽어낼 수 없다. 사실상 그 사람의 신피질 전체에 저장되어 있는 기억을 모두 샅샅이 훑지 않는 한 활성화된 축삭이 무엇을 의미하는지 이해할 수 없다.
7. 정보처리 메커니즘의 보편성
7-1. 뇌가소성의 개념이 만들어지다.
학습의 신경학적 기초를 설명하고자 시도한 최초의 인물은 캐나다의 심리학자 '도널드 헵(Donald O. Hebb, 1944~1985)'이다. 1949년에 그는 뉴런이 경험에 기반하여 생리적으로 변화하는 메커니즘을 규명해냄으로써, '학습'과 '뇌가소성(Neuroplasticity)'의 기초를 개념을 제공했다.
'헵학습(Hebbian Learning)'이라는 이름으로 유명한 이 이론의 핵심은 '함께 활성화되는 세포는 연결된다.'는 것이다. '도널드 헵'의 이론은 여러 측면에서 사실로 입증되었으며, 특히 뇌의 활동에 기반해 새로운 연결을 만들어내고 강화함으로써 뇌의 구조가 달라진다는 것 역시 사실로 밝혀졌다. 또 오늘날에는 뇌스캔을 통해, 실제로 뉴런이 그러한 연결을 형성하는 과정을 두 눈으로 관찰할 수 있게 되었다. 또 '인공 신경망(Artificial Neural Network)' 역시 헵의 신경 학습 모형을 기반으로 설계된다.
헵의 이론에서는 기본적으로 학습의 기본단위를 '뉴런(Neuron)'이라고 가정하였다. 하지만 '패턴 인식 마음 이론(Pattern Recognition Theory of Mind)'은 '헵의 이론'과 다르다. '패턴 인식 마음 이론'에서는 학습의 기본단위가 뉴런 1개가 아니라 뉴런 100개 정도가 모인 뉴런의 집합, 즉 패턴인식기라고 가정한다. 또한 패턴인식기 속 뉴런들의 연결망과 시냅스의 세기는 비교적 안정적이며, 유전적으로 결정되어 있는 것 같다. 다시 말해 패턴인식 모듈의 내부 구조는 태어나기 전부터 설계되어 있는 것이다. 학습은 패턴인식기 '내부'에서 벌어지는 것이 아니라, 패턴인식기 '바깥'에서 벌어진다. 즉, 패턴인식기와 패턴인식기를 연결하는 '사이'에서 일어난다. 다시 말해 패턴인식기를 연결하는 시냅스의 세기에 따라 학습이 일어난다.
7-2. 뇌 가소성
신피질의 정보처리 방식이 보편적이라는 것을 보여주는 가장 강력한 증거는 '뇌의 가소성'이다. '가소성(Plasticity)'은 학습을 통해 뇌의 연결망이 달라지거나, 어느 한 영역의 역할을 다른 영역이 대신할 수 있는 특성으로, 이는 신피질 전체에 공통된 알고리즘이 작동한다는 뜻이다. 지금까지 신경과학 연구는 대부분 신피질의 어느 영역이 어떤 형태의 패턴을 관장하는지 알아내는 데 초점을 맞췄다. 이것을 확인하는 고전적 기법은 부상이나 뇌졸중으로 인한 뇌손상을 이용해, '손상된 특정 영역'과 '상실된 기능'의 연관성을 입증하는 것이다. 예컨대 '방추 모양 주름(fusiform gyrus)' 부위가 손상된 사람이 갑자기 사람들의 얼굴을 잘 알아보지 못한다면, 이 영역이 얼굴인식과 관련된 일을 한다는 가설을 세울 수 있다. 이러한 가설의 전제는 뇌가 영역마다 특정한 유형의 패턴을 인식하고 처리하도록 설계되어 있다는 것이다. 하지만 어떤 이유로 인해 정보가 흘러가야 할 정상적인 경로가 막힌다면, 신피질의 다른 영역이 손상된 영역이 수행하던 기능을 대신하는데, 이것이 바로 뇌의 '가소성' 덕분이다.
부상이나 뇌졸증으로 뇌 손상을 입은 환자들이 신피질의 다른 영역을 활용해, 손상된 영역의 기능을 다시 학습할 수 있다는 사실이 밝혀지면서 '뇌가소성'은 크게 주목받기 시작했다. 가소성의 가장 극적인 사례는 2011년 미국의 신경과학자 '마리나 베드니(Marina Bedny)'가 동료 연구진들과 함께 선천적 맹인들의 시각피질을 연구한 결과일 것이다. 이전까지의 상식으로는 V1과 V2 같은 시각피질의 하위 레벨에서는 모서리와 곡선 같은 차원이 매우 낮은 패턴을 처리하고, 가장 최근에 진화된 피질 영역인 '전두엽'은 언어를 비롯한 추상적인 개념을 담은 훨씬 복잡하고 미묘한 패턴들을 처리한다는 것이었다.
7-3. 패턴을 처리하는 영역이 서로 기능을 대체할 수 있다.
하지만 '마리나 베드니(Marina Bedny)'는 전혀 뜻밖의 사실을 발견했다. 진화를 통해 인간만이 갖게 된 '언어 처리 능력'은 지금까지 왼쪽 전두엽과 측두엽 피질에서 발휘되는 것으로 여겨져 왔다. 하지만 선천적인 맹인들의 경우, 일부 언어기능을 수행할 때 시각피질이 활성화되는 것으로 나타났다. 더 나아가 시각피질의 활동이 실제로 언어 처리를 담당하고 있다는 증거를 찾아냈다. 선천적 맹인의 왼쪽 시각피질은 언어를 관장하는 영역과 거의 유사하게 작동하는 것으로 드러났다. 결론적으로, 시작처리를 위해 진화했다고 여겨졌던 뇌 영역도 초기 경험을 통해 언어를 처리하는 기능을 수행할 수 있는 것이다. 즉, 물리적으로 비교적 멀리 떨어져 있는 신피질 영역, 또 '기초적인 시각 정보'와 '추상적인 언어 개념' 처럼 개념적으로 매우 다르다고 여겨지는 영역이 본질적으로 똑같은 알고리즘을 사용하고 있다는 것이다. 따라서 아무런 공통점도 없어 보이는 패턴을 처리하는 영역이 서로 기능을 대체할 수 있다.
UC버클리의 신경과학자 '대니얼 펠드먼(Daniel E. Feldman)'은 2009년 '신피질의 가소성에 작동하는 시냅스 메커니즘(Synaptic mechanisms for plasticity in neocortex)'이라고 하는 논문에서, 신피질 전체에 이러한 유형의 가소성이 존재한다는 증거를 찾아냈다. 그에 의하면, 뇌는 가소성 덕분에 감각 세계에서 패턴을 익히고 기억할 수 있으며, 움직임을 개선하고, 부상 후 기능을 회복할 수 있다고 한다. 또한 이러한 가소성을 가능케 하는 것은 피질 속 '시냅스'와 '수상돌기의 형성/제거', '형태학적 변형을 포괄하는 구조적 변화'라고 덧붙였다.
7-4. 기능을 대체하더라도, 원래 영역만큼 뛰어난 기능을 발휘하지는 못하는 이유
UC버클리의 과학자들은 '신피질의 가소성(신피질 알고리즘의 균일성)'을 입증하는 또 다른 놀라운 연구를 발표했다. 쥐들을 대상으로 한 실험에서, 수염을 움직임을 통제하는 운동피질 영역에서 나오는 뇌 신호를 포착할 수 있도록 미세전극칩을 이식했다. 쥐들이 특정한 감정적 상태를 경험할 때 뉴런이 활성화되면서도, 실제로 수염이 움직이지 않으면 보상을 제공하도록 실험을 설계했다. 정상적인 상황에서는 이러한 감정적 상태에서 이들 뉴런을 작동하지 않았다. 그럼에도 쥐들은 보상을 얻기 위해 움직임을 통제하는 운동뉴런을 '정신적으로' 분리해내 운동뉴런으로 감정을 처리하는 놀라운 묘기를 부렸다. 이 실험의 결론은, 신피질에서 근육의 움직임을 통제하는 '운동피질 영역' 역시 표준적인 신피질 알고리즘을 사용한다는 것이다.
하지만 손상된 피질 영역을 다른 영역이 대체하여 새롭게 지식이나 기술을 학습한다고 해도 대부분 원래 영역만큼 뛰어난 기능은 발휘하지 못했다. 어떤 시스템으로든 다른 시스템을 대체하는 것이 불가능한 것은 아니지만, 성능이 크게 떨어진다. 이처럼 가소성에 한계가 존재하는 데에는 몇 가지 이유가 있다.
- 첫 번째, 평생에 걸쳐 습득하고 완벽하게 다듬어야 하는 기술도 있는데, 그런 기술을 다른 피질 영역을 활용에 다시 습득해야 한다면, 당장 똑같은 결과를 얻을 수 없다.
- 두 번째, 무엇보다도 그 기술을 수행하는 피질 영역의 크기가 줄어든다. 손상된 영역을 대체할 영역이 아무 일도 하지 않고 빈둥거리고 있던 것은 아니다. 그 영역도 자신이 맡은 본래의 기능을 수행하고 있는 상태였기 때문에, 손상된 영역이 하던 일까지 떠맡기 위해서는 기존에 처리하던 업무 중 일부를 포기해야 한다. 이런 상황에서 가장 먼저 새로운 업무에 할당될 피질 영역은 리던던시 패턴을 저장하고 있는 모듈이다. 어쨌든 리던던시 패턴이 삭제되면 기존에 문제없이 처리하던 업무의 질도 미묘하게 떨어질 것이며, 새로 학습하는 기술 역시 원래 활용하던 피질 공간만큼 충분히 활용하지 못하기 때문에 제대로 발휘되지 못한다.
- 세 번째, 우리의 뇌는 '특정 형태의 패턴'을 '특정 뇌 영역'에서 가장 잘 처리할 수 있도록 최적화되어있다. 예컨대 얼굴인식은 방추모양주름에서 가장 잘 처리한다. 우리는 이러한 최적화 작업을 위해 자연적인 생명현상을 시뮬레이션한 '유전적 진화 알고리즘'을 사용한다.
8. 학습
8-1. 학습은 태어나기 전부터 시작된다.
우리가 세상에 처음 태어났을 때, 신피질에는 어떠한 패턴도 채워져 있지 않다. 처음 뇌가 만들어졌을 때, 신피질은 백지와 같은 상태로 존재한다. 신피질은 학습능력과 패턴 인식기들을 연결하는 능력을 가지고 태어나지만, 그러한 연결은 경험에서 나오는 것이다. 인간의 학습은 태어나기 전부터 시작된다. 뇌가 만들어지는 생물학적 발생 과정과 동시에 학습은 시작된다. 정자와 난자가 수정된 지 한 달도 되지 않은 시점에 뇌는 이미 형성된다. 물론 이렇게 처음 만들어진 뇌는 사실상 파충류의 뇌에 가깝지만, 약 20주 정도 되는 짧은 시간 동안 거대한 생물학적 진화가 자궁 속에서 벌어진다. 수정 후 26주가 되면, 태아의 뇌는 이제 신피질을 갖춘 완벽한 인간의 뇌로 탈바꿈한다. 수정 후 28주부터는 거의 하루 종일 눈을 뜨고 있다. 자궁 안에는 볼 것이 별로 없지만, 빛과 어둠을 감지할 수 있다. 태아의 신피질은 이러한 시각적 패턴을 처리하기 시작한다. 이처럼 우리는 자궁 안에서 이미 얼마간의 경험을 학습하고 태어난다. 그리고 태아의 신피질은 그동안 쌓아온 경험을 바탕으로 본격적으로 학습을 시작한다.
태아는 소리도 들을 수 있는데, 특히 엄마의 심장소리가 가장 크게 들린다. 음악의 리드미컬한 속성이 인류문화에 보편적으로 나타나는 현상은 아마 이 때문일 것이다. 지금까지 발견된 인류 문명 중에서, 그림과 같은 시각예술이 없는 문명은 있어도 음악이 없는 문명은 없었다. 또한 음악의 박자는 심장 박동 수와 거의 일치한다. 물론 음악의 박자는 다양하지만, 그렇지 않으면 우리의 관심을 끌지 못할 것이다. 심장 박동 수 역시 마찬가지로 다양하다. 실제로 심장박동이 지나치게 규칙적인 경우, 그것은 오히려 심장에 병이 있는 징후라고 한다.
인간의 지능에서 학습은 대단히 중요한 역할을 한다. 실제로 '인간의 신피질'과 '신피질이 제대로 작동할 수 있도록 뒷받침해 주는 다른 뇌 영역(해마와 시상 등)'을 컴퓨터로 완벽하게 모형화해도, 별다른 능력을 발휘하지 못한다. 이는 신생아의 뇌가 할 수 없는 일이 별로 없는 것과 똑같다. 그래서 신생아가 살아남기 위해 선택하는 핵심적인 생존 전략은 '귀여운 외양'이다.
8-2. 학습과 인지는 동시에 발생한다.
'학습(Learning)'과 '인지(Recognition)'는 동시에 발생한다. 정보가 입력되는 것이 곧 '학습'이고, 패턴을 학습하는 것이 곧 그것을 '인지'하는 것이다. 신피질은 끊임없이 들어오는 입력을 이해하기 위해 끊임없이 노력한다. 어떤 레벨에서 패턴을 제대로 처리하거나 인식하지 못하면, 그 패턴은 다음 상위 레벨로 보내진다. 어떤 레벨에서도 패턴을 인식하는 데 성공하지 못하면, 그것은 새로운 패턴으로 간주된다. 하지만 새로운 패턴으로 분류한다고 해서, 그 패턴의 모든 양상이 새롭다는 뜻은 아니다. '고양이 얼굴'에 '코끼리 코'가 달린 그림을 보면, 우리는 구별되는 개별적 특징을 인식하겠지만, 이렇게 결합된 패턴이 뭔가 새롭다는 것을 알아차리고 그것을 기억할 것이다. 고양이와 코끼리가 결합된 얼굴처럼 새로운 기억은 비어있는 패턴인식기에 저장한다.
고양이와 코끼리가 결합된 얼굴은 다양한 방식으로 우리 기억 속에 저장될 것이다. 제대로 인식된 기억은 새로운 패턴을 만들어내 '리던던시(Redundancy)'를 더욱 풍부하게 만들 수 있다. 패턴이 제대로 인식되지 않는다면, 기존에 인식했던 항목의 새로운 측면을 반영하는 것으로 저장될 확률이 높다. 그리고 그림과 더불어 '예술가', '상황', '그림을 처음 본 순간의 느낌', '그림을 보면서 친구와 나눈 대화' 등 다양한 맥락이 함께 저장될 것이다.
8-3. 패턴 저장의 유효 한계
그러면 어떤 패턴을 저장할 것인지를 판단하는 포괄적인 기준을 무엇일까? 이 질문은 수학 용어를 사용하면 '패턴 저장의 유효 한계를 활용하여, 지금까지 제시된 입력 패턴을 최적화하여 보여줄 수 있는가?'라고 진술할 수 있다. 정확한 패턴인식을 위해 일정한 리던던시를 허용하는 것은 물론 타당하지만, 활용할 수 있는 저장 영역인 '신피질 전체'를 반복되는 패턴으로 모두 채워버리는 것은 전혀 실용적이 않을 것이다. 그러면 다른 패턴을 제대로 저장 수 없기 때문이다.
예컨대 음성 언어에서 [E] 음소와 같은 패턴을 무수히 경험한다. 이것은 특정한 음성주파수를 상징하는 단순한 패턴이지만, 의심할 여지없이 신피질에는 상당한 '리던던시(Redundancy)'가 존재할 것이다. 우리는 [E] 음소의 다양한 변이들로 신피질 전체를 채울 수도 있을 것이다. 우리는 [E] 음소의 다양한 변이들로 신피질 전체를 채울 수도 있을 것이다. 하지만 유용한 리던던시에는 한계가 있으며, 이처럼 흔하게 접할 수 있느 패턴은 그 한계만큼 이미 저장 공간을 가득 채우고 있을 것임이 분명하다.
그렇다면 구체적으로 몇 개 정도 리던던시를 허용하는 것이 좋을까? 이러한 최적화 문제를 해결할 수 있는 수학적 해법이 존재하는데, 바로 '선형계획법(Linear Programming)'이라고 하는 해법이다. '선형계획법'은 '제한된 자원(이 경우 학습에 활용되는 패턴인식기)'의 최적 할당량을 계산해 내는 공식이다. '선형계획법'은 1차원적 입력을 하는 시스템에 맞게 설계된 공식이기 때문에, 각각의 패턴인식 모듈에 입력되는 정보를 '입력의 나열'로 간주하는 것이 적절한 또 다른 이유다. 소프트웨어 시스템에도 이 수학적 기법을 사용하고 있으며, 실제 뇌에서도 이 기법을 적용해 적정한 수치를 찾을 수 있다.
이 최적화 해법이 함축하는 중요한 의미는, 일상적으로 반복되는 경험은 유지된다고 해도 영구적인 기억을 만들어내지 못한다는 것이다. 산책을 하는 동안 모든 레벨에서 수백만 개의 패턴을 경험했다고 하자. 길을 걷는 동안 가로등, 병원, 편의점, 식물, 동물 등의 모양과 빛깔이 눈 속으로 들어왔다. 하지만 이렇게 경험한 것 중 어떤 것도 독특하지 않았으며, 이미 오래전에 리던던시 최적화 수준에 도달한 것들이었다. 더 이상 저장할 필요가 없는 정보들이었기 때문에, 산책에서 본 것들을 거의 기억하지 못하는 것이다. 그나마 기억하는 몇 가지 세부적이 정보 역시, 몇 번 더 산책을 하면 새로 획득할 패턴이 덮어쓸 것이다.
8-4. 개념적 수준에서는 동시에 여러 레벨에서 학습이 이루어지기는 힘들다.
'생물학적 신피질'은 물론 '그것을 모방하려고 하는 인공지능'에 모두 적용되는 사실은, 개념적 수준에서는 동시에 여러 레벨에서 학습이 이루어지기 힘들다는 것이다. 개념적 수준에서는 본질적으로 한 번에 1개, 많아야 2개 정도의 레벨에서만 학습이 가능하다. 그 학습이 어느 정도 안정화되고 난 다음에야 다른 레벨의 학습이 진행될 수 있다. 하위 레벨에서 학습된 내용이 지속적으로 미세하게 수정되는 와중에도 학습의 초점은 언제나 추상적인 레벨에 맞춰져 있다. 기초적인 모양을 인지하기 위해 씨름하는 갓난 아기나, 뇌의 작동 방식을 이해하기 위해 씨름하는 우리나, 복잡성의 레벨은 한 번에 하나씩만 학습된다. 신피질을 모방한 기계에서도 똑같은 현상이 나타난다 한 번에 하나의 레벨씩, 추상성을 계속 높여준다면, 마침내 기계도 인간과 같은 학습능력을 갖춘 날이 올 것이다.
반대로 패턴의 출력은 그 패턴 또는 하위레벨 패턴의 입력값이 될 수 있다. 자신의 출력값을 다시 입력값으로 삼는 이러한 '피드백루프(Feedback Loop)'는 인간의 뇌에 강력한 순환기능을 부여한다.
9. 생각의 방향성
생각은 작동 방식 측면에서 크게 '방향성 없는 생각'과 '방향성 있는 생각' 두 가지로 나눌 수 있다.
첫 번째는 '방향성 없는 생각'으로, 논리와 무관한 생각을 촉발하는 것이다. 예컨대 낙엽을 쓸거나 거리를 걷다가 몇 년 전의 기억이 문득 떠오르기도 한다. 하지만 이처럼 갑자기 떠오른 생각이라고 해도, 그것은 아무 관련성 없이 떠오른 것이 아니다. 이미 설명했듯이 모든 패턴은 언제나 손서대로 촉발되며, 기억 역시 그러한 과정을 거쳐 떠오른다. 따라서 과거의 어떤 장면이 눈앞에 갑자기 떠올랐다고 해도, 그 기억을 떠올리기 전부터 그 기억을 암시하는 어떤 '힌트'로부터 출발하여, 그 장면이 떠오를 때까지 우리 마음속에는 무수한 패턴의 촉발이 일어난 것이다. 기억을 촉발한 계기가 명확하게 인지될 수도 있지만, 어렴풋할 수도 있고, 전혀 인지하지 못할 수도 있다. 인지한다고 해도 연관성이 떨어지는 비선형적인 연상들일 가능성이 있다. 또한 장면을 떠올리기 위해서는 연상되는 연상되는 여러 기억을 종합하여, 좀 더 생생한 이미지를 만들어내야 한다. 뇌는 그림이나 소리를 그대로 저장하지 않기 때문이다. '명상'이나 '꿈'도 이러한 '방향성 없는 사고'에 기초한다.
두 번째는 '방향성 있는 생각'으로, 문제를 해결하거나 체계적인 반응을 형성하고자 할 때 우리가 의도적으로 촉발하는 것이다. 반면, 방향성이 있는 방식으로 생각이 활성화될 때는 좀 더 질서 있는 처리 과정을 통해 기억을 회상하거나 문제를 풀어나간다. 이런 생각은 신피질에 있는 리스트를 수행된다. 하지만 이러한 처리 과정에서 방향성 없이 스쳐가는 덜 구조화된 생각도 무수히 함께 발생한다. 결국, 우리 생각 속에 담긴 내용은 모두 무질서하게 존재한다. 어떤 문장을 쓸 것인지 마음속으로 구상하는 '방향성 있는 생각'을 하는 경우를 생각해 보자. 그런데 이런 생각도 곰곰이 분석해 보면, 우리가 원래부터 그러한 과업을 계층적인 구조로 쪼개어 생각한다는 것을 알 수 있다. 예컨대, 책을 쓰는 것은 장을 쓰는 것으로 이루어지고, 장은 단락으로 이루어지고, 단락은 문단으로 이루어지고, 문단은 문장으로 이루어지고, 문장은 아이디어로 이루어진다. 아이디어는 여러 요소의 결합으로 이루어지고, 요소와 요소들의 관계가 명확하게 표현되어야 아이디어는 성립한다.
9-1. 우리의 뇌는 언제나 사건의 인과관계를 설명하기 위해 이야기를 만들어낸다.
우리의 뇌는 언제나 사건의 인과관계를 설명하기 위해 이야기를 만들어낸다. 그 전형적인 사례를 보고 싶다면, 주식 방송을 틀어보면 안다. 주식 전문가라고 불리는 사람들은 시장이 어떻게 움직이든 그런 상황이 벌어진 이유를 그럴듯하게 설명해낸다. 물론 주식 해설가들이 정말 시장을 이해하고 있다며, 애초에 이렇게 해설하는 것 자체가 시간 낭비에 불과할 것이다.
이야기를 만들어내는 것 역시 신피질이 하는 일이다. 신피질은 특정한 제약에 부합하는 이야기와 설명을 찾아내는 데 뛰어난 소질을 발휘한다. 이러한 능력을 이야기를 전달할 때마다 유감없이 발휘된다. 기억이 나지 않는 세부사항이나 이야기를 만드는 데 활용할 수 없는 세부사항은 다른 요소로 채워 이야기를 더욱 그럴듯하게 만든다. 다양한 의도를 가진 새로운 화자들이 이야기를 거듭 전달할 때마다 이야기가 조금씩 바뀌는 것은 이 때문이다. 하지만 음성언어를 문자언어로 변환할 수 있게 되면서, 이 같은 이야기의 변형을 방지하고 고정된 판본을 기록할 수 있게 되었다.
10. '언어'의 계층적 속성
우리가 경험한 바를 더듬어보면, 어떤 생각과 기억이 무엇을 의미하는지 '알기는 해도' 그것을 말로 설명하기는 어렵다는 것을 알 수 있다. 자신의 생각과 기억을 다른 사람과 공유하고 싶다면, 우리는 그것을 언어로 옮겨야만 한다. 이러한 생각을 언어로 옮기는 임무 역시 '패턴인식기'가 수행한다.
언어 역시 본질적으로 계층적 구조물이지만, 신피질의 계층적 속성을 최대한 활용할 수 있는 방향으로 더욱 진화했다. 마침내 언어는 실재 세계의 계층적 속성을 반영할 수 있는 수준까지 도달했다. '노엄 촘스키(Noam Chomsky)'는 언어의 계층적 구조를 학습하는 능력을 인간이 선천적으로 타고났다고 주장했는데, 이것은 신피질의 구조와 일치한다. '노엄 촘스키'는 2002년 공동 집필한 논문에서' 순환'을 인간만이 가진 독특한 언어능력이라고 설명했다. '순환(Recursion)'이란 작은 부분을 모아 큰 덩어리를 만들어내고, 그 덩어리를 모아 다시 더 큰 덩어리를 만들어내는 것으로, 인간은 이러한 과정을 무한하게 반복할 수 있다. 바로 이러한 순환 능력 때문에 한정된 만으로도 문장이나 문단과 같은 정교한 구조를 무한하게 만들어낼 수 있는 것이다. 물론 촘스키는 뇌구조를 언급하지 않았지만, 그가 설명하는 '순환이라는 능력'은 '신피질의 능력'과 정확하게 일치한다.
인간을 제외한 포유류들은 생활 속에서 마주치는 난관을 헤쳐 나가는 데에 신피질의 기능을 거의 소진한다. 하지만 그들과 달리 피질을 계속 확장시켜온 인간은, 마침내 음성언어와 문자언어를 만들어낼 수 있는 단계까지 발전했다. 그리고 이런 발명품들을 활용하기 시작하면서 신피질의 능력은 또 한 번 폭발적으로 진화했다.
11. 인공지능 모형 설계
11-1. 계층적 은닉 마르코프 모델(HHMM)
1980년대와 1990년대에 '레이 커즈와일(Ray Kurzweil)'과 연구진들은 이러한 파라미터들을 학습한 다음, 이를 이용해 계층적 패턴을 패턴을 인식하기 위한 '계층적 은닉 마르코프 모델(HHMM: Hierarchical Hidden Markov Model)'이라는 수학모형을 개발했다. 이 기법은 오늘날 보편화된 말소리를 인식하고 이해하는 '음성인식 시스템'의 기반이 된 기술이다. 예컨대 아이폰의 '시리(Siri)', 구글의 보이스 서치, 음성 인식 자동차 내비게이션 등에 이 '음성인식 시스템'이 이용됐다.
'레이커즈 와일'과 연구진들이 개발한 HHMM 기법은 지금까지 설명한 '패턴인식 마음 이론(Pattern Recognition Theory of Mind)'의 특성을 알고리즘으로 거의 구현해낸 것이다. 상위 레벨이 하위 레벨보다 개념적으로 더 추상적이라는 패턴의 계층구조도 그대로 반영되어 설계되었다. 예컨대 음성인식의 경우, 최하위 레벨에서는 음성주파수의 기본적인 패턴을 인식하고, 그다음 레벨에서는 음소를 인식하고, 그다음 레벨에서는 단어와 단어 뭉치를 인식된다. 그리고 더 높은 레벨에서는 명사와 동사로 이루어진 문장구조를 인식할 수 있었고, 이로써 연구진들이 개발한 몇몇 음성 시스템은 자연어로 된 명령의 의미를 이해할 수 있었다. 패턴인식 모듈은 제각각 개념적 하위 레벨에서부터 연속적으로 입력되는 패턴을 인식할 수 있었다. 입력마다 '패턴의 가중치', '크기', '크기의 가변성'을 표시하는 파라미터가 코딩되어 있었다. 하위 레벨 패턴이 예측될 때에는 그 사실을 전달하는 '하향 신호'도 있다.
11-2. 계층적 시간 메모리(HTM)
2003년과 2004년, 최초로 사용화된 'PDA 팜파일럿(PDA PalmPilot)'을 개발한 '제프 호킨스(Jeff Hawkins, 1957~)'와 '딜립 조지(Dileep George)'는 '계층적 시간 메모리(HTM: Hierarchical Temporal Memory)'라는 '계층적 피질 모형'을 개발했다. 과학 저술가 '샌드라 블레이크슬리(Sandra Blakeslee)'와 함께 저술한 '생각하는 뇌, 생각하는 기계(On Intelligence: How a New Understanding of the Brain will Lead to the Creation of Truly Intelligent Machines)'에서 '제프 호킨스'는 이 모형을 유려하게 설명한다. 그는 피질 알고리즘의 균일성과, 계층적이고 리스트에 기반을 둔 구조에 관한 강력한 사례를 제공한다.
11-3. HHMM과 HTM의 차이
하지만 '계층적 시간 메모리(HTM: Hierarchical Temporal Memory)'과 '계층적 은닉 마르코프 모델(HHMM: Hierarchical Hidden Markov Model)' 사이에는 중요한 차이가 있다.
모형의 이름에서도 알 수 있듯이 '계층적 시간 메모리(HTM: Hierarchical Temporal Memory)'에서는 시간적 속성을 속성을 강조한다. 다시 말해 이 모형에서 리스트는 언제나 시간 순으로 배열된다. 예컨대 A와 같은 2차원적 공간 이미지도 시간적 특성으로 인지된다고 설명하는데, 한 마디로 이미지를 인식할 때 우리도 알지 못하는 사이에 눈의 순차적인 움직임을 통해 이미지가 시각화된다는 뜻이다. 따라서 HTM 모형에서 신피질에 도달하는 정보는 2차원적인 특성의 집합이 아니라, 시간 순으로 나열된 리스트다.
물론 우리 눈이 매우 빠르게 움직이는 것은 분명하지만, A라는 글자를 인식하는 사건이 시간 순으로 발생하는 것은 아니다. 더욱이 우리는 0.000x초 동안 나타났다 사라지는 시각적 패턴도 인식할 수 있는데, 아무리 눈동자의 움직임이 빠르다고 해도 차례대로 훑어보기에는 너무나 짧은 시간이다. 신피질의 패턴인식기가 패턴을 리스트로 저장하고, 그 리스트가 순서대로 나열되어 있는 것은 사실이지만, 그 순서가 꼭 시간만을 의미하는 것은 아니다. 리스트가 시간 순으로 정리되는 경우도 있지만, 공간적인 순서로 정리되는 경우도 있고, 상위 레벨의 경우에는 개념적 순서에 따라 정리되는 경우도 있다.
HTM과 HHMM의 가장 중요한 차이는 패턴인식 모듈에 들어가는 입력마다 포함되는 '파라미터(Parameter)' 이다. 특히 '크기 파라미터'와 '크기 가변성 파라미터'이다. 실제로 처음에는 이러한 파라미터를 코딩하지 않고, 인간의 음성을 인식하려고 했다. 기술 개발을 위해 초빙한 언어학자가 음이 지속되는 시간은 음성을 인식하는 데 특별히 중요하지는 않다고 이야기했기 때문이다. 그래서 각 단어의 발음을 음소의 나열로만 정리했다. 예컨대 'streep'라는 단어는 각 음소의 지속시간을 전혀 표시하지 않고, [s] [t] [E] [p]로만 표시했다. 인간의 말소리에서 이 4가지 음소의 나열과 마주치면, 음성인식 시스템은 'steep'이라는 단어를 인식할 수 있다는 뜻이다. 하지만 이러한 접근 방식을 토대로 구축한 시스템은 어느 정도까지만 작동했다. 인식해야 할 어휘수가 많아질수록, 발화자가 많아질수록 인식률은 떨어졌다. 또한 사람이 여러 단어를 쉬지 않고 붙여서 이야기할 때 인식률은 더 떨어졌다. 하지만 HHMM 기법을 적용하여 입력마다 좀 더 미세한 변수를 코딩해 넣을 수 있도록 하자, 시스템의 성능이 크게 향상되었다.